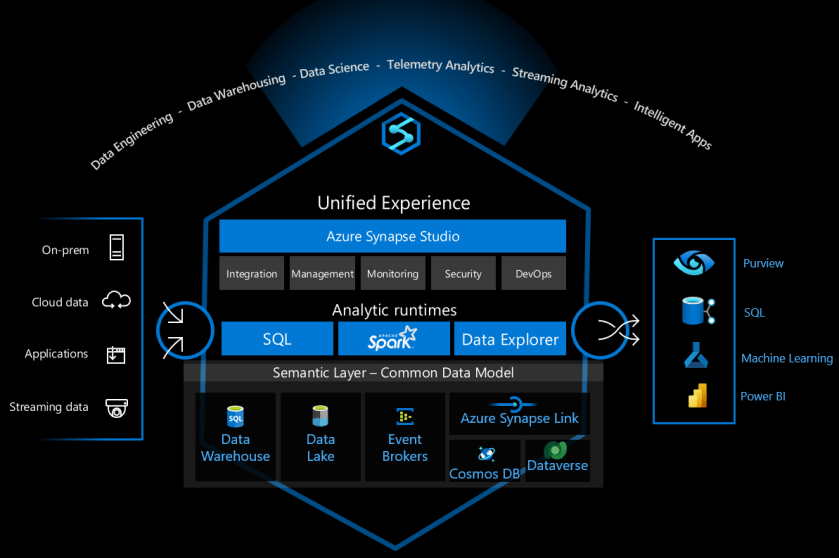
Azure Synapse Analytics is a versatile data platform that supports enterprise data warehousing, real-time data analytics, pipelines, time-series data processing, machine learning, and data governance. To support these capabilities it integrates several different technologies, such as:
- Enterprise data warehousing
- Serverless SQL pools
- Apache Spark
- Pipelines
- Data Explorer
- Machine learning capabilities
- Purview unified data governance
These capabilities open up many possibilities, but there are many technical choices to make to securely configure the infrastructure for safe use.
This article describes the design process, principles, and technology choices for using Azure Synapse to build a secure data lakehouse solution. We focus on the security considerations and key technical decisions. The solution uses these Azure services:
The goal is to provide guidance on building a secure and cost-effective data lakehouse platform for enterprise use and on making the technologies work together seamlessly and securely.
Apache®, Apache Spark®, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Potential use cases
A data lakehouse is a modern data management architecture that combines the cost-efficiency, scale, and flexibility features of a data lake with the data and transaction management capabilities of a data warehouse. A data lakehouse can handle a vast amount of data and support business intelligence and machine learning scenarios. It can also process data from diverse data structures and data sources. For more information, see What is the Databricks Lakehouse?.
Some common use cases for the solution that’s described here are:
- Analysis of Internet of Things (IoT) telemetry
- Automation of smart factories
- Tracking consumer activities and behavior
- Managing security incidents and events
- Monitoring application logs and application behavior
- Processing and business analysis of semi-structured data
Architecture
The following diagram shows the architecture of the data lakehouse solution. It’s designed to control the interactions among the services in order to mitigate security threats. Solutions will vary depending on functional and security requirements.

Download a Visio file of this architecture.
Dataflow
The dataflow for the solution is shown in the following diagram:

- Data is uploaded from the data source to the data landing zone, either to Azure Blob storage or to a file share that’s provided by Azure Files. The data is uploaded by a batch uploader program or system. Streaming data is captured and stored in Blob Storage by using the Capture feature of Azure Event Hubs. There can be multiple data sources. For example, several different factories can upload their operations data. For information about securing access to Blob Storage, file shares, and other storage resources, see Security recommendations for Blob Storage and Planning for an Azure Files deployment.
- The arrival of the data file triggers Azure Data Factory to process the data and store it in the data lake in the core data zone. Uploading data to the core data zone in Azure Data Lake protects against data exfiltration.
- Azure Data Lake stores the raw data that’s obtained from different sources. It’s protected by firewall rules and virtual networks. It blocks all connection attempts coming from the public internet.
- The arrival of data in the data lake triggers the Azure Synapse pipeline, or a timed trigger runs a data processing job. Apache Spark in Azure Synapse is activated and runs a Spark job or notebook. It also orchestrates the data process flow in the data lakehouse. Azure Synapse pipelines convert data from the Bronze zone to the Silver Zone and then to the Gold Zone.
- A Spark job or notebook runs the data processing job. Data curation or a machine learning training job can also run in Spark. Structured data in the gold zone is stored in Delta Lake format.
