
When planning multitenant storage or data components, you need to decide on an approach for sharing or isolating your tenants' data. Data is often considered the most valuable part of a solution, since it represents your or your customers' valuable business information.
Source: Architectural approaches for storage and data
So, it's important to carefully plan the approach you use to manage data in a multitenant environment. On this page, we provide guidance about the key considerations and requirements to consider when deciding on an approach to store data in a multitenant system. We then suggest some common patterns for applying multitenancy to storage and data services, and some antipatterns to avoid. Finally, we provide targeted guidance for some specific situations.
Key considerations and requirements
It's important to consider the approaches you use for storage and data services from a number of perspectives, which approximately align to the pillars of the Azure Well-Architected Framework.
Scale
When working with services that store your data, you should consider the number of tenants you have, and the volume of data you store. If you have a small number of tenants (such as five or less), and you're storing small amounts of data for each tenant, then it's likely to be a wasted effort to plan a highly scalable data storage approach, or to build a fully automated approach to manage your data resources. As you grow, you will increasingly benefit from having a clear strategy to scale your data and storage resources, and to apply automation to their management. When you have 50 tenants or more, or if you plan to reach that level of scale, then it's especially important to design your data and storage approach, with scale as a key consideration.
Consider the extent to which you plan to scale, and clearly plan your data storage architectural approach to meet that level of scale.
Performance predictability
Multitenant data and storage services are particularly susceptible to the Noisy Neighbor problem. It's important to consider whether your tenants could affect each other's performance. For example, do your tenants have overlapping peaks in their usage patterns over time? Do all of your customers use your solution at the same time each day, or are requests distributed evenly? Those factors will impact the level of isolation you need to design for, the amount of resources you need to provision, and the degree to which resources can be shared between tenants.
It's important to consider Azure's resource and request quotas as part of this decision. For example, suppose you deploy a single storage account to contain all of your tenants' data. If you exceed a specific number of storage operations per second, Azure Storage will reject your application's requests, and all of your tenants will be impacted. This is called throttling behavior. It's important that you monitor for throttled requests. See Retry guidance for Azure services for further information.
Data isolation
When designing a solution that contains multitenant data services, there are usually different options and levels of data isolation, each with their own benefits and tradeoffs. For example:
- When using Azure Cosmos DB, you can deploy separate containers for each tenant, and you can share databases and accounts between multiple tenants. Alternatively, you might consider deploying different databases or even accounts for each tenant, depending on the level of isolation required.
- When using Azure Storage for blob data, you can deploy separate blob containers for each tenant, or you can deploy separate storage accounts.
- When using Azure SQL, you can use separate tables in shared databases, or you can deploy separate databases or servers for each tenant.
- In all Azure services, you can consider deploying resources within a single shared Azure subscription, or you can use multiple Azure subscriptions–perhaps even one per tenant.
There is no single solution that works for every situation. The option you choose depends on a number of factors and the requirements of your tenants. For example, if your tenants need to meet specific compliance or regulatory standards, you might need to apply a higher level of isolation. Similarly, you might have commercial requirements to physically isolate your customers' data, or you might need to enforce isolation to avoid the Noisy Neighbor problem. Additionally, if tenants need to use their own encryption keys, they have individual backup and restore policies, or they need to have their data stored in different geographical locations, you might need to isolate them from other tenants, or group them with tenants that have similar policies.
Complexity of implementation
It's important to consider the complexity of your implementation. It's good practice to keep your architecture as simple as possible, while still meeting your requirements. Avoid committing to an architecture that will become increasingly complex as you scale, or an architecture that you don't have the resources or expertise to develop and maintain.
Similarly, if your solution doesn't need to scale to a large number of tenants, or if you don't have concerns around performance or data isolation, then it's better to keep your solution simple and avoid adding unnecessary complexity.
A particular concern for multitenant data solutions is the level of customization you support. For example, can a tenant extend your data model or apply custom data rules? Ensure you design for this upfront. Avoid forking or providing custom infrastructure for individual tenants, since this inhibits your ability to scale, to test your solution, and to deploy updates. Instead, consider using feature flags and other forms of tenant configuration.
Complexity of management and operations
Consider how you plan to operate your solution, and how your multitenancy approach affects your operations and processes. For example:
- Consider cross-tenant management operations, such as regular maintenance activities. If you use multiple accounts, servers, or databases, how will you initiate and monitor the operations for each tenant?
- If you monitor or meter your tenants, consider how your solution reports metrics, and whether they can be easily linked to the tenant that triggered the request.
- Reporting data from across isolated tenants may require that each tenant publishes data to a centralized data warehouse, rather than running queries on each database individually and then aggregating the results.
