
You want to enable analytics, data science, or applications with data so you can answer questions, predict outcomes, discover relationships, or grow your business. But to do any of that, data must be stored in a manner to support these outcomes. This may be a simple decision when supporting a small, well-known use case, but it quickly becomes complicated as you scale the data volume, variety, workloads, and use cases.
Simplifying user experience has always been one of the most important design principles we follow at Snowflake , and it very much applies to storage. When you store data in Snowflake, your experience is drastically simplified because many storage management functionalities are handled automatically. This matters because you can trust that your data is secure, reliable, and optimized for fast and efficient access at almost any scale. Let’s dive into the capabilities that make this experience possible.
1. Support for all your data
Many customers have found Snowflake to be a great solution to their data warehousing needs, storing and analyzing their structured and semi-structured data. However, they typically have documents, images, videos, text files, and more that they want to use in tandem with structured and semi-structured data. With Snowflake’s added support for unstructured data, you can store, secure, govern, analyze, and share all data types: structured, semi-structured, and unstructured.

2. Automatic encryption
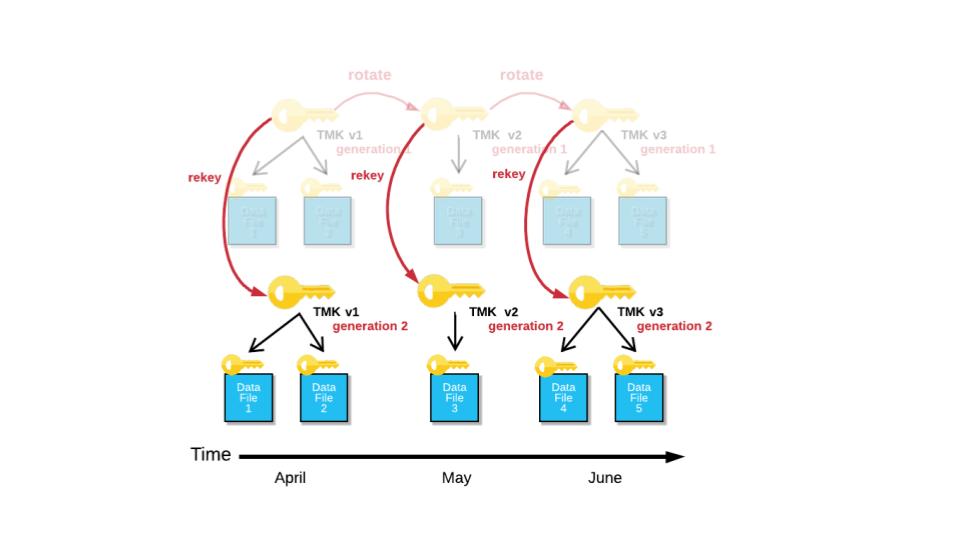
Securing data is critically important, yet can be difficult to manage with many other storage systems. In Snowflake, data is automatically encrypted at rest and in transit. We use best-in-class encryption where each partition in each table is encrypted using separate keys in a hierarchical model, significantly reducing the scope of the data protected by a single key.
Snowflake-managed keys are also automatically rotated every 30 days. Trusting Snowflake to secure your data is a responsibility we take very seriously, which is why we handle security in multiple ways while abstracting away the complexity for you.