- A serverless SQL pool creates external tables that use the data stored in Delta Lake. The serverless SQL pool provides a powerful and efficient SQL query engine and can support traditional SQL user accounts or Azure Active Directory (Azure AD) user accounts.
- Power BI connects to the serverless SQL pool to visualize the data. It creates reports or dashboards using the data in the data lakehouse.
- Data Analysts or scientists can log in to Azure Synapse Studio to:
- Further enhance the data.
- Analyze to gain business insight.
- Train the machine learning model.
- Business applications connect to a serverless SQL pool and use the data to support other business operation requirements.
- Azure Pipelines runs the CI/CD process that automatically builds, tests, and deploys the solution. It’s designed to minimize human intervention during the deployment process.
Components
The following are the key components in this data lakehouse solution:
Alternatives
- If you need real-time data processing you can, instead of storing individual files on the data landing zone, use Apache Structured Streaming to receive the data stream from Event Hubs and process it.
- If the data has a complex structure and requires complex SQL queries, consider storing it in a dedicated SQL pool instead of a serverless SQL pool.
- If the data contains many hierarchical data structures—for example, it has a large JSON structure—you might want to store it in Azure Synapse Data Explorer.
High-level design
This solution focuses on the security design and implementation practices in the architecture. Serverless SQL pool, Apache Spark in Azure Synapse, Azure Synapse pipelines, Data Lake Storage, and Power BI are the key services used to implement the data lakehouse pattern.
Here is the high-level solution design architecture:

Choose security focus
We started the security design by using the Threat Modeling tool. The tool helped us:
- Communicate with system stakeholders about potential risks.
- Define the trust boundary in the system.
Based on the threat modeling results, we made the following security areas our top priorities:
- Identity and Access control
- Network protection
- DevOps security
We designed the security features and infrastructure changes to protect the system by mitigating the key security risks identified with these top priorities.
For details of what should be checked and considered, see:
Network and asset protection plan
One of the key security principles in the Cloud Adoption Framework is the Zero Trust principle: when designing security for any component or system, reduce the risk of attackers expanding their access by assuming that other resources in the organization are compromised.
Based on the threat modeling result, the solution adopts the micro-segmentation deployment recommendation in zero-trust and defines several security boundaries. Azure Virtual Network and Azure Synapse data exfiltration protection are the key technologies that are used to implement the security boundary in order to protect data assets and critical components.
Because Azure Synapse is composed of several different technologies, we need to:
- Identify the components of Synapse and related services that are used in the project.
Azure Synapse is a versatile data platform that can handle many different data processing needs. First, we need to decide which components in Azure Synapse are used in the project so we can plan how to protect them. We also need to determine what other services communicate with these Azure Synapse components.
In the data lakehouse architecture, the key components are:
- Azure Synapse serverless SQL
- Apache Spark in Azure Synapse
- Azure Synapse pipelines
- Data Lake Storage
- Azure DevOps
- Define the legal communication behaviors between the components.
We need to define the allowed communication behaviors between the components. For example, do we want the Spark engine to communicate with the dedicated SQL instance directly, or do we want it to communicate through a proxy such as Azure Synapse Data Integration pipeline or Data Lake Storage?
Based on the Zero Trust principle, we block communication if there’s no business need for the interaction. For example, we block a Spark engine that’s in an unknown tenant from directly communicating with Data Lake storage.
- Choose the proper security solution to enforce the defined communication behaviors.
In Azure, several security technologies can enforce the defined service communication behaviors. For example, in Data Lake Storage you can use an IP address allowlist to control access to a data lake, but you can also choose which virtual networks, Azure services, and resource instances are allowed. Each protection method provides different security protection. Choose based on business needs and environmental limitations. The configuration used in this solution is described in the next section.
- Implement threat detection and advanced defenses for critical resources.
For critical resources, it’s best to implement threat detection and advanced defenses. The services help identify threats and trigger alerts, so the system can notify users about security breaches.
Consider the following techniques to better protect networks and assets:
- Deploy perimeter networks to provide security zones for data pipelines
When a data pipeline workload requires access to external data and the data landing zone, it’s best to implement a perimeter network and separate it with an extract, transform, and load (ETL) pipeline.
- Enable Defender for Cloud for all storage accounts
Defender for Cloud triggers security alerts when it detects unusual and potentially harmful attempts to access or exploit storage accounts. For more information, see Configure Microsoft Defender for Storage.