- If you use a database that enforces a schema, plan how you will deploy schema updates across your estate. Consider how your application knows which schema version to use for a specific tenant's database queries.
- Consider your tenants' high availability requirements (for example, uptime service level agreements, or SLAs) and disaster recovery requirements (for example, recovery time objectives, or RTOs, and recovery point objectives, or RPOs). If tenants have different expectations, will you be able to meet each tenant's requirements?
- How will you migrate tenants if they need to move to a different type of service, a different deployment, or another region?
Cost
Generally, the higher the density of tenants to your deployment infrastructure, the lower the cost to provision that infrastructure. However, shared infrastructure increases the likelihood of issues like the Noisy Neighbor problem, so consider the tradeoffs carefully.
Patterns to consider
Several design patterns from the Azure Architecture Center are of relevance to mulitenant storage and data services. You might choose to follow one pattern consistently. Or, you could consider mixing and matching patterns. For example, you might use a multitenant database for most of your tenants, but deploy single-tenant stamps for tenants who pay more or who have unusual requirements. Similarly, it's often a good practice to scale by using deployment stamps, even when you use a multitenant database or sharded databases within a stamp.
Deployment Stamps pattern
The Original Postatterns/deployment-stamp" target="_blank" rel="noreferrer noopener">Deployment Stamps pattern involves deploying dedicated infrastructure for a tenant or group of tenants. A single stamp might contain multiple tenants or might be dedicated to a single tenant.
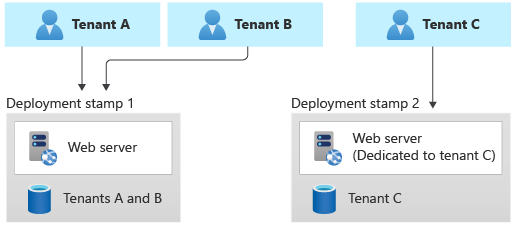
When using single-tenant stamps, the Deployment Stamps pattern tends to be straightforward to implement, because each stamp is likely to be unaware of any other, so no multitenancy logic or capabilities need to be built into the application layer. When each tenant has their own dedicated stamp, this pattern provides the highest degree of isolation, and it mitigates the Noisy Neighbor problem. It also provides the option for tenants to be configured or customized according to their own requirements, such as to be located in a specific geopolitical region or to have specific high availability requirements.
When using multitenant stamps, other patterns need to be considered to manage multitenancy within the stamp, and the Noisy Neighbor problem still might apply. However, by using the Deployment Stamps pattern, you can ensure that you can continue to scale as your solution grows.
The biggest problem with the Deployment Stamps pattern, when being used to serve a single tenant, tends to be the cost of the infrastructure. When using single-tenant stamps, each stamp needs to have its own separate set of infrastructure, which isn't shared with other tenants. You also need to ensure that the resources deployed for a stamp are sufficient to meet the peak load for that tenant's workload. Ensure that your pricing model offsets the cost of deployment for the tenant's infrastructure.
Single-tenant stamps often work well when you have a small number of tenants. As your number of tenants grows, it's possible but increasingly difficult to manage a fleet of stamps (see this case study as an example). You can also apply the Deployment Stamps pattern to create a fleet of multitenant stamps, which can provide benefits for resource and cost sharing.
To implement the Deployment Stamps pattern, it's important to use automated deployment approaches. Depending on your deployment strategy, you might consider managing your stamps within your deployment pipelines, by using declarative infrastructure as code, such as Bicep, ARM templates, or Terraform templates. Alternatively, you might consider building custom code to deploy and manage each stamp, such as by using the Azure SDKs.
Shared multitenant databases and file stores
You might consider deploying a shared multitenant database, storage account, or file share, and sharing it across all of your tenants.
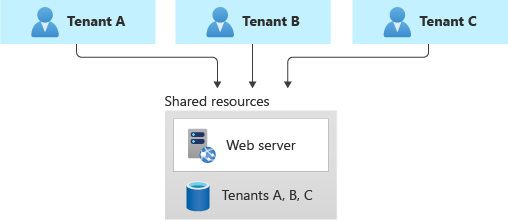
This approach provides the highest density of tenants to infrastructure, so it tends to come at the lowest cost of any approach. It also often reduces the management overhead, since there's a single database or resource to manage, back up, and secure.
However, when you work with shared infrastructure, there are several caveats to consider:
- When you rely on a single resource, consider the supported scale and limits of that resource. For example, the maximum size of one database or file store, or the maximum throughput limits, will eventually become a hard blocker, if your architecture relies on a single database. Carefully consider the maximum scale you need to achieve, and compare it to your current and future limits, before you select this pattern.
- The Noisy Neighbor problem might become a factor, especially if you have tenants that are particularly busy or generate higher workloads than others. Considering applying the Throttling pattern or the Rate Limiting pattern to mitigate these effects.
