For this tutorial, we use a PDF file of our Medium article “ The Future of Artificial Intelligence is Open-source!

For this tutorial, we use a PDF file of our Medium article “ The Future of Artificial Intelligence is Open-source!

The alternative is to create vector embeddings — arrays of numeric values produced from the text by another pre-trained machine learning model (Morgan Stanley uses one from OpenAI called Ada).

These articles, covering a variety of AI and machine learning topics, are ingested and indexed in our Chroma vector database.
This text details how to use the llama.cpp library in Python for efficient execution of Large Language Models (LLMs) on CPUs. The blog post guides users on implementing llama-cpp-python, a package that binds llama.cpp to Python, and demonstrates its usage by running the Vicuna LLM. Furthermore, it discusses the library’s flexible framework, the GGML format for model conversion, and the notable features (n_ctx and n_batch) to consider during implementation.

Machine Learning Advisor The Machine Learning Advisor plugin acts as your virtual guide in the world of machine learning…. Leverage its expertise to make informed decisions and accelerate your machine learning projects.

Now, imagine something similar, but for machine learning training and prediction…. In the world of machine learning, AutoML is like your personal assistant.

You tend to go back to the drawing board less when you get the basics right. Intro to Deep Learning Deep learning is a type of machine learning that uses artificial neural networks to learn from data. Neural networks

Ashok Srivastava, Chief Data Officer of Intuit, a company that has been using LLMs for years in the accounting and tax industries, told VentureBeat in an extensive interview that this infrastructure could be

It helps log and visualize the metrics, hyperparameters, and other important aspects of machine learning experiments.

Cloudera’s platform provides an open data lakehouse model that enables organizations to run data analytics operations on top of data lake storage. Alongside the LLM integration, Cloudera also announced the general
A brief on generative AI Generative AI is an artificial intelligence technology that can generate images, text, or music that are similar to the dataset on which it was trained.

Machine learning can be categorized into supervised learning, unsupervised learning, semi-supervised learning, reinforcement learning, deep learning and so on…. We covered an Introduction to Machine
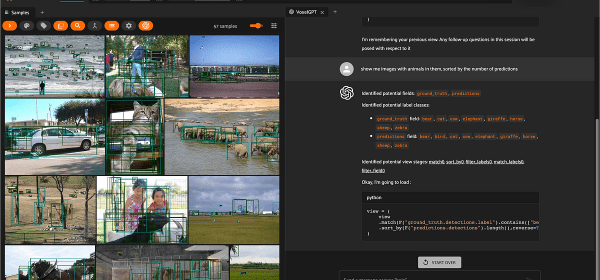
Your task is to convert input natural language queries into Python code to generate ViewStages for the machine learning library FiftyOne.

In the evolving space of artificial intelligence, one ground-breaking model has captured the attention of researchers, businesses, and tech enthusiasts alike:… Whether you are a startup founder, a technologist, or