To show you how easy and quick it is to get started on AWS, we provide a one-click deployment for an extensible trading backtesting solution that uses Kinesis long-term retention for streaming data.

To show you how easy and quick it is to get started on AWS, we provide a one-click deployment for an extensible trading backtesting solution that uses Kinesis long-term retention for streaming data.
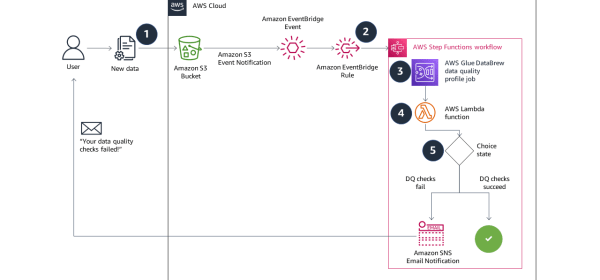
Businesses collect more and more data every day to drive processes like decision-making, reporting, and machine learning (ML). Before cleaning and transforming your data, you need to determine whether it’s fit for use. Incorrect, missing, or malformed data can have large impacts on downstream analytics and ML processes. Performing data quality checks helps identify issues earlier in your workflow so you can resolve them faster. Additionally, doing these checks using an event-based architecture helps you reduce manual touchpoints and scale with growing amounts of data.
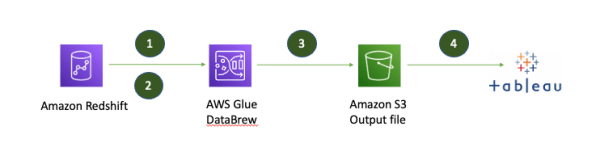
With AWS Glue DataBrew, you can now easily transform and prepare datasets from Amazon Simple Storage Service (Amazon S3), an Amazon Redshift data warehouse, Amazon Aurora, and other Amazon Relational Database Service (Amazon RDS) databases and upload them into Amazon S3 to visualize the transformed data in a dashboard using Amazon QuickSight or other business intelligence (BI) tools like Tableau.

Data lakehouses are underpinned by a new open system architecture that allows data teams to implement data structures through smart data management features similar to data warehouses over a low-cost storage platform that is similar to the ones used in data lakes
I’m on a journey to help make machine learning (ML) and artificial intelligence (AI) more accessible to everyone.

This post uses the AWS CLI to establish cross-account audit logging for Amazon Redshift, as illustrated in the following architecture diagram.

Some of the most critical aspects of DaaS offerings are ease of management, security, cost-efficiency, workload isolation, and high resiliency and availability.

Recently, we helped a customer who was building their data warehouse on Amazon Redshift and had the requirement of using Microsoft Azure Active Directory (Azure AD) as their corporate IdP with MFA. This post illustrates how to set up federation using Azure AD and AWS Identity and Access Management (IAM). Azure AD manages the users and provides federated access to Amazon Redshift using IAM.