In addition to autoscaling, we recently launched new capabilities for Bigtable that reduce cost and management overhead:

In addition to autoscaling, we recently launched new capabilities for Bigtable that reduce cost and management overhead:
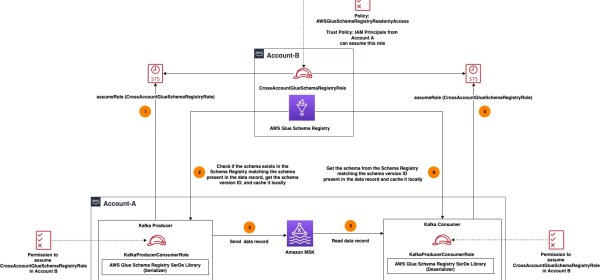
This post demonstrates how Apache Kafka stream processing applications validate messages using an Apache Avro schema stored in the AWS Glue Schema registry residing in a central AWS account
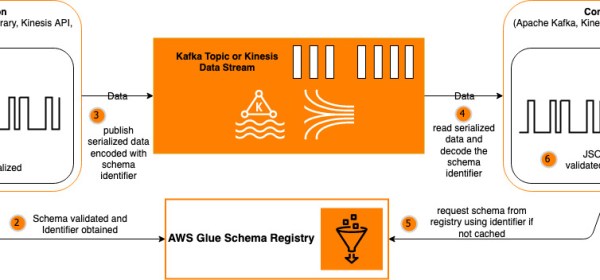
As applications, websites, and machines increasingly adopt data streaming technologies such as Apache Kafka and Amazon Kinesis Data Streams, which serve as a highly available transport layer that decouples the data producers from data consumers, it can become progressively more challenging for teams to coordinate and evolve JSON Schemas

This article provides resources to learn about Azure databases. It outlines paths to implement the architectures that meet your needs, and best practices to keep in mind as you design your solutions.

Lake Formation allows you to grant and revoke permissions on databases, tables, and column catalog objects created on top of Amazon S3 data lake.
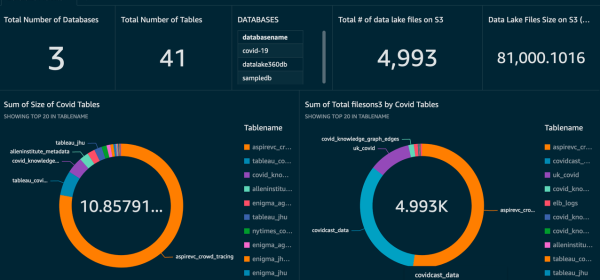
Azure Purview can automatically discover, catalog, classify, and manage data across Microsoft SQL offerings, whether on-premises or in Azure.
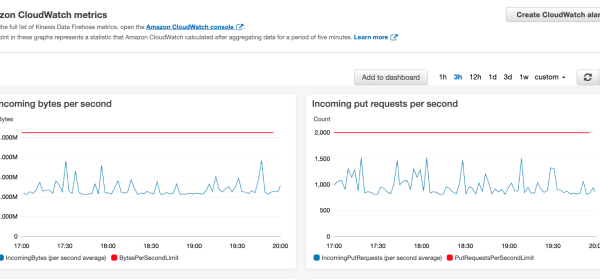
The volume of data being generated globally is growing at an ever-increasing pace. Data is generated to support an increasing number of use cases, such as IoT, advertisement, gaming, security monitoring, machine learning (ML), and more. The growth of these use cases drives both volume and velocity of streaming data and requires companies to capture, processes, transform, analyze, and load the data into various data stores in near-real time.
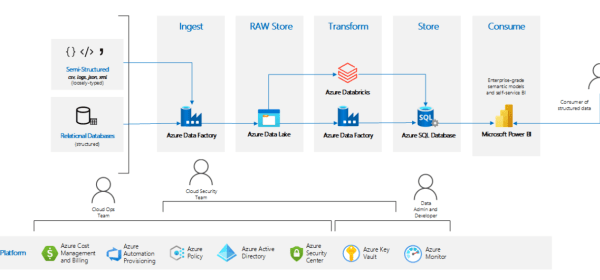
In recent years, the demand for business users to be able to consume, transform, model, and visualize large amounts of complex data from multiple heterogeneous sources has increased dramatically. To meet this demand in a cost-effective, scalable way, many large companies have benefitted from moving to cloud-based data platforms.

To show you how easy and quick it is to get started on AWS, we provide a one-click deployment for an extensible trading backtesting solution that uses Kinesis long-term retention for streaming data.
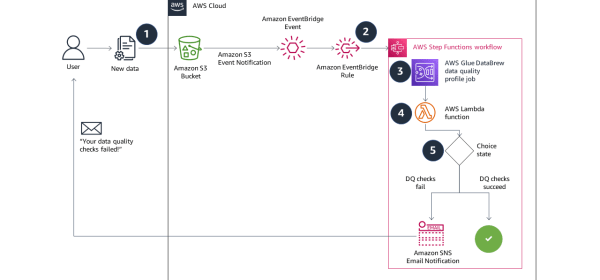
Businesses collect more and more data every day to drive processes like decision-making, reporting, and machine learning (ML). Before cleaning and transforming your data, you need to determine whether it’s fit for use. Incorrect, missing, or malformed data can have large impacts on downstream analytics and ML processes. Performing data quality checks helps identify issues earlier in your workflow so you can resolve them faster. Additionally, doing these checks using an event-based architecture helps you reduce manual touchpoints and scale with growing amounts of data.
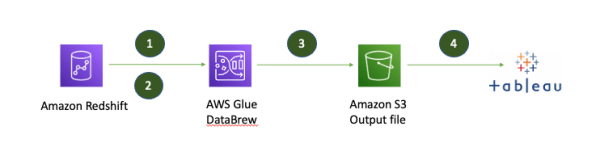
With AWS Glue DataBrew, you can now easily transform and prepare datasets from Amazon Simple Storage Service (Amazon S3), an Amazon Redshift data warehouse, Amazon Aurora, and other Amazon Relational Database Service (Amazon RDS) databases and upload them into Amazon S3 to visualize the transformed data in a dashboard using Amazon QuickSight or other business intelligence (BI) tools like Tableau.
Data lakehouses are underpinned by a new open system architecture that allows data teams to implement data structures through smart data management features similar to data warehouses over a low-cost storage platform that is similar to the ones used in data lakes
I’m on a journey to help make machine learning (ML) and artificial intelligence (AI) more accessible to everyone.

This post uses the AWS CLI to establish cross-account audit logging for Amazon Redshift, as illustrated in the following architecture diagram.