




This image was generated by the Dall-E as a response to the prompt: “Confused AI bot, pencil sketch”
The potential of using AI in enterprises has been on the rise for the last few years. The release of ChatGPT made it apparent to enterprises that AI could supercharge their existing applications. However, like with any new technology, the usage of LLMs also brings with it some risks. Depending on how the LLMs are deployed (training an in-house LLM v/s 3rd party LLMs) and how the LLMs are used (by individuals to supercharge their work v/s integrating with LLM APIs in applications), the risks LLMs pose will change. This post outlines key risks and helps prioritize them based on your organization’s use case.
Most posts in this newsletter are based on my personal AppSec experience. Like most people in Appsec, I do not have any significant experience building, managing, or securing LLM usage at scale. In that sense, this post is a departure from the norm. However, I am still publishing this as a submission to the growing body of work on this subject. In the coming months, I hope we will have some consensus on how to address this important topic.
Here are a few caveats you should keep in mind before you read this document:
-
There is a reasonable chance that some of this information will be outdated a few weeks from now. That is just the nature of fast-changing technology. Most posts in Boring AppSec are “timeless topics”. This one is timely and fluid.
-
Most of my research for this post is secondary. This means, not all the information provided here is based on my experience securing LLMs. Much of it is from other authors who have published excellent, public work (e.g.: OWASP Top 10 for LLMs). For instance, if an excellent description of a vulnerability already exists, it has been used here. All the material which has influenced my thinking is linked in the references section.
-
Side note: The reference section has some amazing resources. Please feel free to enter rabbit holes 🙂
-
There are many ways to slice and dice LLM use cases, but from a Security perspective, it may help to categorize them as follows:
-
Use-cases
-
Employees use LLM tools to improve productivity or help with their work. (e.g.: Github Copilot, ChatGPT, and Google BARD).
-
Integrating applications with LLM APIs
-
Internal applications leveraging LLMs to improve their efficacy or inform internal decision-making.
-
Customer-facing applications, where customer input informs part (or all) of the prompts sent to the LLM, and the response is consumed in some form by the customer.
-
Note: I am using “customer” as a proxy for “someone external”. In your context, this could be a non-paying user, a business that uses your product, and so on.
-
-
-
-
Deployment type. Companies can choose from 2 broad paths:
-
3rd party LLMs: Integrating applications with 3rd party LLMs such as OpenAI.
-
Self-hosted LLMs: Deploying an open-source LLM in-house and using proprietary data to train the LLM.
-


A few points on the trade-off between self-hosted and 3rd party LLMs:
-
Unless significant investments are made in building a cross-functional team involving ML engineers, security engineers, and privacy professionals, self-hosting an open-source LLM and training brings more security risk than leveraging a trusted 3rd party.
-
On the flip side, 3rd party hosted LLMs pose more privacy and data security risks. Over time, 3rd party hosted LLMs can also get really expensive.
-
If using an LLM has to be a business differentiator for your organization, deploying and training a model in-house is the right way to go
-
Irrespective of which path your organization chooses, it is critical to understand the risks it poses and find ways to manage them.
There are many excellent lists of risks to using LLMs (see references for a solid list). In this post, I am focusing on seven patterns that can pose a high level of risk for your organization. While it's clear that new risk categories will emerge over time, this list should give us a broad overview of the risks out there and more importantly, help us understand what risks are applicable to our organization.
While it’s tempting to solve all risks, it is important to prioritize. Companies should evaluate which use-case and deployment type is most prevalent in their organization and focus on mitigating High-risk items first. The below table provides a summary of risk levels for the use cases and deployment models mentioned above. In the next section, we will dive deeper into each of the highlighted “high-risk” scenarios.
