Keep a single copy of data and enforce consistent access controls across analytics engines of your choice, including Google Cloud and open-source technologies such as Spark, Presto, Trino, and Tensorflow.

Keep a single copy of data and enforce consistent access controls across analytics engines of your choice, including Google Cloud and open-source technologies such as Spark, Presto, Trino, and Tensorflow.
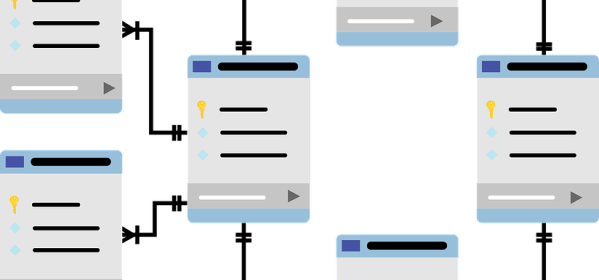
In this post, we explore the role-based access control (RBAC) features of Amazon Redshift and how you can use roles to simplify managing privileges required to your end-users. Only superusers or regular users

One of the most popular ML interfaces today are notebooks: interactive environments that allow you to write code, visualize and pre-process data, train models, and a whole lot more. With native integrations across

The following diagram represents a design pattern where S3 event notifications are sent to an SNS topic, which are then forwarded to an SQS queue for the crawler to consume. To create your IAM policy with for

Our solution uses the Spline agent to capture runtime lineage information from Spark jobs, powered by AWS Glue . The Spline agent is configured in each AWS Glue job to capture lineage and run metrics, and sends such data
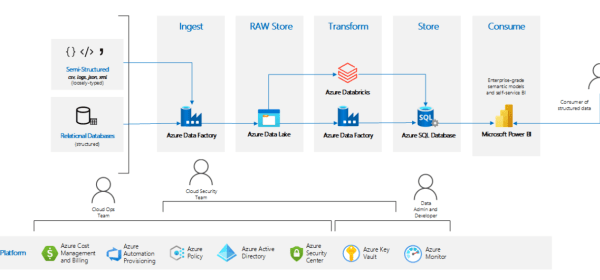
Although the Airflow console does provide a series of visualisations that help you analyse these datasets, these are siloed from other Amazon MWAA environments you might have running, as well as the rest of your business data. In this post, we discuss how to export, persist and analyse Airflow

We also demonstrate how to set up and use CodeGuru Profiler to monitor an application’s health and capture important metrics to optimize the performance of Kinesis Data Analytics for Apache Flink applications. You can
Omar Khawaja, Head of BI and Analytics at Roche Diagnostics, and his team have been on a journey to implement data mesh, including self-service data and analytics infrastructure capabilities. We spoke to Omar Khawaja and Paul Rankin, Head of Data Management and Architecture at Roche Diagnostics,
You can now control the amount of ephemeral storage a function gets for reading or writing data, allowing you to use AWS Lambda for ETL jobs, ML inference, or other data-intensive workloads. However, extract, transform, and
In this step, you use AWS SCT and sometimes source data warehouse native tools to capture and load delta or incremental changes from sources to Amazon Redshift. You begin with creating a database migration assessment report and then converting the source data schema to be compatible with
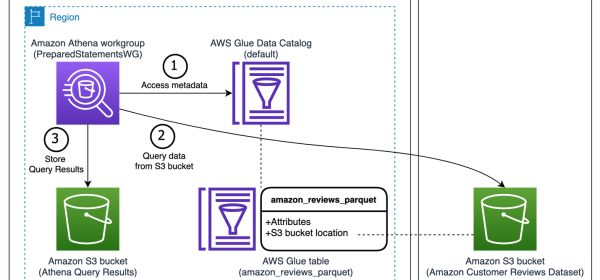
Athena parameterized queries also provide a layer of security against SQL injection attacks, and mask the query string in AWS CloudTrail for workloads with sensitive data. This post provides an example of how Athena parameterized queries protect against SQL injection, and shows the
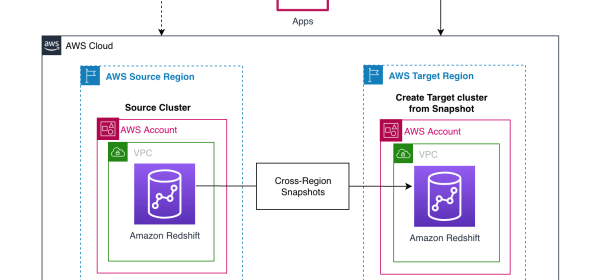
After you copy the snapshots to the target Region, you can restore the latest snapshot to create a new Amazon Redshift cluster. Restore the latest snapshots to create a new Amazon Redshift cluster in the target Region.

We restore the backed-up data to another Kafka topic and reset the consumer offsets based on your use case. In this post, we use the Lenses AWS S3 Connector to back up the data stored in a topic in an Amazon MSK
If you choose to bring your own custom connector or prefer a different connector from AWS Marketplace, follow the steps in this blog Performing data transformations using Snowflake and AWS Glue . To configure, follow the instructions in Setting up IAM Permissions for AWS Glue and Create an