Starting today, you can use Kinesis Data Firehose to send CloudWatch Metrics and Logs directly to the Dynatrace observability platform to perform your explorations and analysis. Figure 2 – Amazon Kinesis Data

Starting today, you can use Kinesis Data Firehose to send CloudWatch Metrics and Logs directly to the Dynatrace observability platform to perform your explorations and analysis. Figure 2 – Amazon Kinesis Data
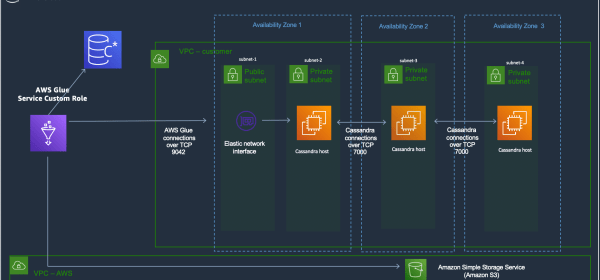
In this post, we’ll take you through William Hill’s journey of building the migration pipeline from scratch to migrate the Apache Cassandra workload to Amazon Keyspaces by leveraging AWS Glue ETL with
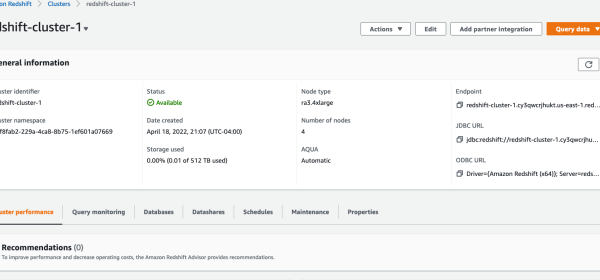
Amazon Redshift Audit Logging is good for troubleshooting, monitoring, and security purposes, making it possible to determine suspicious queries by checking the connections and user logs to see who is
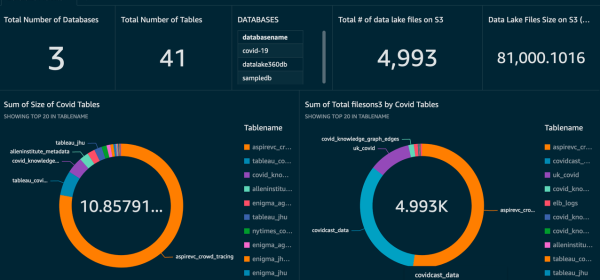
With the availability of metrics related to dashboard views, visual load times, and data ingestion details into SPICE (the QuickSight in-memory data store), developers and administrators can ensure that end-users of
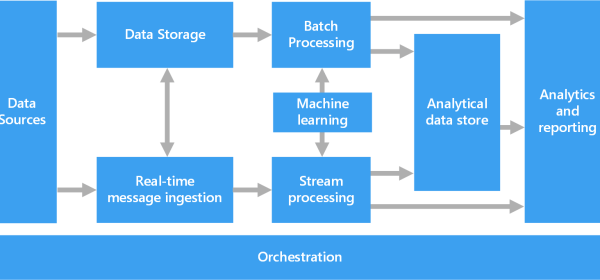
A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional database systems. The threshold at which organizations enter into the big data

A data warehouse is a centralized repository of integrated data from one or more disparate sources. Data warehouses store current and historical data and are used for reporting and analysis of the data. Download a