- Lock a storage account to prevent malicious deletion or configuration changes
For more information, see Apply an Azure Resource Manager lock to a storage account.
Architecture with network and asset protection
The following table describes the defined communication behaviors and security technologies chosen for this solution. The choices were based on the methods discussed in Network and asset protection plan.
| From (Client) | To (Service) | Behavior | Configuration | Notes | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | Deny all | Firewall rule – Default deny | Default: ‘Deny’ | Firewall rule – Default Deny |
| Azure Synapse Pipeline/Spark | Data Lake Storage | Allow (instance) | Virtual network – Managed private endpoint (Data Lake Storage) | ||
| Synapse SQL | Data Lake Storage | Allow (instance) | Firewall rule – Resource instances (Synapse SQL) | Synapse SQL needs to access Data Lake Storage using managed identities | |
| Azure Pipelines agent | Data Lake Storage | Allow (instance) | Firewall rule – Selected virtual networks Service endpoint – Storage |
For integration testing bypass: ‘AzureServices’ (firewall rule) |
|
| Internet | Synapse workspace | Deny all | Firewall rule | ||
| Azure Pipelines agent | Synapse workspace | Allow (instance) | Virtual network – private endpoint | Requires three private endpoints (Dev, serverless SQL, and dedicated SQL) | |
| Synapse managed virtual network | Internet or unauthorized Azure tenant | Deny all | Virtual network – Synapse data exfiltration protection | ||
| Synapse pipeline/Spark | Key Vault | Allow (instance) | Virtual network – Managed private endpoint (Key Vault) | Default: ‘Deny’ | |
| Azure Pipelines agent | Key Vault | Allow (instance) | Firewall rule – Selected virtual networks * Service endpoint – Key Vault |
bypass: ‘AzureServices’ (firewall rule) | |
| Azure Functions | Synapse serverless SQL | Allow (instance) | Virtual network – Private endpoint (Synapse serverless SQL) | ||
| Synapse pipeline/Spark | Azure Monitor | Allow (instance) | Virtual network – Private endpoint (Azure Monitor) |
For example, in the plan we want to:
- Create an Azure Synapse workspace with a managed virtual network.
- Secure data egress from Azure Synapse workspaces by using Azure Synapse workspaces Data exfiltration protection.
- Manage the list of approved Azure AD tenants for the Azure Synapse workspace.
- Configure network rules to grant traffic to the Storage account from selected virtual networks, access only, and disable public network access.
- Use Managed Private Endpoints to connect the virtual network that’s managed by Azure Synapse to the data lake.
- Use Resource Instance to securely connect Azure Synapse SQL to the data lake.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that you can use to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Security
For information about the security pillar of the Well-Architected Framework, see Security.
Identity and access control
There are several components in the system. Each one requires a different identity and access management (IAM) configuration. These configurations need to collaborate to provide a streamlined user experience. Therefore, we use the following design guidance when we implement identity and access control.
- Choose an identity solution for different access control layers
- There are four different identity solutions in the system.
- SQL account (SQL Server)
- Service principal (Azure AD)
- Managed identity (Azure AD)
- User Account (Azure AD)
- There are four different access control layers in the system.
- The application access layer: choose the identity solution for AP Roles.
- The Azure Synapse DB/Table access layer: choose the identity solution for roles in databases.
- Azure Synapse access external resource layer: choose the identity solution to access external resources.
- Data Lake Storage access layer: choose the identity solution to control file access in the storage.
