
Traditional data warehouses work well when we're dealing with batch jobs to load data. But in today's world, we see many use cases where the customers can't wait for a batch job to complete for our data scientists, analysts, or dashboards to access the data.
Source: High throughput stream ingestion to Azure Synapse
Today, more customers require real-time representations of their business in their data warehouse. This requirement goes beyond traditional batch jobs and needs the support for stream ingestion to their data warehouses.
Azure Synapse Analytics seamlessly supports both enterprise data warehousing and big data analytics workloads. Azure Stream Analytics is a serverless stream processing PaaS service that can scale with customer's needs. This example architecture will show how you can use an Azure Stream Analytics job to ingest stream to an Azure Synapse Analytics dedicated SQL pool.
Potential use cases

- Function Test: Only printer printheads that have...
- Stable Performance: With stable printing...
- Durable ABS Material: Our printheads are made of...
- Easy Installation: No complicated assembly...
- Wide Compatibility: Our print head replacement is...
![United States Travel Map Pin Board | USA Wall Map on Canvas (43 x 30) [office_product]](https://m.media-amazon.com/images/I/41O4V0OAqYL._SL160_.jpg)
- PIN YOUR ADVENTURES: Turn your travels into wall...
- MADE FOR TRAVELERS: USA push pin travel map...
- DISPLAY AS WALL ART: Becoming a focal point of any...
- OUTSTANDING QUALITY: We guarantee the long-lasting...
- INCLUDED: Every sustainable US map with pins comes...
Several scenarios can benefit from this architecture:
- Ingest data from a stream to a data warehouse in near real time.
- Apply different stream processing techniques (JOINs, temporal aggregations, filtering, anomaly detection, and so on) to transform the data. Then, store the result in the data warehouse.
Architecture
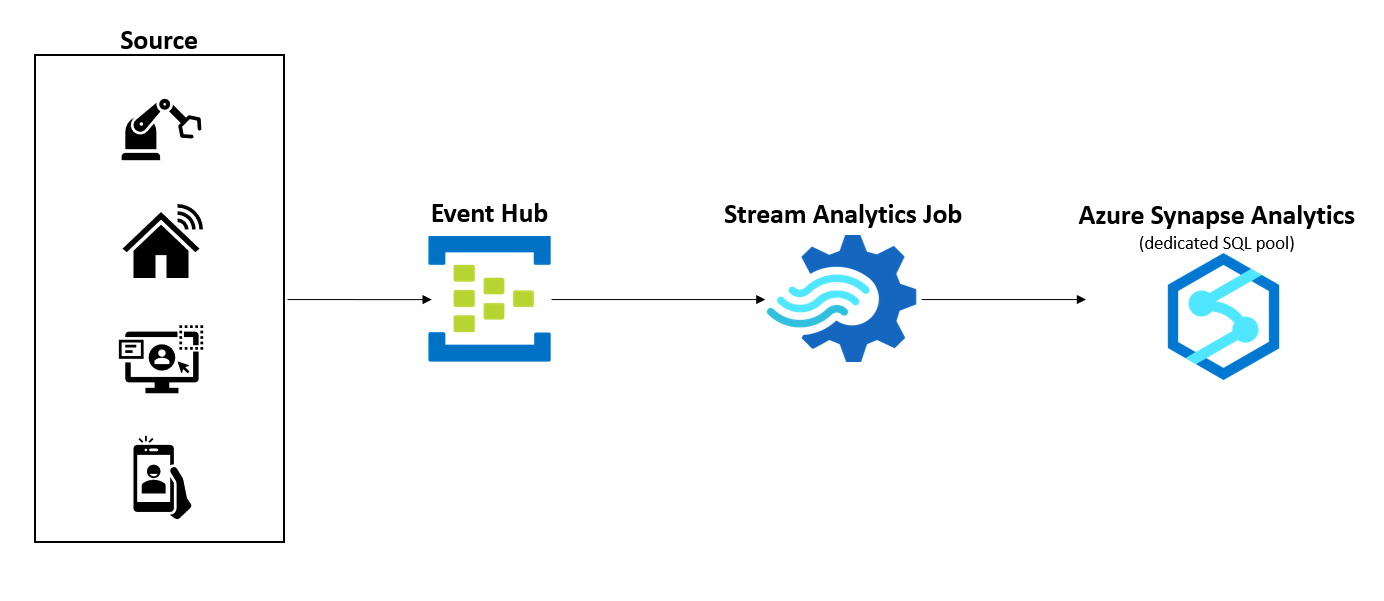

- Rainbow Six Vegas (code game) / PC
- English (Publication Language)

- Battery LR1130 button battery,lens: optical...
- ABS anti-drop material,comfortable to hold,more...
- in daytime,you can shut it up by click the button...
- The eyepiece can be zoomed and zoomed,and the...
- Perfect for any type of task - Reading small -...