- You might have difficulty monitoring the activity and measuring the consumption for a single tenant. Some services, such as Azure Cosmos DB, provide reporting on resource usage for each request, so this information can be tracked to measure the consumption for each tenant. Other services don't provide the same level of detail. For example, the Azure Files metrics for file capacity are available per file share dimension, only when you use premium shares. However, the standard tier provides the metrics only at the storage account level.
- Tenants may have different requirements for security, backup, availability, or storage location. If these don't match your single resource's configuration, you might not be able to accommodate them.
- When working with a relational database, or another situation where the schema of the data is important, then tenant-level schema customization is difficult.
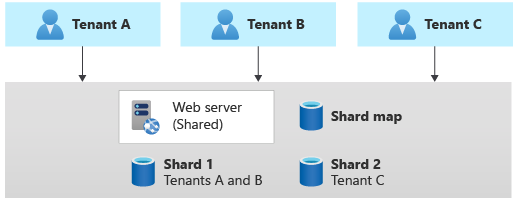
Sharding pattern

- Purposeful Design: Travel with ease and look great...
- Ready-to-Go Performance: The Aspire 3 is...
- Visibly Stunning: Experience sharp details and...
- Internal Specifications: 8GB LPDDR5 Onboard...
- The HD front-facing camera uses Acer’s TNR...

- 【14" HD Display】14.0-inch diagonal, HD (1366 x...
- 【Processor & Graphics】Intel Celeron N4120, 4...
- 【RAM & Storage】8GB high-bandwidth DDR4 Memory...
- 【Ports】1 x USB 3.1 Type-C ports, 2 x USB 3.1...
- 【Windows 11 Home in S mode】You may switch to...
Last update on 2024-04-05 / Affiliate links / Images from Amazon Product Advertising API
The Sharding pattern involves deploying multiple separate databases, called shards, that contain one or more tenants' data. Unlike deployment stamps, shards don't imply that the entire infrastructure is duplicated. You might shard databases without also duplicating or sharding other infrastructure in your solution.
Sharding is closely related to partitioning, and the terms are often used interchangeably. Consider the Horizontal, vertical, and functional data partitioning guidance.
The Sharding pattern can scale to very large numbers of tenants. Additionally, depending on your workload, you might be able to achieve a high density of tenants to shards, so the cost can be attractive. The Sharding pattern can also be used to address Azure subscription and service quotas, limits and constraints.
Some data stores, such as Azure Cosmos DB, provide native support for sharding or partitioning. When working with other solutions, such as Azure SQL, it can be more complex to build a sharding infrastructure and to route requests to the correct shard, for a given tenant.
Multitenant app with dedicated databases for each tenant
Another common approach is to deploy a single multitenant application, with dedicated databases for each tenant.
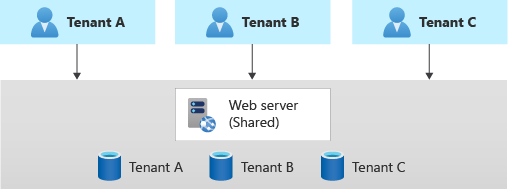
In this model, each tenant's data is isolated from the others, and you might be able to support some degree of customization for each tenant.
Because you provision dedicated data resources for each tenant, the cost for this approach can be higher than shared hosting models. However, Azure provides several options you can consider, in order to share the cost of hosting individual data resources across multiple tenants. These options include Azure SQL elastic pools and Azure Cosmos DB database throughput. Additionally, because only the data components are deployed individually for each tenant, you likely can achieve high density for the other components in your solution and reduce the cost of those components.
It's important to use automated deployment approaches, when you provision databases for each tenant.
Geodes pattern
The Geode pattern is designed specifically for geographically distributed solutions, including multitenant solutions. It supports high load and high levels of resiliency. When working with the Geode pattern, the data tier must be able to replicate the data across geographic regions, and it should support multi-geography writes.
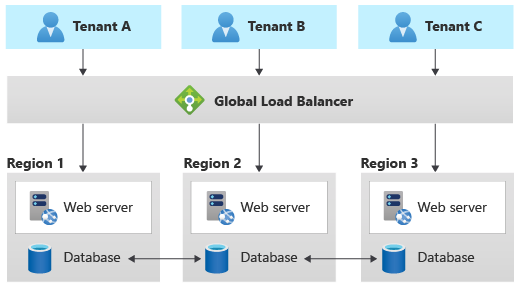
Azure Cosmos DB provides multi-master writes to support this pattern, and Cassandra supports multi-region clusters. Other data services are generally not able to support this pattern, without significant customization.
Antipatterns to avoid
When working with multitenant data services, it's important to avoid situations that inhibit your ability to scale.
