
Today, companies of all sizes across all verticals design and build event-driven architectures centered around real-time streaming and stream processing. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that makes it easy for you to build and run applications that use Apache Kafka to process streaming and event data.
Source: Power your Kafka Streams application with Amazon MSK and AWS Fargate
Apache Kafka is an open-source platform for building real-time streaming data pipelines and applications. With Amazon MSK, you can continue to use native Apache Kafka APIs to build event-driven architectures, stream changes to and from databases, and power machine learning and analytics applications.
You can apply streaming in a wide range of industries and organizations, such as to capture and analyze data from IoT devices, track and monitor vehicles or shipments, monitor patients in medical facilities, or monitor financial transactions.
In this post, we walk through how to build a real-time stream processing application using Amazon MSK, AWS Fargate, and the Apache Kafka Streams API. The Kafka Streams API is a client library that simplifies development of stream applications. Behind the scenes, Kafka Streams library is really an abstraction over the standard Kafka Producer and Kafka Consumer API. When you build applications with the Kafka Streams library, your data streams are automatically made fault tolerant, and are transparently and elastically distributed over the instances of the applications. Kafka Streams applications are supported by Amazon MSK. Fargate is a serverless compute engine for containers that works with AWS container orchestration services like Amazon Elastic Container Service (Amazon ECS), which allows you to easily run, scale, and secure containerized applications.
We have chosen to run our Kafka Streams application on Fargate, because Fargate makes it easy for you to focus on building your applications. Fargate removes the need to provision and manage servers, lets you specify and pay for resources per application, and improves security through application isolation by design. Fargate allocates the right amount of compute, eliminating the need to choose instances and scale cluster capacity. You only pay for the resources required to run your containers, so there is no over-provisioning and paying for additional servers. Fargate runs each task or pod in its own kernel providing the tasks and pods their own isolated compute environment. This enables your application to have workload isolation and improved security by design.
Architecture overview
Our streaming application architecture consists of a stream producer, which connects to the Twitter Stream API, reads tweets, and publishes them to Amazon MSK. A Kafka Streams processor consumes these messages, performs window aggregation, pushes to topic result, and prints out to logs. Both apps are hosted on Fargate.

The stream producer application connects to the Twitter API (a stream of sample tweets), reads the stream of tweets, extracts only hashtags, and publishes them to the MSK topic. The following is a code snippet from the application:
var configs = new AppConfig();
var kafkaService = new KafkaService(configs.kafkaProducer());
var twitterService = new TwitterService(kafkaService, configs.httpClient());
if (null != BEARER_TOKEN) {
twitterService.connectStream(BEARER_TOKEN);
} else {
LOG.error(
"There was a problem getting you bearer token. Please make sure you set the BEARER_TOKEN environment variable");
}The MSK cluster is spread across three Availability Zones, with one broker per Availability Zone. We use the AWS-recommended (as of this writing) version of Apache Kafka 2.6.1. Apache Kafka topics have a replication factor and partitions of three, to take advantage of parallelism and resiliency.
The logic of our consumer streaming app is as follows; it counts the number of Twitter hashtags, with a minimum length of 1, that have been mentioned more than four times in a 20-second window:
private static final TimeWindows WINDOW_20_SEC = of(ofSeconds(20)).grace(ofMillis(0));
private static final int MIN_MENTIONED_IN_WINDOW = 4;
private static final int MIN_CHAR_LENGTH = 1;
…
var tweetStream =
paragraphStream
.filter(
(k, v) -> v.length() > MIN_CHAR_LENGTH) // filter hashtags with length less 1 char
.mapValues((ValueMapper<String, String>) String::toLowerCase) // lowercase hashtags
.mapValues(String::trim) // remove leading and trailing spaces
.selectKey((k, v) -> v) // select hashtag as a key
.groupByKey()
.windowedBy(WINDOW_20_SEC) // apply 20 seconds window aggregation
.count(with(String(), Long())) // count hashtags, materialized in state store as String & Long
.suppress(untilWindowCloses(unbounded())) // suppression will emit only the "final results", buffer unconstrained by size(not recommended for prod)
.toStream()
.map((k, v) -> new KeyValue<>(k.key(), v))
.filter(
(k, v) -> v > MIN_MENTIONED_IN_WINDOW); // filter hashtags mentioned less than 4 timesPrerequisites
Make sure to complete the following steps as prerequisites:
- Create an AWS account. For this post, you configure the required AWS resources in the
us-east-1orus-west-2Region. If you haven’t signed up, complete the following tasks:- Create an account. For instructions, see Sign Up for AWS.
- Create an AWS Identity and Access Management (IAM) user. For instructions, see Create an IAM User.
- Have a Bearer Token associated with your Twitter app. To create a developer account, see Get started with the Twitter developer platform.
- Install Docker on your local machine.
Solution overview
To implement this solution, we complete the following steps:
- Set up an MSK cluster and Amazon Elastic Container Registry (Amazon ECR).
- Build and upload application JAR files to Amazon ECR.
- Create an ECS cluster with a Fargate task and service definitions.
- Run our streaming application.
Set up an MSK cluster and Amazon ECR
Use the provided AWS CloudFormation template to create the VPC (with other required network components), security groups, MSK cluster with required Kafka topics (twitter_input and twitter_output), and two Amazon ECR repositories, one per each application.
Build and upload application JAR files to Amazon ECR