- Convenience & flexibility: 5 pockets throughout...
- Best travel gift for friend & family: Suitable for...
- Superior quality materials and comfort: Made with...
- Safe from pick-pocketing: Electronic...
- Organize most travel essentials: With 5 pockets,...
The architecture shows the components of the stream data ingestion pipeline. Data flows through the architecture as follows:
- The source systems generate data and send it to an Azure Event Hubs instance. Event Hubs is a big data streaming platform and event ingestion service that can receive millions of events per second.
- Next, a Stream Analytics job processes the data stream from the Event Hubs instance. Stream Analytics has first-class integration with Event Hubs to consume data streams.
- The Stream Analytics job has an output configured to sink the data to a Synapse Analytics dedicated SQL pool. Apart from doing a simple passthrough of the data stream to target, the Stream Analytics job can perform standard stream processing tasks, such as JOINs, temporal aggregations, filtering, anomaly detection, and so on.
- The Stream Analytics job writes the data in a Synapse Analytics dedicated SQL pool table.
Components
- Azure Synapse Analytics is an analytics service that combines data integration, enterprise data warehousing, and big data analytics. In this solution:
- The Dedicated SQL Pool refers to the enterprise data warehousing features that are available in Azure Synapse Analytics. A dedicated SQL pool represents a collection of analytic resources that are provisioned when you use Synapse Analytics.
- Azure Event Hubs is a real-time data streaming platform and event ingestion service. Event Hubs can ingest data from anywhere, and it seamlessly integrates with Azure data services.
- Azure Stream Analytics is a real-time, serverless analytics service for streaming data. Stream Analytics offers rapid, elastic scalability, enterprise-grade reliability and recovery, and built-in machine learning capabilities.
Alternatives
- Azure IoT Hub could replace or complement Event Hubs. The solution you choose depends on the source of your streaming data, and whether you need cloning and bidirectional communication with the reporting devices.
- Azure Synapse serverless Apache Spark pools can replace Azure Stream Analytics by using Spark Structured Streaming. But the solution will be more complex to develop and maintain.
Considerations
Performance
To achieve high throughput, there are a few key points that need to be considered while implementing the solution:
- Apply partitioning in the Event Hubs instance to maximize raw I/O throughput and to parallelize the consumers' processing. Partitions don't cost money. The cost of Event Hubs depends on the throughput unit (TU). To avoid starving consumers, use at least as many partitions as consumers. Use more keys than partitions to avoid unbalanced partition loads. For detailed best practices on partitioning, see Original Postartitioning-in-event-hubs-and-kafka" target="_blank" rel="noreferrer noopener">Partitioning in Event Hubs and Kafka.
- An Azure Stream Analytics job can connect to Azure Synapse using both the Azure Synapse Analytics connector and the SQL Database connector. Use the Azure Synapse Analytics connector, because it can achieve a throughput of 200 MB/s. The maximum throughput for the SQL Database connector is 15 MB/s.
- Use hash or round robin distribution for the Synapse dedicated SQL pool table. Don't use a replicated table.
- Stream Analytics will parallelize the job, based on the number of partitions, and it creates separate connections to Synapse Analytics for each parallel process. The total number of connections is equal to the number of partitions multiplied by the number of jobs (connections = partitions x jobs). Synapse Analytics can have a maximum of 1024 connections. Partition wisely, to avoid more than 1024 connections. Otherwise, Synapse Analytics will start throttling the connections.
Pricing
- The Azure Event Hubs bill is based on tier, throughput units provisioned, and ingress traffic received.
- Azure Stream Analytics bases costs on the number of provisioned streaming units.
- Azure Synapse Analytics Dedicated SQL pool compute is separate from storage, which enables you to scale compute independently of the data in your system. You can purchase reserved capacity for your Dedicated SQL pool resource, to save up to 65 percent, compared to pay-as-you-go rates.