There are many reasons why customers consider migrating their existing on-premises big data workloads to Azure.
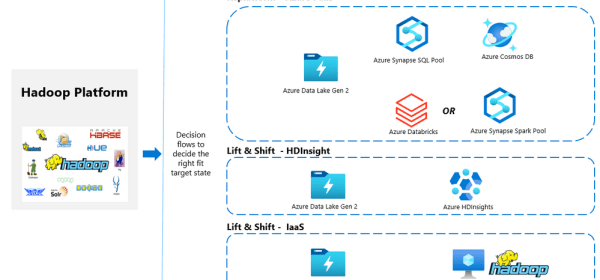
There are many reasons why customers consider migrating their existing on-premises big data workloads to Azure.
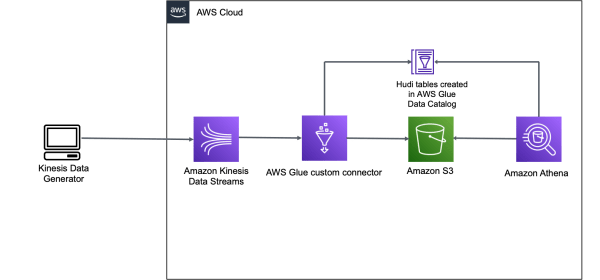
To deliver on these requirements, organizations have to build custom frameworks to handle in-place updates (also referred as upserts), handle small files created due to the continuous ingestion of changes from upstream systems (such as databases), handle schema evolution, and compromise on providing ACID guarantees on its data lake
To consume this streaming data, we set up an AWS Glue streaming ETL job that uses the Apache Hudi Connector for AWS Glue to write ingested and transformed data to Amazon S3, and also creates a table in the AWS Glue Data Catalog.

Upsolver is an AWS Advanced Technology Partner that enables you to ingest data from a wide range of sources, transform it, and load the results into your target of choice, such as Kinesis Data Streams and Amazon Redshift.
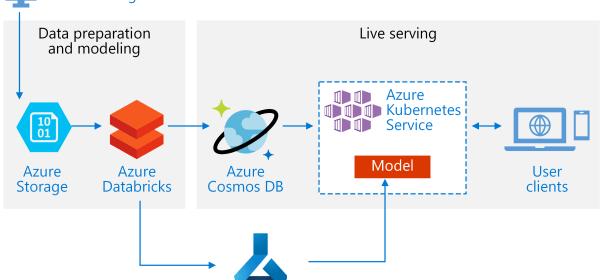
This reference architecture shows how to train a recommendation model using Azure Databricks and deploy it as an API by using Azure Cosmos DB, Azure Machine Learning, and Azure Kubernetes Service (AKS).

In this post, we demonstrate the use of the AWS Analytics Automation Toolkit for JMeter load tests on cloud benchmark data, using Amazon Redshift as a target environment
To use the AWS Analytics Automation Toolkit to run a JMeter load test, deploy the toolkit with the JMeter option, load data into your Amazon Redshift cluster, and customize the default test plan as you see fit.
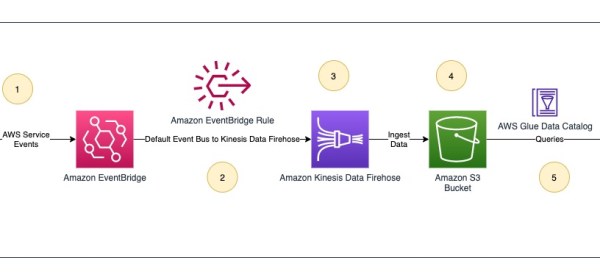
In this post, we provide a working example of AWS service-generated events ingested to Amazon S3. To make sure we have some service events available in default event bus, we use Parameter Store, a capability of AWS Systems Manager to store new parameters manually. This action generates a new event, which is ingested by the following pipeline.

In this post, we share how GDAC created an analytics platform from scratch using AWS services and how GDAC collaborated with the AWS Data Lab to accelerate this project from design to build in record time

This lab walks you through the steps to set up the stack for replicating an Aurora database salesdb to an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster, using Amazon MSK Connect with a MySql Debezium source Kafka connector.

If your organisation has to manage, process and query a great deal of important but short-lived information that is created sporadically and must be reported speedily, then a service like Cosmos DB is ideal.
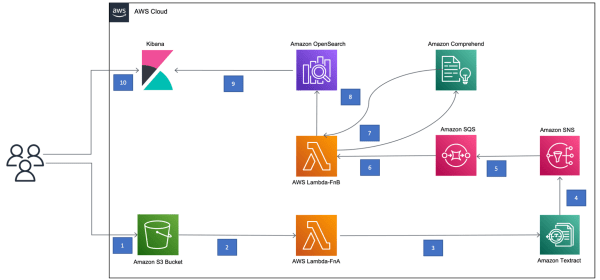
This data is indexed and populated into Amazon OpenSearch Service to search and visualize it in a Kibana dashboard.
Figure 1 illustrates a solution built with AWS, which extracts O&G well data information from PDF documents.
Admission control in Amazon OpenSearch Service enhances the overall resiliency of OpenSearch clusters by limiting new incoming requests early, at the REST layer, when a node is stressed

With the sheer volume of historical and live data feeds being ingested, and the need for a scalable compute platform for backtesting and spread calculations, our team needed a performant single source of truth to build the application dashboards.
As the data sets would be leveraged by machine learning and analyst teams, the Delta Lake format provided unique capabilities for managing high volume market/tick data — these features were key in developing the Gemini Lakehouse platform:
Example 1 – Unload customer data in JSON format into Amazon S3, partitioning output files into partition folders, following the Apache Hive convention, with customer birth month as the partition key.
Example 3 – Unload line item data (With SUPER column) in JSON format into Amazon S3, partitioning output files into partition folders, following the Apache Hive convention, with customer key as the partition key

Each user who accesses the Q search bar assumes a role that gives them QuickSight permissions to retrieve a Q-embedded URL.