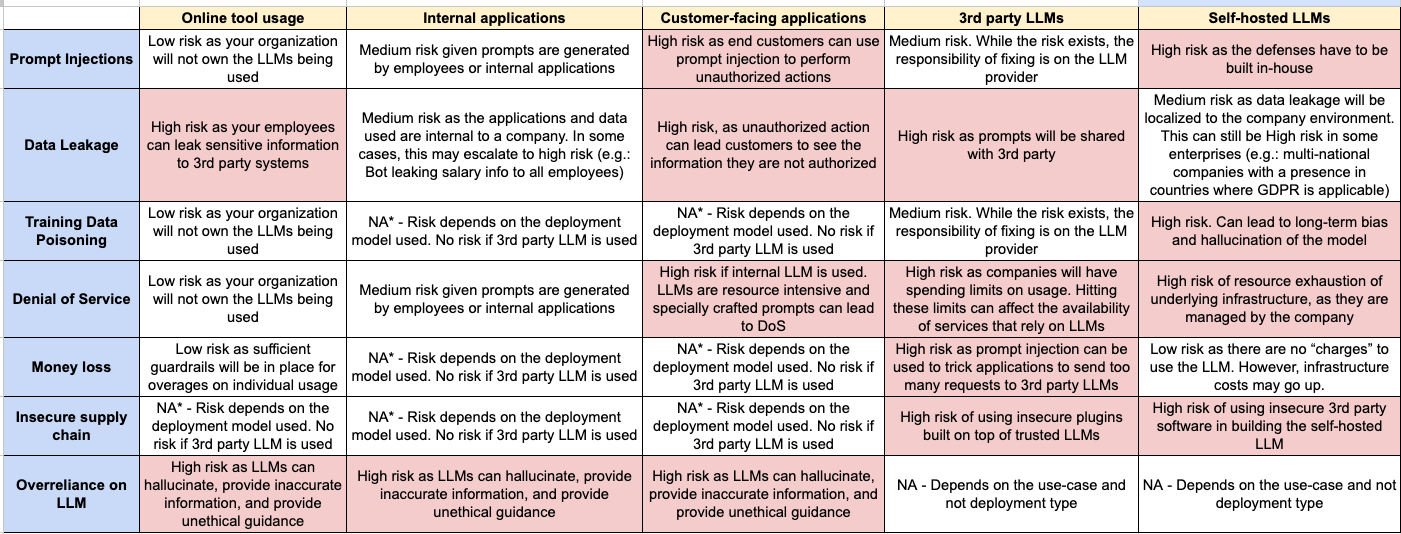
Risk ranking of the most common LLM risks, categorized by use-case and deployment type
-
Prompt injection: “Prompt Injection Vulnerabilities in LLMs involve crafty inputs leading to undetected manipulations. The impact ranges from data exposure to unauthorized actions, serving attacker goals.” – OWASP Top 10 for LLMs
-
Customer-facing applications: A malicious customer can take advantage of the concatenation of user input to a pre-written prompt string to override the guardrails put in place for user prompts. Much like other forms of injection, user input is used as instructions to control the outcome of the application.
-
Self-hosted LLMs: An attacker can take advantage of the concatenation of user input to a pre-written prompt string to override the guardrails put in place for user prompts. Much like other forms of injection, user input is used as instructions to control the outcome of the application. Prompt injection is a broad attack vector and can take many forms, including
-
Trusting data from plugins or other third parties
-
Exploiting LLM hallucination. If an attacker can predict that LLMs recommend made-up package names, the attacker can create and publish such packages with malicious software in them
-
-
-
Data leakage: “Data leakage in LLMs can expose sensitive information or proprietary details, leading to privacy and security breaches. Proper data sanitization and clear terms of use are crucial for prevention.” – OWASP Top 10 for LLMs
-
Employees using online tools: Given there is a free version of these tools available, there is a risk of leaking sensitive data to the LLM tool. This risk is higher with tools like ChatGPT, where the prompts entered are used to train the underlying model (e.g.: Samsung code data). Note that other tools (such as Bard from Google) do not use prompts to train their model. However, the risk of leaking data to the tool owner still exists.
-
Customer-facing applications: When used without sufficient guardrails, customer-facing applications leveraging LLMs can leak sensitive (PHI, PII) and proprietary information to the customer.
-
Note: Even when guardrails are in place, Prompt Injection can be used to bypass the guardrails, leading to data leakage
-
-
3rd party LLMs: Insecure usage can lead to sensitive information (PII, PHI) or proprietary details being leaked to 3rd parties leading to privacy and security breaches.
-
-
Training data poisoning: – “LLMs learn from diverse text but risk training data poisoning, leading to user misinformation. Overreliance on AI is a concern. Key data sources include Common Crawl, WebText, OpenWebText, and books” – OWASP Top 10 for LLMs
-
Self-hosted LLMs: Training data poisoning is a significant risk for self-hosted LLMs. Insecure data training can lead to bias and hallucination. We need to break down the problem into various stages of the machine learning pipeline. For instance: Bias can be introduced in the training data (e.g.: all the training data came from a specific neighborhood), in the classifier algorithm, or in the prediction engine.
-
-
Denial of service: “An attacker interacts with an LLM in a way that is particularly resource-consuming, causing the quality of service to degrade for them and other users, or for high resource costs to be incurred.” – OWASP Top 10 for LLMs
-
Self-hosted LLMs: LLMs are resource intensive to train and maintain. Carefully crafted prompts or malicious training data can lead to the LLM consuming a lot of infrastructure resources which can lead to resource exhaustion and hence, denial of service.
-
-
Money loss: Much like cloud computing resources, 3rd party LLMs charge based on consumption (OpenAI uses “tokens”, others use a similar mechanism). Unvalidated usage of these APIs can lead to a massive, unplanned cost escalation.
