In this post, we introduce the latest Admin Console, an AWS packaged solution that you can easily deploy and use to create a usage and inventory dashboard for your QuickSight assets. Based on the file in

In this post, we introduce the latest Admin Console, an AWS packaged solution that you can easily deploy and use to create a usage and inventory dashboard for your QuickSight assets. Based on the file in
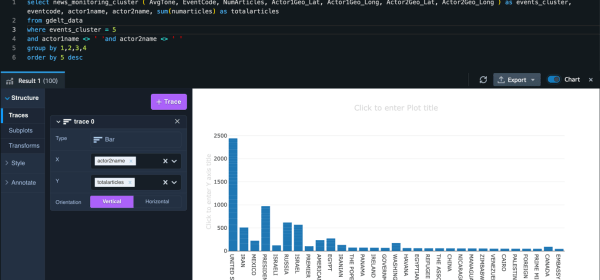
For our use case, a data scientist wants to perform unsupervised learning with Amazon Redshift ML by creating a machine learning (ML) model, and then generate insights from the dataset, create multiple versions of
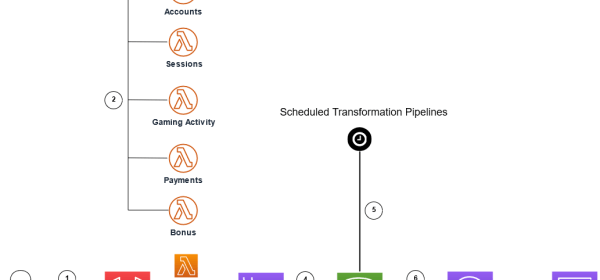
To address these challenges, The Mill Adventure chose to build a modern data platform on AWS that was not only capable of providing timely and meaningful business insights for the iGaming industry, but also efficiently

In this section, you pull technical metadata from the AWS Glue Data Catalog and Amazon Redshift using the DataHub web interface, Python, and the DataHub CLI. In this post, we focus on how to populate technical

You can automate the workgroup and namespace management operations using the Redshift Serverless API, the AWS Command Line Interface (AWS CLI), or AWS CloudFormation, which we demonstrate in
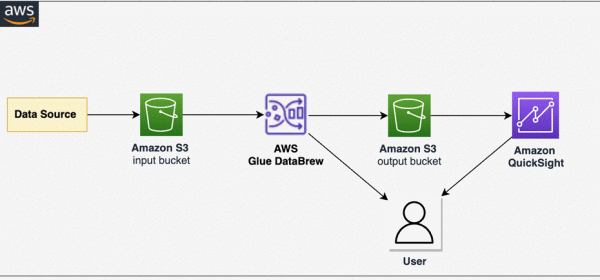
Permissions to create the DataBrew dataset, project, and jobs; S3 buckets; and QuickSight dashboards To illustrate the DataBrew functionality to support data analysis for nested JSON files, we use a

We create an MSK Connect custom plugin and IAM role, and then replicate the data between two existing Amazon Managed Streaming for Apache Kafka (Amazon MSK) clusters. This solution can help Amazon
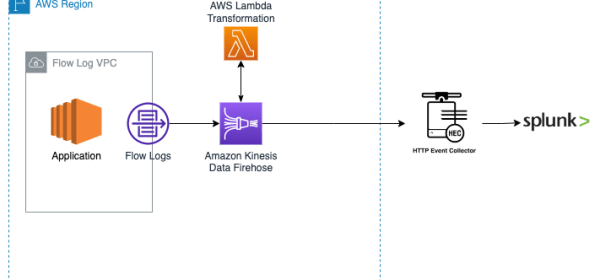
This delivery stream has an AWS Lambda function enabled for data transformation and has destination settings to point to the Splunk endpoint along with an HTTP Event Collector (HEC) token. In this post,

Apache Kafka is an open-source, high-performance, fault-tolerant, and scalable platform for building real-time streaming data pipelines and applications. If the MSK Serverless cluster is provisioned within their

Specifically, an end-to-end machine learning application that is fully customizable, uses all relevant organizational data, produces near real-time pipeline predictions (as required by business cadence), and is

In our second use case, we run an Athena federated query on Aurora MySQL and Amazon Redshift data stores. For our third use case, we run an Athena federated query on Aurora MySQL, Amazon Redshift, and

All software applications and systems are purchased to automate business processes, and it is the scalable and flexible nature of Data Vault that allows us to capture the business process outcomes into hub,

AWS Glue workflows are created and updated after manually running the resources deployment flow in Step Functions. You can further customize the AWS Glue blueprints to make your own multi-step data pipelines to

If the AWS account you use to follow this post uses AWS Lake Formation to manage permissions on the AWS Glue Data Catalog, make sure that you log in as a user with access to create databases and tables. The goal