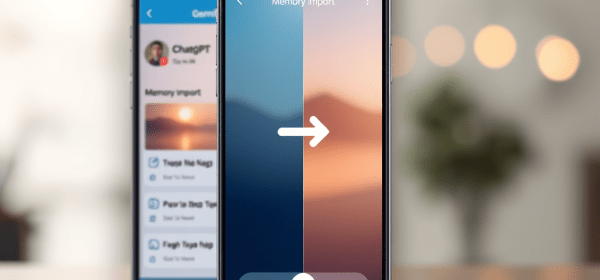
Society is gradually outsourcing cognitive tasks to external aids like AI, risking the erosion of judgment and critical thinking. While generative AI enhances productivity, it obscures the distinction between genuine understanding and superficial fluency. The cultural challenge lies in preserving human judgment amidst this dependency, particularly in education.