Use cases for Amazon Redshift streaming ingestion center around working with data that is generated continually (streamed) and needs to be processed within a short period (latency) of its generation. In this

Use cases for Amazon Redshift streaming ingestion center around working with data that is generated continually (streamed) and needs to be processed within a short period (latency) of its generation. In this

The following shows a simple clinical quality business Data Vault model using Amazon Redshift materialized views. Healthcare clinical quality metric systems stream massive amounts of structured and semi-

In this post, we share how SailPoint updated its platform for big data operations, and solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS . SailPoint acquired a

Create an AWS Identity and Access Management (IAM) policy with limited Amazon Simple Storage Service (Amazon S3) read privileges and associated role for AWS Glue. The first step is to create an IAM policy
Apply Apache Spark pool and Synapse Pipelines in Azure Synapse Analytics to access and move data at scale. If you’d like to see us expand this article with more information, such as potential use cases,

This technology combines the power of in-memory computing with the digital twin software model to enable incoming telemetry from millions of devices to be analyzed immediately – as it flows in – instead of requiring
Today, thousands of AWS customers from nearly every industry use Athena federated queries to surface insights and make data-driven decisions from siloed enterprise data—using a single AWS service and

In the following sections, we walk through the steps to set up the environment, download the libraries, create and run the AWS Glue job, and explore the data. In the next step, we create an AWS Glue table
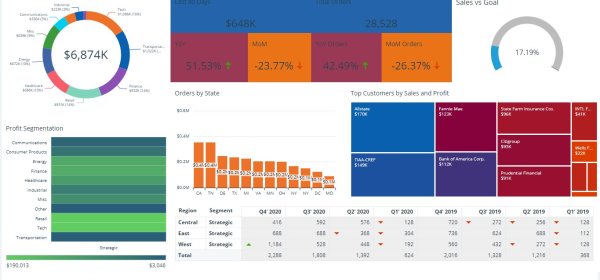
Core components of this solution incorporate the ability to pass pre-filtered data from Power BI into a Power Apps and/or Power Automate funnel for any updates in a supporting back end. Power BI doesn’t

With the Performance Efficiency pillar of the Azure Well-Architected Framework, organizations must ensure the workloads they modernize and migrate to the cloud are able to scale to meet changes in demand

In this post, we illustrate how you can orchestrate DataBrew jobs with AWS Step Functions to build a data pipeline to handle PII data. Because the profile job result and threshold value have already been used to
Amazon Kinesis Data Analytics Studio makes it easy for customers to analyze streaming data in real time, as well as build stream processing applications powered by Apache Flink using standard SQL, Python, and
This architecture is designed to show an end-to-end implementation that involves extracting, loading, transforming, and analyzing spaceborne data by using geospatial libraries and AI models with Azure Synapse
You don’t need to create AWS Identity and Access Management (IAM) roles, policies, separate database users, or groups in Amazon Redshift with this setup. In this example, we use Power BI Desktop to connect