Amazon Security Lake centralizes access and management of your security data by aggregating security event logs from AWS environments, other cloud providers, on premise infrastructure, and other software as a
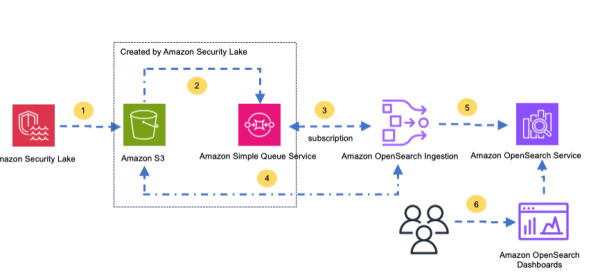
Amazon Security Lake centralizes access and management of your security data by aggregating security event logs from AWS environments, other cloud providers, on premise infrastructure, and other software as a
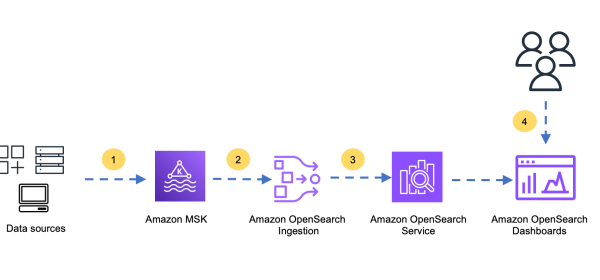
To read from Amazon MSK and write to Amazon OpenSearch Service, you need to create a an AWS Identity and Access Management (IAM) role used by Amazon OpenSearch Ingestion. The pipeline role now has

The following sections explore the implementation of DPPM along the lines of people, process, and technology, as well as describing the key characteristics of data products—scope, value, risk, uniqueness, and
This solution uses an AWS Lambda function to extract storage and shard distribution metadata from your OpenSearch Service domain, calculates the level of skew, and then pushes this information to CloudWatch metrics so that you can easily monitor, alert, and respond. In this post, we
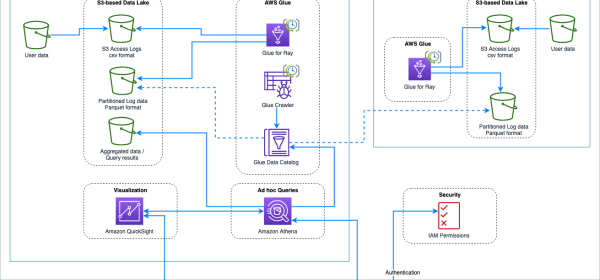
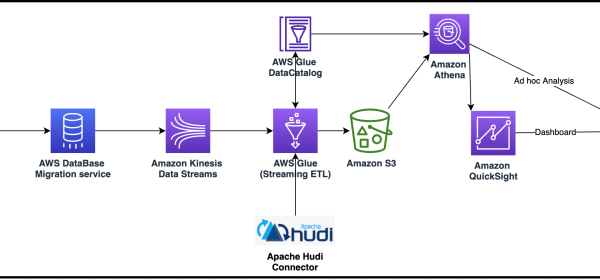
We will partition and format the server access logs with Amazon Web Services (AWS) Glue, a serverless data integration service, to generate a catalog for access logs and create dashboards for insights.
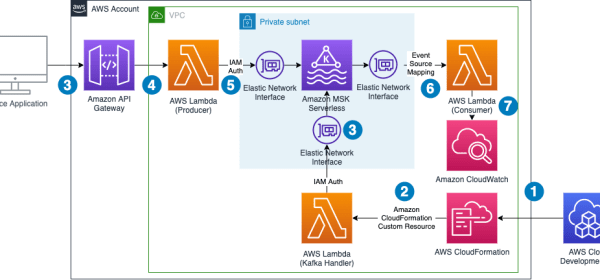
This creates a demo environment, including an MSK Serverless cluster, three Lambda functions, and an API Gateway that consumes the messages from the Kafka topic. API Gateway takes in producer requests

Depending on the size and scale of your workload, you can use Azure Functions as a code-first integration tool to perform text-processing steps, like text summarization on extracted data. Use Azure OpenAI to
Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services…. Raj provided technical expertise and leadership in building data engineering, big data analytics, business
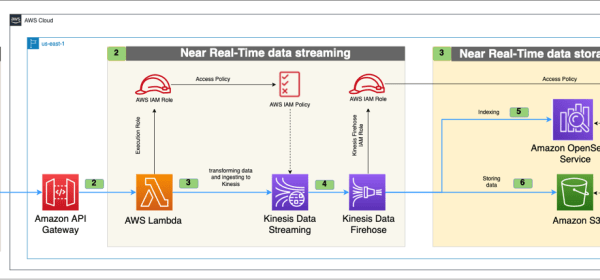
GitHub as the data source, employs Amazon Simple Storage Service (Amazon S3) for scalable storage, manages APIs with Amazon API Gateway, performs serverless computing using AWS Lambda, and facilitates data streaming and ETL (extract, transform, and load) processes through Amazon Kinesis Data Streams and Amazon Kinesis Data Firehose.
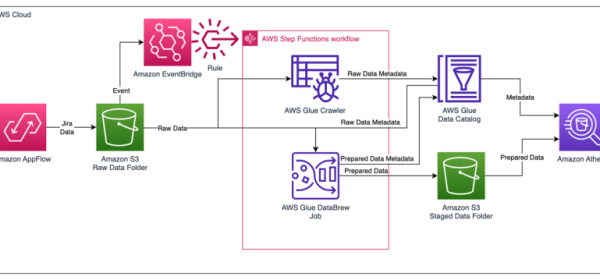
Amazon AppFlow provides software as a service (SaaS) integration with Jira Cloud to load the data into your AWS account. This post shows you how to use Amazon AppFlow and AWS Glue to create a fully automated

About the Authors Saurabh Bhutyani is a Principal Big Data Specialist Solutions Architect at AWS…. Big Data Architect on Amazon Athena.

Apache Flink and Apache Spark are both open-source, distributed data processing frameworks used widely for big data processing and analytics. Spark is known for its
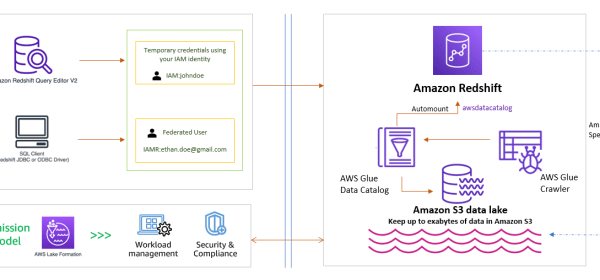
Amazon Redshift is helping tens of thousands of customers manage analytics at scale. Amazon Redshift offers a powerful analytics solution that provides access to insights for users of all skill levels. You can take advantage of the following benefits:
This function reads the DICOM files from Blob Storage and then parses and ingests the metadata into a single flat Azure Data Explorer table. The clinical data pipeline processes the clinical files and ingests the data into the same