Today, we are pleased to announce a new AWS Glue connector for Google Cloud Storage that allows you to move data bi-directionally between Google Cloud Storage and Amazon Simple Storage Service (Amazon S3).
We’ve seen that there is a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. One of the data sources you can now quickly integrate with is Google Cloud Storage, a managed service for storing both unstructured data and structured data. With this connector, you can bring the data from Google Cloud Storage to Amazon S3.
In this post, we go over how the new connector works, introduce the connector’s functions, and provide you with key steps to set it up. We provide you with prerequisites, share how to subscribe to this connector in AWS Marketplace, and describe how to create and run AWS Glue for Apache Spark jobs with it.
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue natively integrates with various data stores such as MySQL, PostgreSQL, MongoDB, and Apache Kafka, along with AWS data stores such as Amazon S3, Amazon Redshift, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB, and Amazon S3. AWS Glue Marketplace connectors allow you to discover and integrate additional data sources, such as software as a service (SaaS) applications and your custom data sources. With just a few clicks, you can search and select connectors from AWS Marketplace and begin your data preparation workflow in minutes.
How the connector works
This connector relies on the Spark DataSource API in AWS Glue and calls Hadoop’s FileSystem interface. The latter has implemented libraries for reading and writing various distributed or traditional storage. This connector also includes the Google Cloud Storage Connector for Hadoop, which lets you run Apache Hadoop or Apache Spark jobs directly on data in Google Cloud Storage. AWS Glue loads the library from the Amazon Elastic Container Registry (Amazon ECR) repository during initialization (as a connector), reads the connection credentials using AWS Secrets Manager, and reads data source configurations from input parameters. When AWS Glue has internet access, the Spark job in AWS Glue can read from and write to Google Cloud Storage.
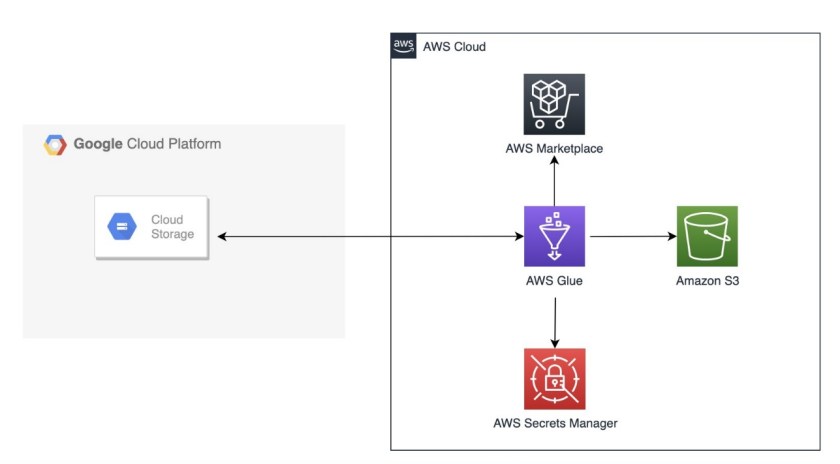
Solution overview
The following architecture diagram shows how AWS Glue connects to Google Cloud Storage for data ingestion.

In the following sections, we show you how to create a new secret for Google Cloud Storage in Secrets Manager, subscribe to the AWS Glue connector, and move data from Google Cloud Storage to Amazon S3.
Prerequisites
You need the following prerequisites:
- An account in Google Cloud and your data path in Google Cloud Storage. Prepare the GCP account keys file in advance and upload them to the S3 bucket. For instructions, refer to Create a service account key.
- A Secrets Manager secret to store a Google Cloud secret.
- An AWS Identity and Access Management (IAM) role for the AWS Glue job with the following policies:
- AWSGlueServiceRole, which allows the AWS Glue service role access to related services.
- AmazonEC2ContainerRegistryReadOnly, which provides read-only access to Amazon EC2 Container Registry repositories. This policy is for using AWS Marketplace’s connector libraries.
- A Secrets Manager policy, which provides read access to the secret in Secrets Manager.
- An S3 bucket policy for the S3 bucket that you need to load ETL (extract, transform, and load) data from Google Cloud Storage.
We assume that you are already familiar with the key concepts of Secrets Manager, IAM, and AWS Glue. Regarding IAM, these roles should be granted the permissions needed to communicate with AWS services and nothing more, according to the principle of least privilege.
Create a new secret for Google Cloud Storage in Secrets Manager
Complete the following steps to create a secret in Secrets Manager to store the Google Cloud Storage credentials:
- On the Secrets Manager console, choose Store a new secret.
- For Secret type, select Other type of secret.
- Enter your key as
keyS3Uriand the value as your key file in the s3 bucket, for example,s3://keys/project-gcs-connector **.json. 
- Leave the rest of the options at their default.
- Choose Next.
- Provide a name for the secret, such as
googlecloudstorage_credentials. - Follow the rest of the steps to store the secret.
Subscribe to the AWS Glue connector for Google Cloud Storage
To subscribe to the connector, complete the following steps:
- Navigate to the Google Cloud Storage Connector for AWS Glue on AWS Marketplace.
- On the product page for the connector, use the tabs to view information about the connector. If you decide to purchase this connector, choose Continue to Subscribe.

- Review the pricing terms and the seller’s End User License Agreement, then choose Accept Terms.

- Continue to the next step by choosing Continue to Configuration.

