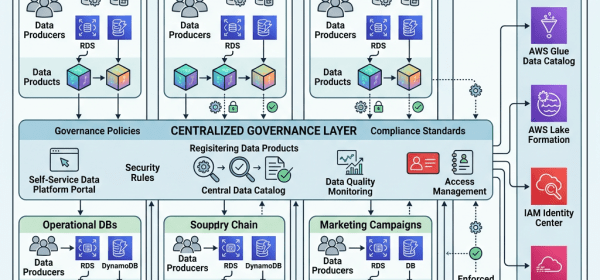
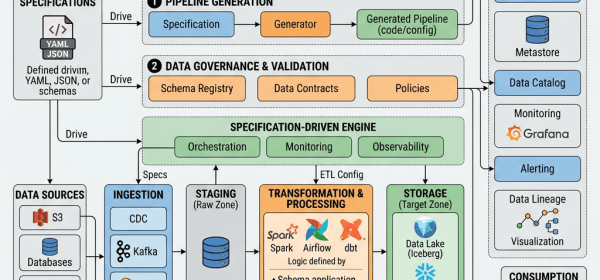
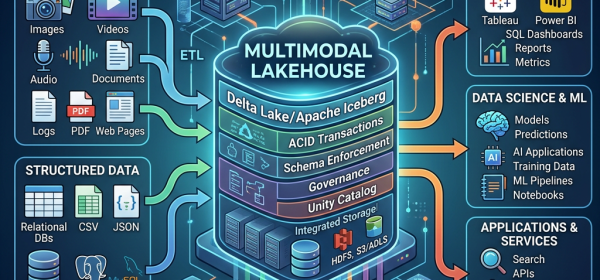
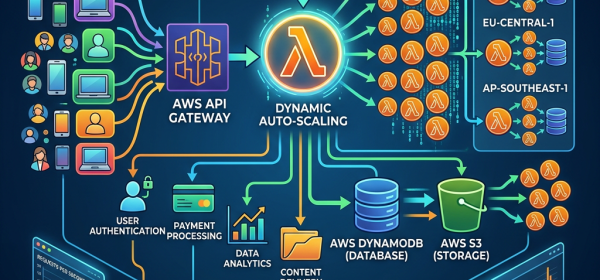
Organizations using Amazon OpenSearch Service for time series data face challenges such as query latency and management overhead from growing datasets. Implementing data streams with Index State Management (ISM) automates data lifecycle management, improving performance and reducing costs. This solution optimizes data distribution and transitions to lower-cost storage tiers efficiently.