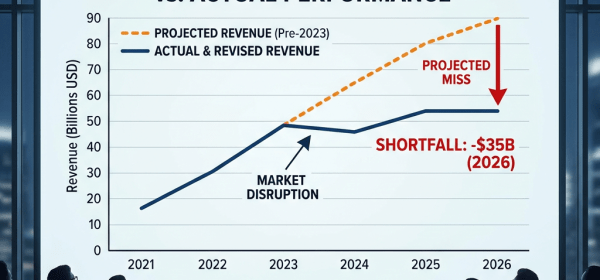
Cornell Tech researchers Yifan He and Jae-sun Seo developed an optical receiver that modifies memory using light, enhancing AI model efficiency. By employing digital light matrices instead of traditional analog circuits, their approach could decrease energy demands in data transfer for AI systems, particularly in robotics and edge applications, though commercialization remains a challenge.