- On the Configure this software page, choose the fulfillment options and the version of the connector to use. We have provided two options for the Google Cloud Storage Connector, AWS Glue 3.0 and AWS Glue 4.0. In this example, we focus on AWS Glue 4.0. After selecting Glue 3.0 or Glue 4.0, select corresponding AWS Glue version when you configure the AWS Glue job.
- Choose Continue to Launch.

- On the Launch this software page, you can review the Usage Instructions provided by AWS. When you’re ready to continue, choose Activate the Glue connector in AWS Glue Studio.

The console will display the Create marketplace connection page in AWS Glue Studio.
Move data from Google Cloud Storage to Amazon S3
To move your data to Amazon S3, you must configure the custom connection and then set up an AWS Glue job.
Create a custom connection in AWS Glue
An AWS Glue connection stores connection information for a particular data store, including login credentials, URI strings, virtual private cloud (VPC) information, and more. Complete the following steps to create your connection:
- On the AWS Glue console, choose Connectors in the navigation pane.
- Choose Create connection.
- For Connector, choose Google Cloud Storage Connector for AWS Glue.
- For Name, enter a name for the connection (for example,
GCSConnection). - Enter an optional description.
- For AWS secret, enter the secret you created (
googlecloudstorage_credentials). - Choose Create connection and activate connector.

The connector and connection information is now visible on the Connectors page.
Create an AWS Glue job and configure connection options
Complete the following steps:
- On the AWS Glue console, choose Connectors in the navigation pane.
- Choose the connection you created (
GCSConnection). - Choose Create job.

- On the Node properties tab in the node details pane, enter the following information:
- For Name, enter Google Cloud Storage Connector for AWS Glue. This name should be unique among all the nodes for this job.
- For Node type, choose the Google Cloud Storage Connector.

- On the Data source properties tab, provide the following information:
- For Connection, choose the connection you created (
GCSConnection). - For Key, enter path, and for Value, enter your Google Cloud Storage URI (for example,
gs://bucket/covid-csv-data/). - Enter another key-value pair. For Key, enter
fileFormat. For Value, entercsv, because our sample data is this format.
- For Connection, choose the connection you created (
- On the Job details tab, for IAM Role, choose the IAM role mentioned in the prerequisites.
- For Glue version, choose your AWS Glue version.
- Continue to create your ETL job. For instructions, refer to Creating ETL jobs with AWS Glue Studio.
- Choose Run to run your job.

After the job succeeds, we can check the logs in Amazon CloudWatch.

The data is ingested into Amazon S3, as shown in the following screenshot. 
We are now able to import data from Google Cloud Storage to Amazon S3.
Scaling considerations
In this example, we set the AWS Glue capacity as 10 DPU (Data Processing Units). A DPU is a relative measure of processing power that consists of 4 vCPUs of compute capacity and 16 GB of memory. To scale your AWS Glue job, you can increase the number of DPU, and also take advantage of Auto Scaling. With Auto Scaling enabled, AWS Glue automatically adds and removes workers from the cluster depending on the workload. This removes the need for you to experiment and decide on the number of workers to assign for your AWS Glue ETL jobs. If you choose the maximum number of workers, AWS Glue will adapt the right size of resources for the workload.
Clean up
To clean up your resources, complete the following steps:
- Remove the AWS Glue job and secret in Secrets Manager with the following command:
aws glue delete-job —job-name <your_job_name> aws glue delete-connection —connection-name <your_connection_name> aws secretsmanager delete-secret —secret-id <your_secretsmanager_id> - Cancel the Google Cloud Storage Connector for AWS Glue’s subscription:
- On the AWS Marketplace console, go to the Manage subscriptions page.
- Select the subscription for the product that you want to cancel.
- On the Actions menu, choose Cancel subscription.
- Read the information provided and select the acknowledgement check box.
- Choose Yes, cancel subscription.
- Delete the data in the S3 buckets.
Conclusion
In this post, we showed how to use AWS Glue and the new connector for ingesting data from Google Cloud Storage to Amazon S3. This connector provides access to Google Cloud Storage, facilitating cloud ETL processes for operational reporting, backup and disaster recovery, data governance, and more.
This connector enables your data to be portable across Google Cloud Storage and Amazon S3. We welcome any feedback or questions in the comments section.
References
- AWS Glue official document
- Developing, testing, and deploying custom connectors for your data stores with AWS Glue
- Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors
- Developing custom connectors
About the authors
Qiushuang Feng is a Solutions Architect at AWS, responsible for Enterprise customers’ technical architecture design, consulting, and design optimization on AWS Cloud services. Before joining AWS, Qiushuang worked in IT companies such as IBM and Oracle, and accumulated rich practical experience in development and analytics.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data environments, diving deep into distributed big data software like Apache Spark, building reusable software artifacts for data lakes, and sharing knowledge in AWS Big Data blog posts.
Greg Huang is a Senior Solutions Architect at AWS with expertise in technical architecture design and consulting for the China G1000 team. He is dedicated to deploying and utilizing enterprise-level applications on AWS Cloud services. He possesses nearly 20 years of rich experience in large-scale enterprise application development and implementation, having worked in the cloud computing field for many years. He has extensive experience in helping various types of enterprises migrate to the cloud. Prior to joining AWS, he worked for well-known IT enterprises such as Baidu and Oracle.
Maciej Torbus is a Principal Customer Solutions Manager within Strategic Accounts at Amazon Web Services. With extensive experience in large-scale migrations, he focuses on helping customers move their applications and systems to highly reliable and scalable architectures in AWS. Outside of work, he enjoys sailing, traveling, and restoring vintage mechanical watches.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.