3. Automatic partitioning
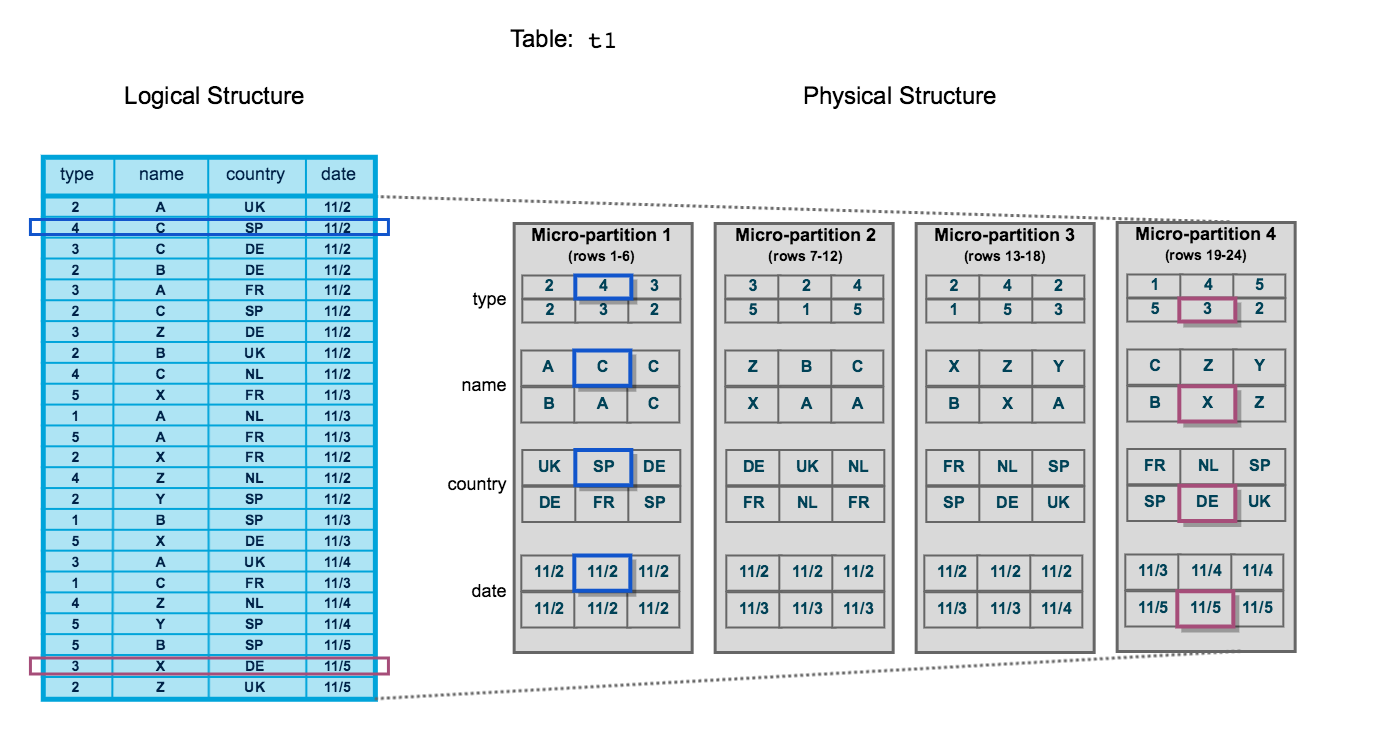
Querying a small amount of data is generally fast, but when the scale of data reaches hundreds of terabytes or petabytes, efficient data partitioning becomes very important. When data is partitioned well, query execution can prune the partitions that don’t need to be scanned and return results quickly. Other storage systems often require you to decide which partitioning keys to use and what folder structure to follow. These decisions become even harder when there are multiple partitioning keys and nested partitions. Moreover, once the data is partitioned, changing the partition keys in the future is a non-starter.
When data is stored in Snowflake, it is automatically partitioned using Snowflake’s unique micro-partition architecture to optimize performance. You don’t have to make any decisions about partition keys or order of keys. DML operations take advantage of underlying micro-partition metadata to simplify table maintenance.
4. Automatic clustering
Typically, data stored in tables is sorted along certain dimensions, such as date. If it is not sorted or sorted on the wrong fields, query performance on those tables is likely to be slower, leaving you with a potentially costly decision for where and how to sort.
Automatic clustering—an optional service that consumes Snowflake credits—seamlessly and continually manages all reclustering of tables as needed. Snowflake collects clustering metadata for each micro-partition as data is loaded into a table and uses this information to avoid unnecessary scanning of micro-partitions for queries. Fewer scans means faster performance and this translates to lower compute cost. As you perform DML on tables, Snowflake monitors and evaluates whether you would benefit from reclustering, while you retain the ability to suspend and resume at any time.