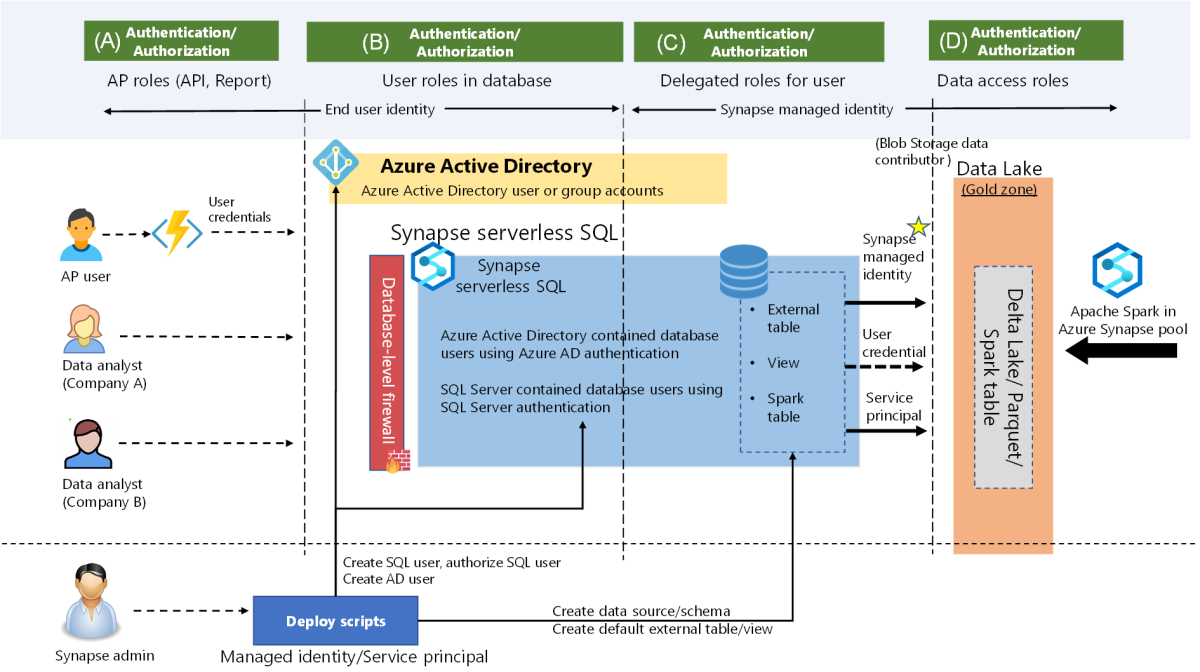
A crucial part of identity and access control is choosing the right identity solution for each access control layer. The security design principles of the Azure Well-Architected Framework suggest using native controls and driving simplicity. Therefore, this solution uses the Azure AD User Account of the end user in the application and Azure Synapse DB access layers. It leverages the native first-party IAM solutions and provides fine-grained access control. The Azure Synapse access external resource layer and Data Lake access layer use managed identity in Azure Synapse to simplify the authorization process.
- There are four different identity solutions in the system.
- Consider least-privileged access
A Zero Trust guiding principle suggests providing just-in-time and just-enough access to critical resources. See Azure AD Privileged Identity Management (PIM) to enhance security in the future.
- Protect linked service
Linked services define the connection information that’s needed for a service to connect to external resources. It’s important to secure linked services configurations.

Security score assessment and threat detection
To understand the security status of the system, the solution uses Microsoft Defender for Cloud to assess the infrastructure security and detect security issues. Microsoft Defender for Cloud is a tool for security posture management and threat protection. It can protect workloads running in Azure, hybrid, and other cloud platforms.

You automatically enable Defender for Cloud’s free plan on all your Azure subscriptions when you first visit the Defender for Cloud pages in the Azure portal. We strongly recommend that you enable it to get your Cloud security posture evaluation and suggestions. Microsoft Defender for Cloud will provide your security score and some security hardening guidance for your subscriptions.
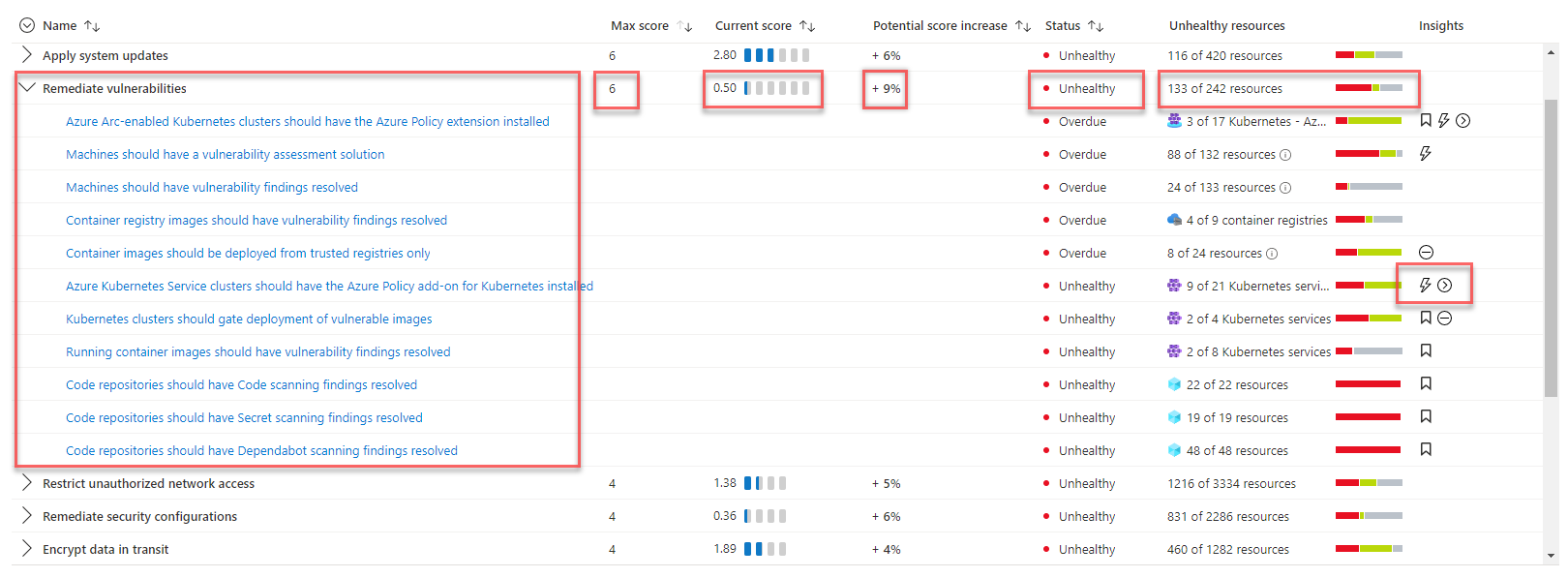
If the solution needs advanced security management and threat detection capabilities such as detection and alerting of suspicious activities, you can enable cloud workload protection individually for different resources.
Cost optimization
For information about the cost optimization pillar of the Well-Architected Framework, see Cost optimization.
A key benefit of the data lakehouse solution is its cost-efficiency and scalable architecture. Most components in the solution use consumption-based billing and will autoscale. In this solution, all data is stored in Data Lake Storage. You only pay to store the data if you don’t run any queries or process data.
Pricing for this solution depends on the usage of the following key resources:
- Azure Synapse Serverless SQL: use consumption-based billing, pay only for what you use.
- Apache Spark in Azure Synapse: use consumption-based billing, pay only for what you use.