The solution described in this article combines a range of Azure services that will ingest, store, process, enrich, and serve data and insights from different sources (structured, semi-structured, unstructured, and streaming). Structured and unstructured data stored in your Synapse
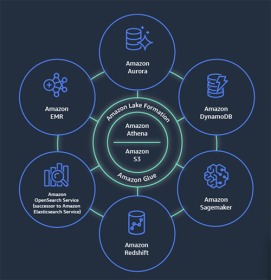
It’s a scalable and cost-efficient way to read large DynamoDB table data in AWS Glue ETL jobs. Instead, the new AWS Glue DynamoDB export connector reads DynamoDB data from the snapshot, which is exported
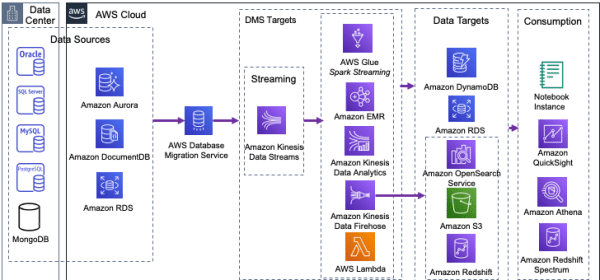
The following diagram illustrates that AWS DMS can use many of the most popular database engines as a source for data replication to a Kinesis Data Streams target. In the following steps, you configure your
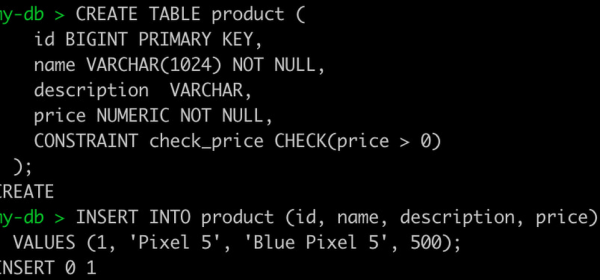
For applications, we’ve updated our native, open-source clients to easily send PostgreSQL-dialect queries to Spanner databases from Java, Go, Python, Node.js, PHP, Ruby, C#, or C++ via Spanner’s existing globally
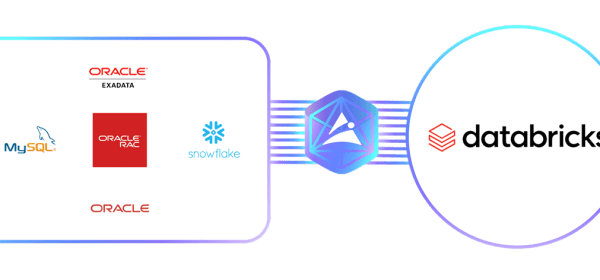
Arcion enables real-time data ingestion from transactional databases like Oracle and MySQL into the Databricks Lakehouse Platform with their fully-managed cloud service. We are thrilled to announce that Arcion, the
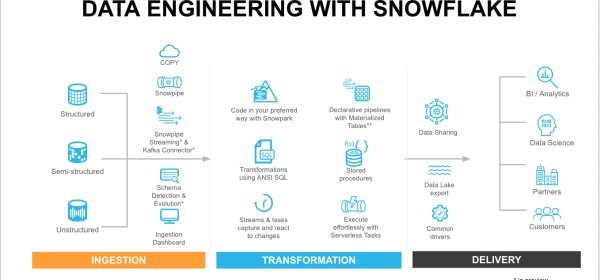
Alongside our extensive ecosystem of ETL and data ingestion partners who help move data into the Data Cloud, Snowflake offers a wide range of first party methods to meet the different data pipeline needs from batch
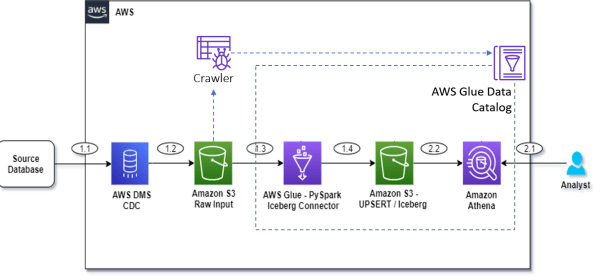
To solve this use case, we present the following simple architecture that integrates Amazon S3 for the data lake, AWS Glue with the Apache Iceberg connector for ETL (extract, transform, and load), and Athena for
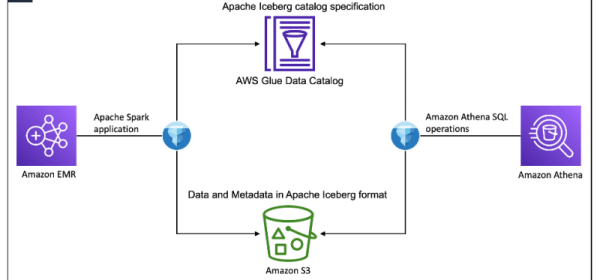
In this post, we show you how to use Amazon EMR Spark to create an Iceberg table, load sample books review data, and use Athena to query, perform schema evolution, row-level update and delete, and time travel,