5. Automatic compression
Data lakes using cloud object storage are a common solution to accommodate large volumes of data at low cost, and compression can help you save even more on storage costs. There are multiple compression algorithms available, but choose wisely. Some algorithms may provide better compression but are slow to decompress, which degrades query performance. Some algorithms provide optimal results for compressing integer or decimal columns, but are not so great for text-based columns (and vice versa).
When you store data in Snowflake, you don’t have to make these complex decisions. Data is automatically compressed using state-of-the-art compression algorithms. Snowflake uses various algorithms that are optimized based on column data types, which can provide compression gains. Unlike other object storage services, Snowflake storage costs are calculated after compression. Therefore, the compression gains translate to direct savings on storage costs. And because compression results in a smaller storage representation, queries are scanning less data, producing results faster, and using less compute resources—which also translates to better economics for customers. Any improvements to the compression algorithm in Snowflake are automatically applied for all customers, further lowering their costs without requiring any action from them.
6. Granular access controls
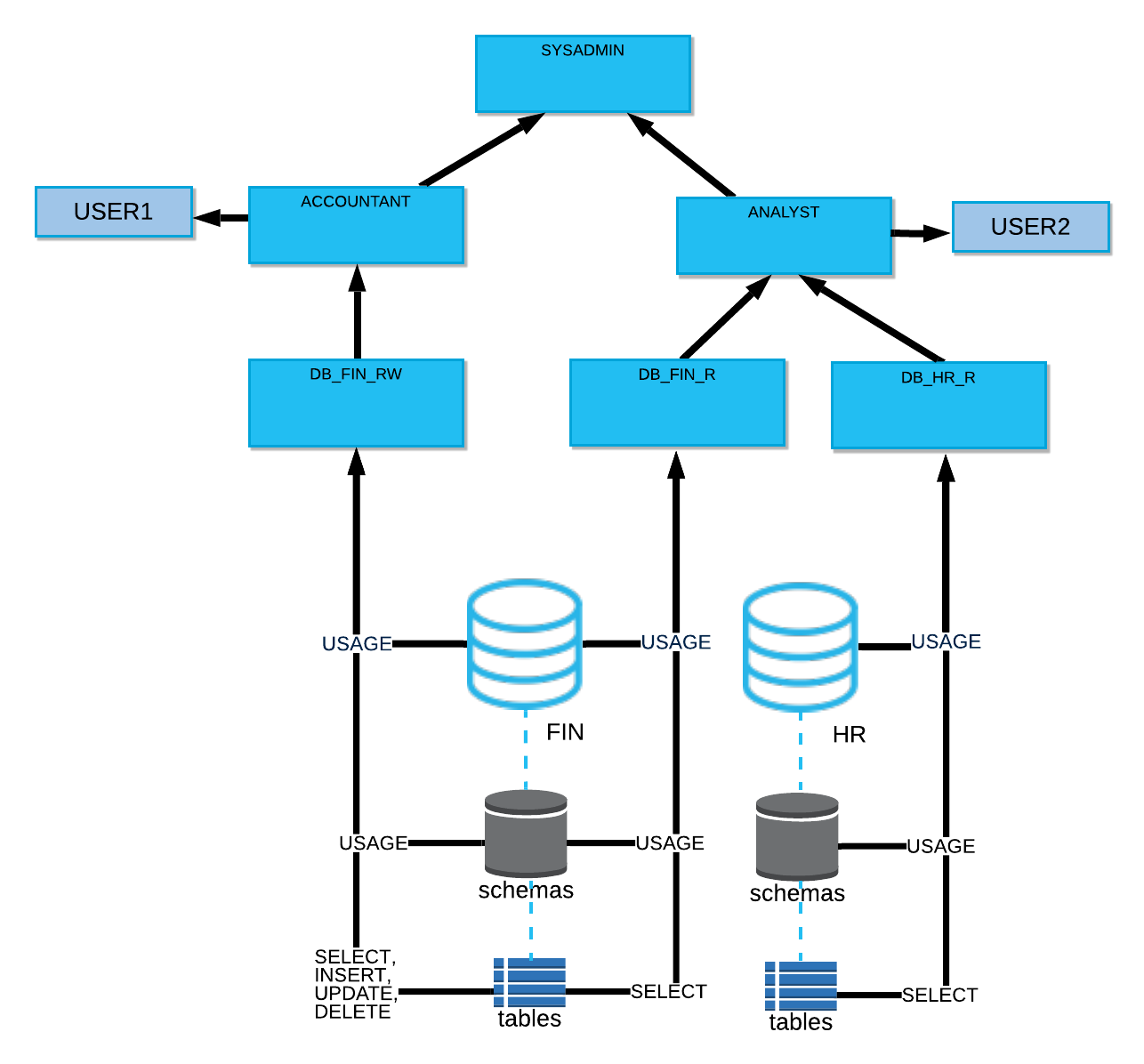
Governance is an extremely important requirement to consider when designing a data lake. When you implement a data lake on cloud storage services, you need to secure access to the data using object-level permissions. Cloud storage provider services offer IAM roles and privileges, which provide permissions to read, write, and delete blobs or files stored in buckets. As the scale of your data sets increases, managing these privileges can quickly get very complex and cumbersome. Moreover, if you replicate or migrate your data lake to a different cloud, you have to translate these privileges to a different cloud’s IAM platform—a non-trivial task even for the most experienced cloud administrators.
Snowflake simplifies managing privileges to your data by providing role-based access control on table objects, which automatically translate to privileges on underlying micro-partitions. Table owners can grant privileges to end users using commands that work with the exact same syntax irrespective of the underlying cloud provider on which Snowflake is deployed. Even if your tables are replicated cross-cloud, the grants are automatically replicated and kept in sync with the Snowflake service.