- CRISP DETAIL, CLEAR DISPLAY: Enjoy binge-watching...
- PRO SHOTS WITH EASE: Brilliant sunrises, awesome...
- CHARGE UP AND CHARGE ON: Always be ready for an...
- POWERFUL 5G PERFORMANCE: Do what you love most —...
- NEW LOOK, ADDED DURABILITY: Galaxy A54 5G is...

- Free 6 months of Google One and 3 months of...
- Pure Performance: The OnePlus 12 is powered by the...
- Brilliant Display: The OnePlus 12 has a stunning...
- Powered by Trinity Engine: The OnePlus 12's...
- Powerful, Versatile Camera: Explore the new 4th...
Last update on 2024-04-05 / Affiliate links / Images from Amazon Product Advertising API
To build and upload the JAR files to Amazon ECR, complete the following steps:
- Download the application code from the GitHub repo.
- Build the applications by running the following command in the root of the project:
./gradlew clean build- Create your Docker images (
kafka-streams-mskandtwitter-stream-producer):
docker-compose build- Retrieve an authentication token and authenticate your Docker client to your registry. Use the following AWS Command Line Interface (AWS CLI) code:
aws ecr get-login-password --region <<region>> | docker login --username AWS --password-stdin <<account_id>>.dkr.ecr.<<region>>.amazonaws.com- Tag and push your images to the Amazon ECR repository:
docker tag kafka-streams-msk:latest <<account_id>>.dkr.ecr.<<region>>.amazonaws.com/kafka-streams-msk:latest
docker tag twitter-stream-producer:latest <<account_id>>.dkr.ecr.<<region>>.amazonaws.com/twitter-stream-producer:latest- Run the following command to push images to your Amazon ECR repositories:
docker push <<account_id>>.dkr.ecr.<<region>>.amazonaws.com/kafka-streams-msk:latest
docker push <<account_id>>.dkr.ecr.<<region>>.amazonaws.com/twitter-stream-producer:latestNow you should see images in your Amazon ECR repository (see the following screenshot).
Create an ECS cluster with a Fargate task and service definitions
Use the provided CloudFormation template to create your ECS cluster, Fargate task, and service definitions. Make sure to have Twitter API Bearer Token ready.
Run the streaming application
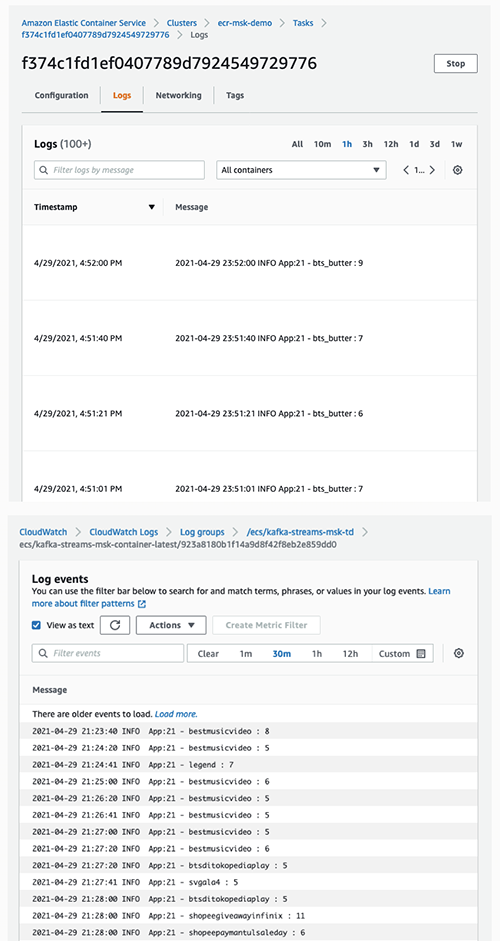
When the CloudFormation stack is complete, it automatically deploys your applications. After approximately 10 minutes, all your apps should be up and running, aggregating, and producing results. You can see the result in Amazon CloudWatch logs or by navigating to the Logs tab of the Fargate task.
Improvements, considerations, and best practices
Consider the following when implementing this solution:
- Fargate enables you to run and maintain a specified number of instances of a task definition simultaneously in a cluster. If any of your tasks should fail or stop for any reason, the Fargate scheduler launches another instance of your task definition to replace it in order to maintain the desired number of tasks in the service. Fargate is not recommended for workloads requiring privileged Docker permissions or workloads requiring more than 4v CPU or 30 Gb of memory (consider whether you can break up your workload into more, smaller containers that each use fewer resources).
- Kafka Streams resiliency and availability is provided by state stores. These state stores can either be an in-memory hash map (as used in this post), or another convenient data structure (for example, a RocksDB database that is production recommended). The Kafka Streams application may embed more than one local state store that can be accessed via APIs to store and query data required for processing. In addition, Kafka Streams makes sure that the local state stores are robust to failures. For each state store, it maintains a replicated changelog Kafka topic in which it tracks any state updates. If your app restarts after a crash, it replays the changelog Kafka topic and recreates an in-memory state store.
- The AWS Glue Schema Registry is out of scope for this post, but should be considered in order to centrally discover, validate, and control the evolution of streaming data using registered Apache Avro schemas. Some of the benefits that come with it are data policy enforcement, data discovery, controlled schema evolution, and fault-tolerant streaming (data) pipelines.
- To improve availability, enable three (the maximum as of this writing) Availability Zone replications within a Region. Amazon MSK continuously monitors cluster health, and if a component fails, Amazon MSK automatically replaces it.
- When you enable three Availability Zones your MSK cluster, you not only improve availability, but also improve cluster performance. You spread the load between a larger number of brokers, and can add more partitions per topic.
- We highly encourage you to enable encryption at rest, TLS encryption in transit (client-to-broker, broker-to-broker), TLS based certificate authentication, and SASL/SCRAM authentication, which can be secured by AWS Secrets Manager.
Clean up

