Monitoring the logs generated from the jobs deployed on EMR clusters is essential to help detect critical issues in real time and identify root causes quickly. In this post, we create an EMR cluster and centralize the EMR
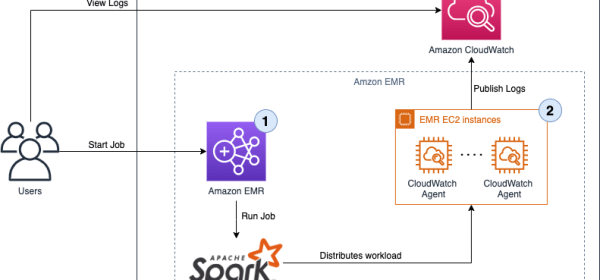
Monitoring the logs generated from the jobs deployed on EMR clusters is essential to help detect critical issues in real time and identify root causes quickly. In this post, we create an EMR cluster and centralize the EMR

To solve this problem, we needed to build our own solution to convert the tag-based policies in Lake Formation into grants and revokes in the resource-based entitlements in Amazon Redshift. The tag-based access

Showpad built new customer-facing embedded dashboards within Showpad eOSTM and migrated its legacy dashboards to Amazon QuickSight, a unified BI service providing modern interactive dashboards,

Batch/file-based data is modeled into the raw vault table structures as the hub, link, and satellite tables illustrated at the beginning of this post. The reusable and shareable (by more than one ML model) feature values

In order to enable our diacritic-insensitive search, we configure custom analyzers that use the ASCII folding token filter. Accent-insensitive search, also called diacritics-agnostic search, is where search results are
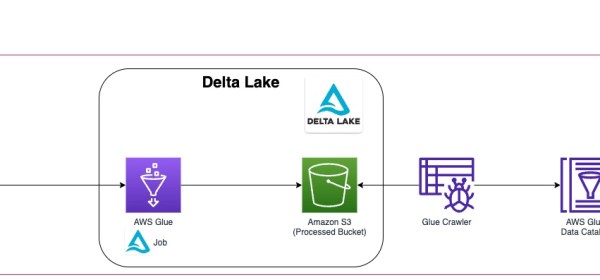
The team is tasked with implementing SCD Type 2 functionality for identifying new, updated, and deleted records from the source, and to preserve the historical changes in the data lake An AWS Glue job (Delta
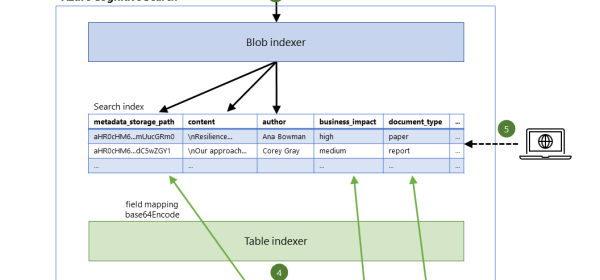
This scenario uses indexers in Azure Cognitive Search to automatically discover new content in supported data sources, like blob and table storage, and then add it to the search index. This article uses an example
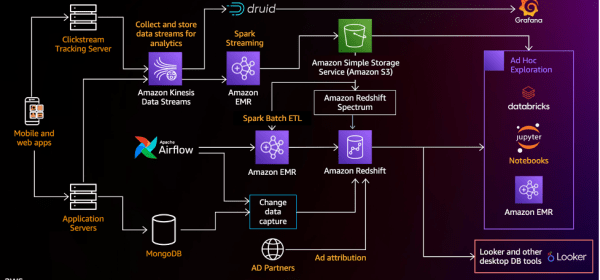
We discuss how to create such a solution using Amazon Kinesis Data Streams, Amazon Managed Streaming for Kafka (Amazon MSK), Amazon Kinesis Data Analytics for Apache Flink ; the design decisions

In this post, we share the solution SafetyCulture used to scale unpredictable dbt Cloud workloads in a cost-effective manner with Amazon Redshift. A source of unpredictable workloads is dbt Cloud,

A SageMaker notebook uses an AWS SDK for pandas package to run a SQL query in Athena, including the UDF. We then use an Athena user-defined function (UDF) to determine which hexagon each historical
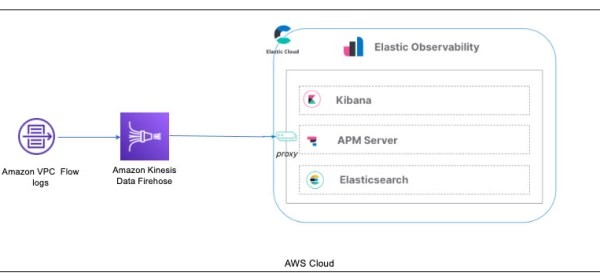
With this new integration, you can set up this configuration directly from your VPC flow logs to Kinesis Data Firehose and into Elastic Cloud. In the past, users would have to use an AWS Lambda function to transform the incoming data from VPC flow logs into an Amazon Simple Storage Service (Amazon
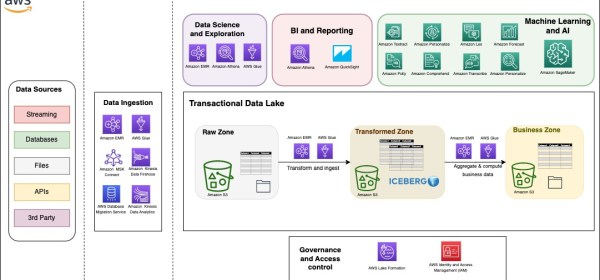
EMR Serverless supports Iceberg natively to create tables and query, merge, and insert data with Spark. In the following architecture diagram, Spark transformation jobs can load data from the raw zone or source,

The post demonstrates how to build an end-to-end CDC using Amazon MSK Connect, an AWS managed service to deploy and run Kafka Connect applications and AWS Glue Schema Registry, which allows you
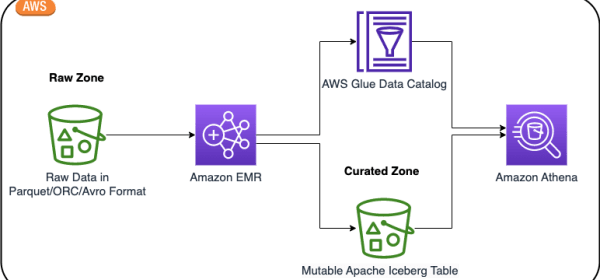
In this post, we walk you through a solution to build a high-performing Apache Iceberg data lake on Amazon S3; process incremental data with insert, update, and delete SQL statements; and tune the Iceberg table to