You can grant Lake Formation permissions on the Delta tables created by the crawler to AWS principals that then query through Athena and Redshift Spectrum to access data in Delta tables. The AWS Glue crawler

You can grant Lake Formation permissions on the Delta tables created by the crawler to AWS principals that then query through Athena and Redshift Spectrum to access data in Delta tables. The AWS Glue crawler
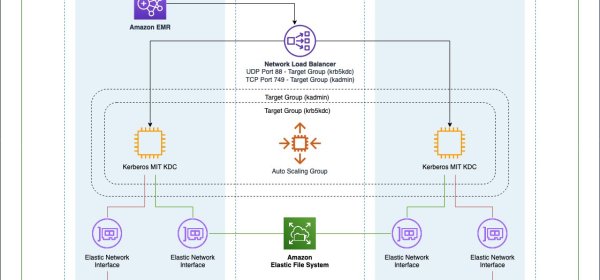
When creating an Amazon EMR security configuration, you’re asked to choose between a cluster-dedicated KDC or an external KDC, so it’s important to understand the benefits and limits of each solution. Considering the case in which the KDC is shared with other EMR clusters
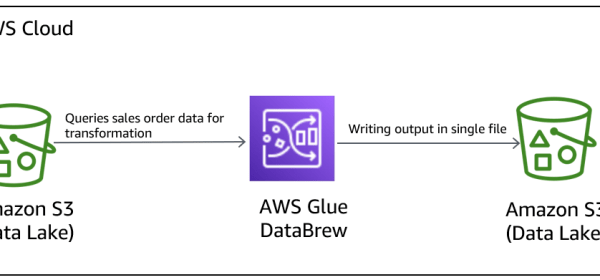
You can now choose single or multiple output files instead of autogenerated files for your DataBrew recipe jobs. In this post, we walk you through how to connect and transform data from an Amazon Simple
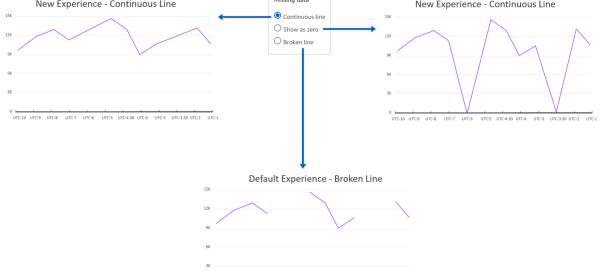
In such cases, instead of displaying a broken line chart that skips Sunday, you may want to show a continuous trend by directly connecting Saturday to Monday, hiding the fact that Sunday isn’t operational.
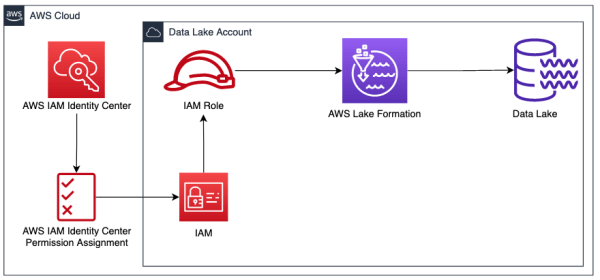
Integrating Lake Formation with IAM Identity Center can help you manage data access at the organization level, consolidating AWS account and data lake authentication and authorization. When the permission sets are assigned to your data lake account, IAM Identity

When you store data in Snowflake, your experience is drastically simplified because many storage management functionalities are handled automatically. Snowflake simplifies managing privileges to your
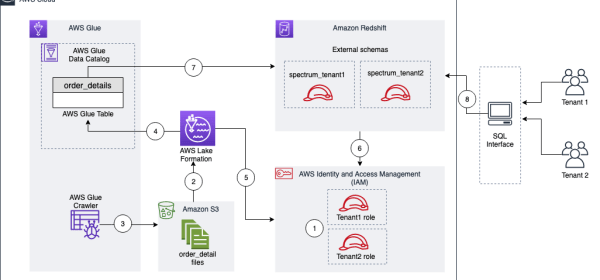
This integration enables you to define data filters in Lake Formation that specify row-level and cell-level access control for users on your data and then query it using Redshift Spectrum. To solve this use case, we

In this post, I guide you through the configuration process and provide Java code samples to secure data in transit on Amazon EMR by storing TLS custom certificates using AWS Secrets Manager . The security

An AWS Glue streaming ETL job consumes the data in near-real time and runs an aggregation that computes how many times a webpage has been unavailable (status code 500 and above) due to an internal error. In
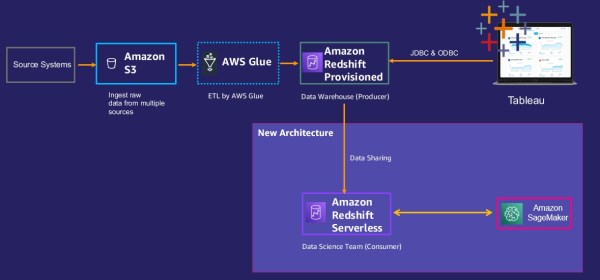
Amazon Redshift Serverless makes it easy to run and scale analytics in seconds without the need to setup and manage data warehouse clusters. To address these issues, they decide to let the data science team create

This integration enables you to define data filters in Lake Formation that specify row-level and cell-level access control for users on your data and then query it using Redshift Spectrum. To solve this use case, we
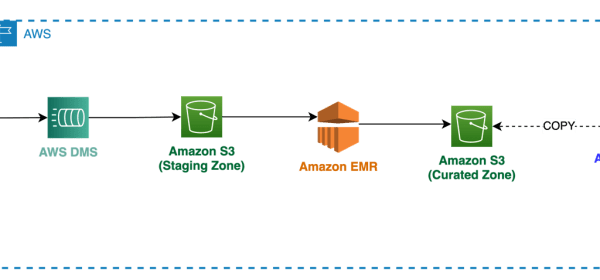
In this example, we use AWS DMS to extract data from an Oracle database with XML BLOB fields and stage the same data in Amazon Simple Storage Service (Amazon S3) in Apache Parquet format. After the
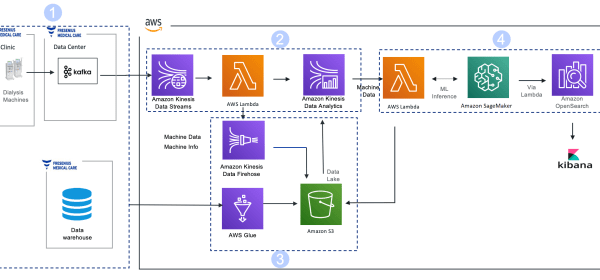
We needed to develop a near-real-time analytics solution that would collect dynamic dialysis machine data every 10 seconds during hemodialysis treatment in near-real time and personalize it to predict

In this post, we show how you can create and configure a dashboard in Amazon Managed Grafana that queries data stored on Amazon S3 using Athena. The solution is comprised of a Grafana dashboard, created in