7. Automatic versioning, Time Travel, and Fail-Safe
As you perform workloads and operations against data in storage, you’ll likely want a contingency plan for accidental deletes of tables or entire databases. For data stored in Snowflake, you don’t have to worry about accidental deletion or updating of data because of automatic Time Travel and Fail-Safe capabilities. You can travel back in time to see the state of data and objects in the past and, if necessary, UNDROP objects.

8. Cross-cloud replication
Although Time Travel is very useful, it’s not enough to constitute a thorough contingency for full business continuity, whether an event is planned or unplanned. By electing to store in cloud storage, you’re often confined to the availability of that particular cloud and region. However, storing data in Snowflake helps you better prepare for business continuity and disaster recovery with replication, failover, and client redirect capabilities across regions and across cloud platforms.
This means that in the case of an outage in one region or cloud platform, you can promote secondary replica account objects in another region or cloud platform to serve as read-write primary objects. With Snowflake, you can also move your account to a different region or cloud platform without disruption, which is especially useful during mergers, acquisitions, or changes in cloud strategy, for example.
Choosing the right storage for the job
We’ve laid out reasons for building a data lake and storing data in Snowflake, and we want to give our customers the flexibility to build architectures that best suit their needs and use cases. With that in mind, we provide non-mutually exclusive options by building different storage products to support different patterns and use cases. And as this blog post illustrates, use cases optimizing for performance, security, and ease of use should strongly consider storing data in Snowflake.
Next steps
Storage is a fundamental piece of data architecture that can be complicated. Snowflake strives to simplify this situation with automation. If you’re interested in exploring further, check out these resources:
- If you’re considering a data lake migration, this ebook outlines seven parameters you and your company should consider when planning your initiative.
To learn best practices for batch and continuous ingestion with Snowflake, read this blog post.
The post 8 Reasons to Build Your Cloud Data Lake on Snowflake appeared first on Snowflake.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.