- Azure Synapse Pipelines: use consumption-based billing, pay only for what you use.
- Azure Data Lakes: use consumption-based billing, pay only for what you use.
- Power BI: the cost is based on which license you purchase.
- Private Link: use consumption-based billing, pay only for what you use.
Different security protection solutions have different cost modes. You should choose the security solution based on your business needs and solution costs.
You can use the Azure Pricing Calculator to estimate the cost of the solution.
Operational excellence
For information about the operational excellence pillar of the Well-Architected Framework, see Operational excellence.
Use a virtual network enabled self-hosted pipeline agent for CI/CD services
The default Azure DevOps pipeline agent doesn’t support virtual network communication because it uses a very wide IP address range. This solution implements an Azure DevOps self-hosted agent in the virtual network so that the DevOps processes can smoothly communicate with the other services in the solution. The connection strings and secrets for running the CI/CD services are stored in an independent key vault. During the deployment process, the self-hosted agent accesses the key vault in the core data zone to update resource configurations and secrets. For more information, see the Use separate key vaults document. This solution also uses VM scale sets to ensure that the DevOps engine can automatically scale up and down based on the workload.

Implement infrastructure security scanning and security smoke testing in the CI/CD pipeline
A static analysis tool for scanning infrastructure as code (IaC) files can help detect and prevent misconfigurations that can lead to security or compliance problems. Security smoke testing ensures that the vital system security measures are successfully enabled, protecting against deployment failures.
- Use a static analysis tool to scan infrastructure as code (IaC) templates to detect and prevent misconfigurations that can lead to security or compliance problems. Use tools such as Checkov or Terrascan to detect and prevent security risks.
- Make sure the CD pipeline correctly handles deployment failures. Any deployment failure related to security features should be treated as a critical failure. The pipeline should retry the failed action or hold the deployment.
- Validate the security measures in the deployment pipeline by running security smoke testing. The security smoke testing, such as validating the configuration status of deployed resources or testing cases that examine critical security scenarios, can ensure that the security design is working as expected.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
Other contributors:
- Ian Chen | PRINCIPAL SOFTWARE ENGINEER LEAD
- Jose Contreras | PRINCIPAL SOFTWARE ENGINEERING
- Roy Chan | PRINCIPAL SOFTWARE ENGINEER MANAGER
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.