Legacy SIEM solutions like Splunk are valuable for analyzing machine-generated data but their volume-based pricing can lead to high costs and difficult decisions for security teams. Snowflake offers an alternative with flexible pricing, unlimited data storage, and cost-saving data ingestion and retention options. Real success stories demonstrate remarkable cost savings with Snowflake.
Tag: IT data analytics
Snowflake’s New Python API Empowers Data Engineers to Build Modern Data Pipelines with Ease
Snowflake recognizes the shift to Python as the preferred language for data teams and introduces the Python API to bridge the gap. The API aims to streamline workflows, enhance developer productivity, and simplify data pipeline management. By prioritizing the developer experience, Snowflake empowers users to leverage Python within Snowflake for efficient, data-driven solutions across various workloads.
Microsoft Fabric Co-Existing as Semantic Layer with Power BI & Snowflake
Customers have transitioned to Snowflake on AWS and Power BI on Azure, consolidating reporting/analytics platforms. This has improved operations but led to performance and cost challenges, hindering self-data service. Creating a semantic layer in Microsoft Fabric with Snowflake Mirroring is proposed as a solution, offering better performance and cost savings.

Migrate Business Logic from Database to Application for Faster Innovation and Flexibility
The article discusses the migration of business logic from the database layer to the application layer. It emphasizes the benefits of migrating from PL/SQL to Java for scalability, flexibility, support, and cost savings. Ispirer’s SQLWays Wizard tool streamlines the migration process, automating assessment, code conversion, and report generation, facilitating a smooth transition.

Unveiling SEO Treasures: Identify Keywords Beyond Your Competitors’ Reach
Keywords are crucial for SEO, bridging what users search for and web content. The competition is fierce, requiring extensive research and advanced strategies like long-tail and semantic keyword analysis. Niche keywords offer lower competition. Utilize tools like SEMrush, Ahrefs, and Moz Keyword Explorer to gain a competitive edge. Continuous exploration and optimization are necessary for SEO success.
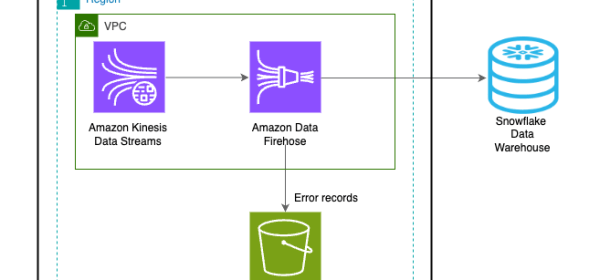
Uplevel your data architecture with real- time streaming using Amazon Data Firehose and Snowflake
Streaming data is crucial in today’s fast-paced world, and Snowflake’s Snowpipe and Snowpipe Streaming provide options to bring in data from sources like Amazon Kinesis Data Streams or Amazon MSK. Amazon Data Firehose integration with Snowpipe Streaming allows real-time, cost-effective, and serverless data delivery to Snowflake, enabling advanced analytics within seconds.

Data Strategy Template: How To Create a Data Strategy
A data strategy template offers a structured plan for managing and leveraging data assets. It includes key stages such as planning, implementation, monitoring, and refinement. Components like data governance, quality management, and architecture contribute to successful data strategies. The template promotes efficiency, completeness, and alignment with business objectives, aiding organizations in effective decision-making and performance improvement.
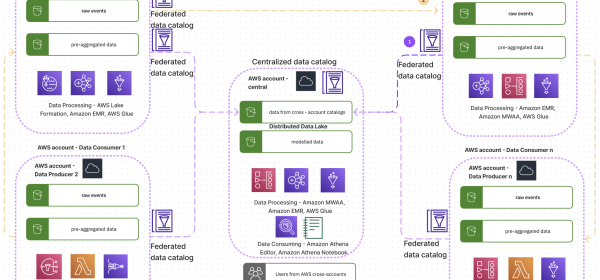
Design a data mesh on AWS that reflects the envisioned organization
Acast, in collaboration with Claudia Chitu and Spyridon Dosis, implemented a decentralized data mesh architecture using AWS services to address diverse business units and a growing volume of data. This approach led to improved data usage, governance, team productivity, and cost efficiency. The architecture reflects the organizational structure, promoting high alignment and autonomy.

