Alongside our extensive ecosystem of ETL and data ingestion partners who help move data into the Data Cloud, Snowflake offers a wide range of first party methods to meet the different data pipeline needs from batch
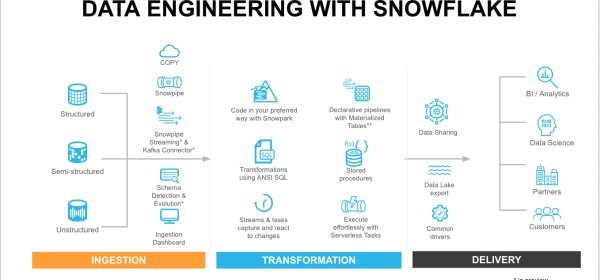
Alongside our extensive ecosystem of ETL and data ingestion partners who help move data into the Data Cloud, Snowflake offers a wide range of first party methods to meet the different data pipeline needs from batch
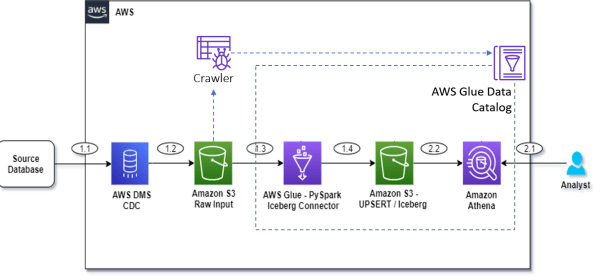
To solve this use case, we present the following simple architecture that integrates Amazon S3 for the data lake, AWS Glue with the Apache Iceberg connector for ETL (extract, transform, and load), and Athena for
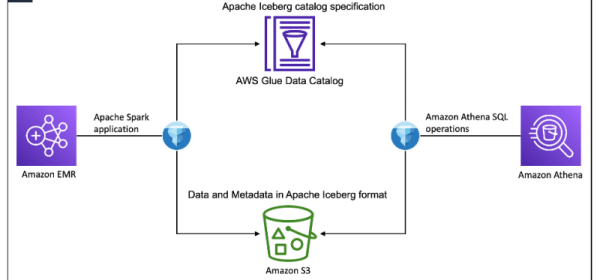
In this post, we show you how to use Amazon EMR Spark to create an Iceberg table, load sample books review data, and use Athena to query, perform schema evolution, row-level update and delete, and time travel,

This article describes the design process, principles, and technology choices for using Azure Synapse to build a secure data lakehouse solution. Serverless SQL pool, Apache Spark in Azure Synapse, Azure

AWS Lake Formation allows you to define and enforce access policies at the database, table, and column level when using Athena queries to read data stored in Amazon S3. In this post, we show you how you can use

This post describes how to create multilingual dashboards at the data level by creating new columns that contain the translated text and providing a language selection parameter and associated control to
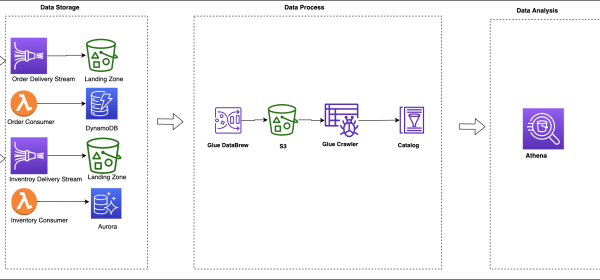
In this post, we create an end-to-end pipeline to ingest, store, process, analyze, and visualize operational data like orders, inventory, and shipment updates. In this post, we demonstrate how to create a

Enterprise IT pros tasked with shoring up resiliency among Kubernetes multi-cluster and multi-cloud environments favored open source service mesh projects Linkerd and Kuma over Istio. Kubernetes can handle some

The following high-level architecture diagram shows the components to integrate Schema Registry and the Data Catalog to run streaming ETL jobs. In this post, we demonstrate how to integrate Schema Registry with

In this post, we look at how we supercharged our data highway, the backbone of our major analytics pipeline, by migrating our Amazon Redshift clusters to RA3 nodes. After discussions with AWS experts and
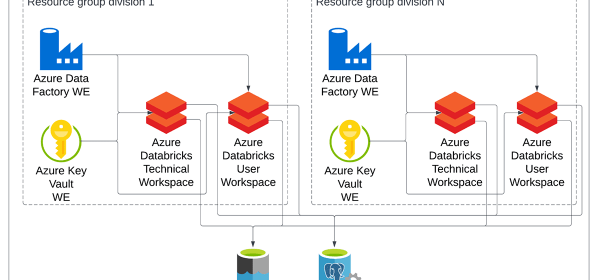
Terraform allows teams to manage their Databricks Runtimes as needed in different environments, while all libraries are now stored as Azure Artifacts, avoiding stale package versions. This blog describes the way we developed our data platform DR scenario, guaranteeing RTOs and
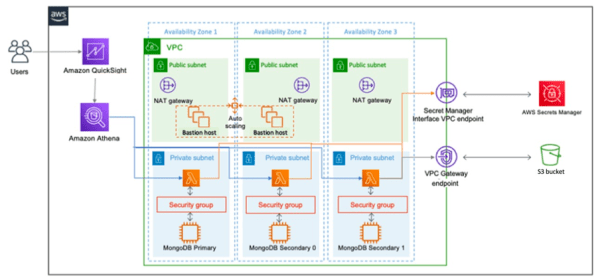
In this post, you will learn how to use Amazon Athena Federated Query to connect a MongoDB database to Amazon QuickSight in order to build dashboards and visualizations. Athena uses data source connectors that
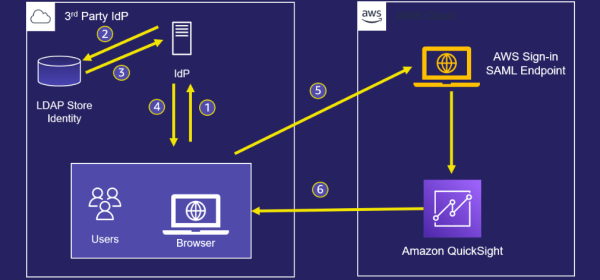
In this post, we go through the steps to configure federated single sign-on (SSO) between a Google Workspace instance and QuickSight account. If the SAML authentication response includes attributes that map to multiple AWS Identity and Access Management (IAM) roles, the user is

Athena now supports querying and creating Ion-formatted datasets via an Ion-specific SerDe, which in conjunction with and allows you to read and write valid Ion data. Let’s run a query that specifies the from our example row of Ion data to verify that we can read from the table: