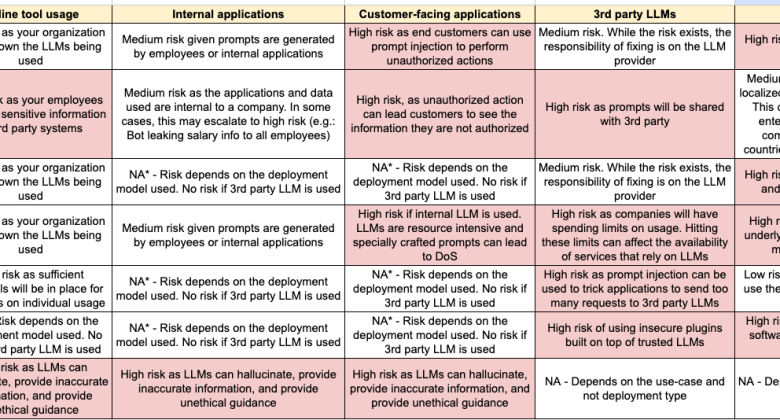
Unless significant investments are made in building a cross-functional team involving ML engineers, security engineers, and privacy professionals, self-hosting an open-source LLM and training brings more








Big data processing in a data warehouse environment using AWS Glue 2.0 and PySpark
n this post, we discuss one such example of improving operational efficiency and how we optimized our ETL process using AWS Glue 2.0 and PySpark SQL to achieve huge parallelism and reduce the runtime significantly—under 45 minutes—to deliver data to business much sooner.
We did this by running a SQL query repeatedly in Amazon Redshift , incrementally processing 2 months at a time to account for several years of historical data, with several hundreds of billions of rows in total.