Load data incrementally from transactional data lakes to data warehouses
Data lakes and data warehouses are crucial for modern day data storage and management. While data lakes store all of an organization’s data, data warehouses store data that has been structured for analysis. This post discusses techniques for maintaining synchronicity between data lakes and data warehouses, with focus on technologies like AWS Glue, Apache Hudi, Delta Lake, and more in an AWS environment. Various architecture patterns like dual writes, incremental queries, and change data capture are explored, along with examples and step-by-step tutorials.
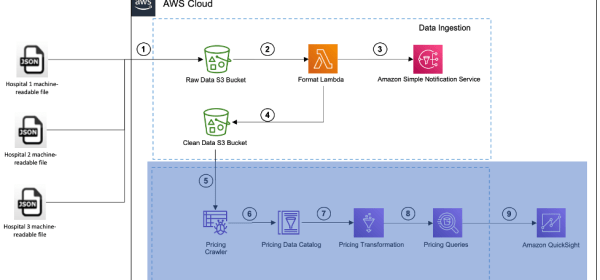
How healthcare organizations can analyze and create insights using price transparency data
Healthcare organizations can now use AWS services to analyze and generate insights from their hospitals’ pricing data. Thanks to the Transparency in Coverage rule mandating the publication of pricing data in machine-readable formats, hospitals can not only compare their prices with competitors, but also develop pricing baselines, assess pricing trends, and identify services with cost differences exceeding certain thresholds. The AWS architecture facilitates data intake, analysis, and visualization, favorably impacting decision-making processes.
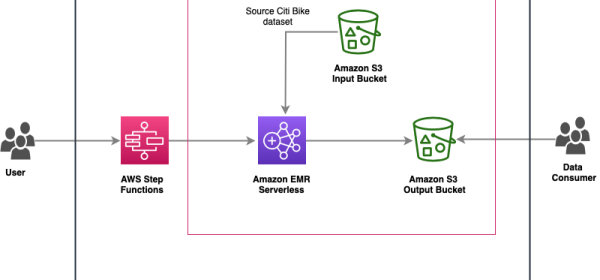
Orchestrate Amazon EMR Serverless jobs with AWS Step functions
Amazon EMR Serverless allows easy operation of analytics applications with open-source frameworks like Apache Spark and Apache Hive. Integrated with AWS Step Functions, it simplifies big data workflows and optimally scales resources according to requirements. The post demonstrates orchestrating a PySpark application using Amazon EMR Serverless and AWS Step Functions to process Citi Bike dataset, and store the aggregated results in Amazon S3.
Analyze call center recordings using text analytics for health and Azure OpenAI Service
The article provides a solution for analyzing healthcare data using Azure-based tools. It involves converting healthcare-centric audio data to text and running healthcare-specific analysis, using techniques like medical terminology linkage. The process involves automation via Azure AI Speech and Azure Synapse Analytics, enabling extraction of key health information and data representation for intelligible consumption. The solution can be used for smart analysis of telehealth data, healthcare-centric call center data, and clinical trials data. The article emphasizes ensuring the security of sensitive data and cost-optimization strategies.
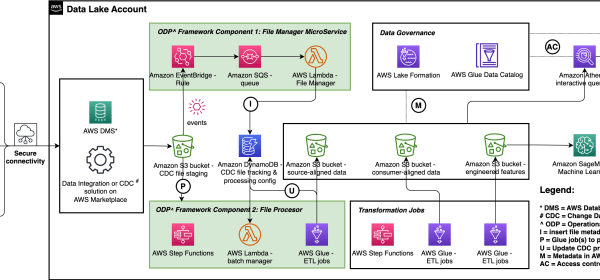
Simplify operational data processing in data lakes using AWS Glue and Apache Hudi
The following diagram illustrates running File Processor state machine with a configuration that includes 18 operational tables, a refresh cadence of 10 minutes, a batch size of 5, and an AWS Glue worker type
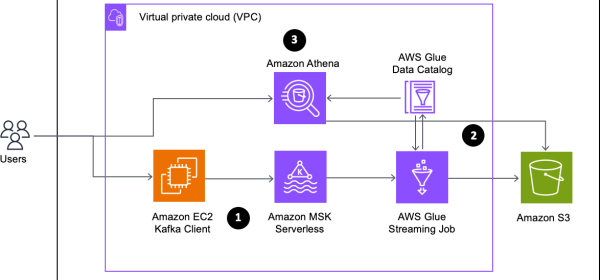
Securely process near-real-time data from Amazon MSK Serverless using an AWS Glue streaming ETL job with IAM authentication
gluejob-setup.yaml – This template sets up the data processing resources such as the AWS Glue table, database, connection, and streaming job The post demonstrates how to build an end-to-end