For relational databases, these include:
- Table-based isolation. When you work within a single database, avoid creating individual tables for each tenant. A single database won't be able to support very large numbers of tenants when you use this approach, and it becomes increasingly difficult to query, manage, and update data. Instead, consider using a single set of multitenant tables with a tenant identifier column. Alternatively, you can use one of the patterns described above to deploy separate databases for each tenant.
- Column-level tenant customization. Avoid applying schema updates that only apply to a single tenant. For example, suppose you have a single multitenant database. Avoid adding a new column to meet a specific tenant's requirements. It might be acceptable for a small number of customizations, but this rapidly becomes unmanageable when you have a large number of customizations to consider. Instead, consider revising your data model to track custom data for each tenant in a dedicated table.
- Manual schema changes. Avoid updating your database schema manually, even if you only have a single shared database. It's easy to lose track of the updates you've applied, and if you need to scale out to more databases, it's challenging to identify the correct schema to apply. Instead, build an automated pipeline to deploy your schema changes, and use it consistently. Track the schema version used for each tenant in a dedicated database or lookup table.
- Version dependencies. Avoid having your application take a dependency on a single version of your database schema. As you scale, you may need to apply schema updates at different times for different tenants. Instead, ensure your application version is backwards-compatible with at least one schema version, and avoid destructive schema updates.
Databases
There are some features that can be useful for multitenancy. However, these aren't available in all database services. Consider whether you need these, when you decide on the service to use for your scenario:
- Row-level security can provide security isolation for specific tenants' data in a shared multitenant database. This feature is available in Azure SQL and Postgres Flex, but it's not available in other databases, like MySQL or Azure Cosmos DB.
- Tenant-level encryption might be required to support tenants that provide their own encryption keys for their data. This feature is available in Azure SQL as part of Always Encrypted. Cosmos DB provides customer-managed keys at the account level and also supports Always Encrypted.
- Resource pooling provides the ability to share resources and cost, between multiple databases or containers. This feature is available in Azure SQL's elastic pools and managed instances and in Azure Cosmos DB's database throughput.
- Sharding and partitioning has stronger native support in some services than others. This feature is available in Azure Cosmos DB, by using its logical and physical partitioning, and in Postgres Hyperscale. While Azure SQL doesn't natively support sharding, it provides sharding tools to support this type of architecture.

- EFFICIENT PERFORMANCE: Equipped with 4GB...
- Powerful configuration: Equipped with the Intel...
- LIGHTWEIGHT AND ADVANCED - The slim case weighs...
- Multifunctional interface: fast connection with...
- Worry-free customer service: from date of...

- Powered by an Intel Core i5 13th Gen 13420H 1.5GHz...
- Equipped with an NVIDIA GeForce RTX 3050 6GB GDDR6...
- Includes 8GB of DDR4-3200 RAM for smooth...
- Features a spacious 512GB Solid State Drive for...
- Boasts a vibrant 15.6" FHD IPS Micro-Edge...

- Processor - Powered by 11 Gen i5-1145G7 Processor...
- Memory and Storage - Equipped with 16GB of...
- FHD Display - 15.6 inch (1920 x 1080) FHD display,...
- FEATURES - Intel Iris Xe Graphics – Audio by...
- Convenience & Warranty: 2 x Thunderbolt 4 with...
Last update on 2024-04-05 / Affiliate links / Images from Amazon Product Advertising API
Additionally, when working with relational databases or other schema-based databases, consider where the schema upgrade process should be triggered, when you maintain a fleet of databases. In a small estate of databases, you might consider using a deployment pipeline to deploy schema changes. As you grow, it might be better for your application tier to detect the schema version for a specific database and to initiate the upgrade process.
File and blob storage
Consider the approach you use to isolate data within a storage account. For example, you might deploy separate storage accounts for each tenant, or you might share storage accounts and deploy individual containers. Alternatively, you might create shared blob containers, and then you can use the blob path to separate data for each tenant. Consider Azure subscription limits and quotas, and carefully plan your growth to ensure your Azure resources scale to support your future needs.
If you use shared containers, plan your authentication and authorization strategy carefully, to ensure that tenants can't access each other's data. Consider the Valet Key pattern, when you provide clients with access to Azure Storage resources.
Cost allocation
Consider how you'll measure consumption and allocate costs to tenants, for the use of shared data services. Whenever possible, aim to use built-in metrics instead of calculating your own. However, with shared infrastructure, it becomes hard to split telemetry for individual tenants. Application-level custom metering needs to be considered.
In general, cloud-native services, like Azure Cosmos DB and Azure Blob Storage, provide more granular metrics to track and model the usage for a specific tenant. For example, Azure Cosmos DB provides the consumed throughput for every request and response.