-
3rd party LLMs: Most 3rd party LLMs charge by usage. Higher the usage, the higher the cost. Attackers can carefully craft prompts to lead to massive charges on LLM usage. If the usage is capped to limit money loss, similar attacks can lead to DoS (denial of service).
-
-
Insecure supply chain: “LLM supply chains risk integrity due to vulnerabilities leading to biases, security breaches, or system failures. Issues arise from pre-trained models, crowdsourced data, and plugin extensions.” – OWASP Top 10 for LLMs
-
3rd party LLMs: Most popular 3rd party LLMs allow developers to build plugins on top of their platform (e.g.: OpenAI). While we may have a trusted relationship with the LLM (through an NDA and a contract), managing risk from plugins is harder. While the risk is significant, this is not very different from the risk of using other platforms (e.g.: using Github actions and importing 3rd party actions).
-
Self-hosted LLMs: An in-house LLM relies heavily on various kinds of third-party components. From malicious training data (which we may not have complete control of) to outsourcing suppliers who will train the data, there are many supply chain attack vectors to worry about
-
-
Overreliance on LLM-generated content: “Overreliance on LLMs can lead to misinformation or inappropriate content due to “hallucinations.” Without proper oversight, this can result in legal issues and reputational damage” – OWASP Top 10 for LLMs
-
Employees using online tools: A common use case is to use such tools to generate source code. While the tool can help reduce development time, it can lead to using insecure (e.g.: code generated is susceptible to SSRF) or unlicensed code (e.g.: the code generated is from an open source repo. Even outside engineering, using LLM responses to make important decisions at work can lead to unpredictable outcomes.
-
Internal applications: Given its propensity to hallucinate and introduce undesired bias, relying solely on LLM output can lead to undesirable outcomes. This can especially lead to systemic, long-term issues if the training data itself is poisoned.
-
Customer-facing applications: When systems excessively depend on LLMs for decision-making or content generation without adequate oversight, validation mechanisms, or risk communication. LLMs are also susceptible to “hallucinations,” producing content that is factually incorrect, nonsensical, or inappropriate. These hallucinations can lead to misinformation, miscommunication, potential legal issues, and damage to an organization's reputation if unchecked.
-
There is a possibility that there is no clarity on which of these use cases and deployment models are prevalent in your organization. In that scenario, your first job as a Security team would be to understand how LLMs are currently used and understand the plans for future usage. On the data gathered, you can apply the above framework to narrow down the risks that matter most to your organization.
That’s it for today! Are there significant risks that are missed in this post? What other aspects of leveraging LLMs worry you? Is there value in having yet another author talking about securing LLMs? Tell me more! You can drop me a message on Twitter, LinkedIn, or email. If you find this newsletter useful, share it with a friend, or colleague, or on your social media feed.
-
Playgrounds
-
Aviary Explorer: A way to compare results from open source LLMs: Aviary Explorer (anyscale.com)
-
A playground for prompt injection. Basically tricking LLMs in revealing secrets https://gandalf.lakera.ai/
-
Holistic evaluation of LLMs (HELM) from Stanford: https://crfm.stanford.edu/helm/latest/
-
-
Security
-
LLM OWASP Top 10: Very useful, but some of them are a stretch. Currently at v0.5 https://owasp.org/www-project-top-10-for-large-language-model-applications/assets/PDF/OWASP-Top-10-for-LLMs-2023-v05.pdf
-
Prompt injection methods: GitHub – greshake/llm-security: New ways of breaking app-integrated LLMs
-
Skyflow data privacy for GPT: https://www.skyflow.com/post/generative-ai-data-privacy-skyflow-gpt-privacy-vault
-
Lakera is an AI security company. They have specific products to protect against Prompt injection: Lakera Guard | Unlock LLMs for Production | Lakera – Protecting AI teams that disrupt the world.
-
Daniel Miessler on AI Attack Surface Map: https://danielmiessler.com/blog/the-ai-attack-surface-map-v1-0/
-
Generative AI: 5 Guidelines for Responsible Development – Salesforce News
-
Nvidia’s AI red team framework: :https://developer.nvidia.com/blog/nvidia-ai-red-team-an-introduction/
-
IBM AI fairness 360 tools to detect bias: https://www.ibm.com/opensource/open/projects/ai-fairness-360/
-
tldrsec on a similar topic: How to securely build product features using AI APIs (tldrsec.com)
-
-
Enterprise related things
-
Should you buy or build: When it comes to large language models, should you build or buy? | TechCrunch
-
Companies blocking ChatGPT and other publicly trained chatbots: Employees are banned from using ChatGPT at these companies | Fortune
-
Google thinks open source LLMs will be as good as OpenAI soon: Google’s Leaked Document Reveals Open Source Threat: A New Era in Language Models | BigTechWire
-
Triveto language model whitepaper: https://www.truveta.com/wp-content/uploads/2023/04/Truveta-Language-Model.pdf