- 【Octa-Core CPU + 128GB Expandable TF Card】...
- 【6.8 HD+ Android 13.0】 This is an Android Cell...
- 【Dual SIM and Global Band 5G Phone】The machine...
- 【6800mAh Long lasting battery】With the 6800mAh...
- 【Business Services】The main additional...

- 【Dimensity 9000 CPU + 128GB Expandable TF...
- 【6.8 HD+ Android 13.0】 This is an Android Cell...
- 【Dual SIM and Global Band 5G Phone】Dual SIM &...
- 【6800mAh Long lasting battery】The I15 Pro MAX...
- 【Business Services】The main additional...

- 🥇【6.8" HD Unlocked Android Phones】Please...
- 💗【Octa-Core CPU+ 256GB Storage】U24 Ultra...
- 💗【Support Global Band 5G Dual SIM】U24 Ultra...
- 💗【80MP Professional Photography】The U24...
- 💗【6800mAh Long Lasting Battery】With the...
Last update on 2024-04-05 / Affiliate links / Images from Amazon Product Advertising API
To clean up your resources, delete the CloudFormation stacks that you launched as part of this post. You can delete these resources via the AWS CloudFormation console or via the AWS Command Line Interface (AWS CLI).
Conclusion
In this post, we demonstrated how to build a scalable and resilient real-time stream processing application. We build the solution using the Kafka Streams API, Amazon MSK, and Fargate. We also discussed improvements, considerations, and best practices. You can use this architecture as a reference in your migrations or new workloads. Try it out and share your experience in the comments!
About the Author
Karen Grygoryan, Data Architect, AWS ProServe