
This post explains how you can create a fully serverless and cost-effective Amazon Redshift ETL orchestration framework. To achieve this, you can use Amazon Redshift RSQL and AWS services such as 
Overview of solution
When you’re migrating from existing data warehouses to Amazon Redshift, your existing ETL processes are implemented as proprietary scripts. These scripts contain SQL statements and complex business logic such as if-then-else control flow logic, error reporting, and error handling. You can convert all these features to Amazon Redshift RSQL, which you can use to replace existing ETL and other automation scripts. To learn more about Amazon Redshift RSQL features, examples, and use cases, see 

The goal of the solution presented in this post is to run complex ETL jobs implemented in Amazon Redshift RSQL scripts in the AWS Cloud without having to manage any infrastructure. In addition to meeting functional requirements, this solution also provides full auditing and traceability of all ETL processes that you run.
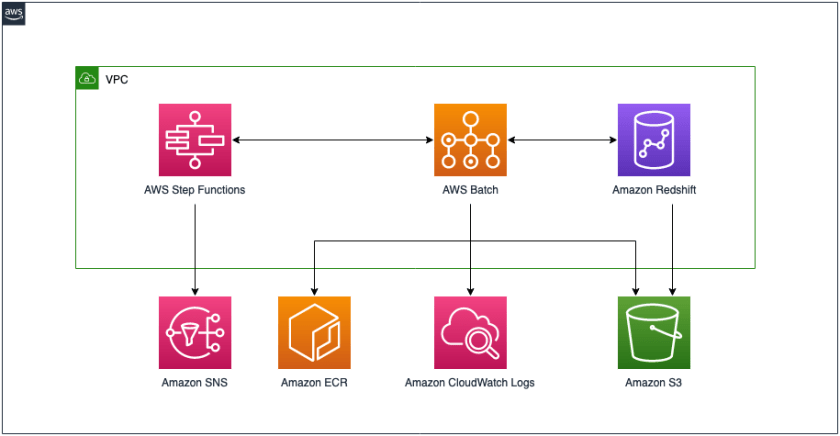
The following diagram shows the final architecture.
The deployment is fully automated using 
- EcrRepositoryStack – Creates a private
Amazon Simple Notification Service (Amazon SNS) topic and email subscription (email is passed as a parameter)
- StepFunctionsStack – Creates a state machine to orchestrate serverless RSQL ETL jobs
- SampleDataDeploymentStack – Deploys sample RSQL ETL scripts and sample TPC benchmark datasets
Prerequisites
You should have the following prerequisites:
- An
Docker Engine installed
Deploy AWS CDK stacks
To deploy the serverless RSQL ETL framework solution, use the following code. Replace 123456789012 with your AWS account number, eu-west-1 with the AWS Region to which you want deploy the solution, and [email protected] with your email address to which ETL success and failure notifications are sent.
git clone https://github.com/aws-samples/amazon-redshift-serverless-rsql-etl-framework
cd amazon-redshift-serverless-rsql-etl-framework
npm install
./cdk.sh 123456789012 eu-west-1 bootstrap
./cdk.sh 123456789012 eu-west-1 deploy --all --parameters SnsStack:[email protected]The whole process takes a few minutes. While AWS CDK creates all the stacks, you can continue reading this post.
Create the RSQL container image
AWS CDK creates an RSQL Docker image. This Docker image is the basic building block of our solution. All ETL processes run inside it. AWS CDK creates the Docker image locally using Docker Engine and then uploads it to the Amazon ECR repository.
The Docker image is based on an Amazon Linux 2 Docker image. It has the following tools installed: the 
.odbc.ini file, which defines the etl profile, which is used to connect to the Amazon Redshift cluster. See the following code:
FROM amazonlinux:2
ENV AMAZON_REDSHIFT_ODBC_VERSION=1.4.52.1000
ENV AMAZON_REDSHIFT_RSQL_VERSION=1.0.4
RUN yum install -y openssl gettext unixODBC awscli && \
yum clean all
RUN rpm -i \
https://s3.amazonaws.com/redshift-downloads/drivers/odbc/${AMAZON_REDSHIFT_ODBC_VERSION}/AmazonRedshiftODBC-64-bit-${AMAZON_REDSHIFT_ODBC_VERSION}-1.x86_64.rpm \
 https://s3.amazonaws.com/redshift-downloads/amazon-redshift-rsql/${AMAZON_REDSHIFT_RSQL_VERSION}/AmazonRedshiftRsql-${AMAZON_REDSHIFT_RSQL_VERSION}-1.x86_64.rpm
COPY .odbc.ini .odbc.ini
COPY fetch_and_run.sh /usr/local/bin/fetch_and_run.sh
ENV ODBCINI=.odbc.ini
ENV ODBCSYSINI=/opt/amazon/redshiftodbc/Setup
ENV AMAZONREDSHIFTODBCINI=/opt/amazon/redshiftodbc/lib/64/amazon.redshiftodbc.ini
ENTRYPOINT ["/usr/local/bin/fetch_and_run.sh"]
https://s3.amazonaws.com/redshift-downloads/amazon-redshift-rsql/${AMAZON_REDSHIFT_RSQL_VERSION}/AmazonRedshiftRsql-${AMAZON_REDSHIFT_RSQL_VERSION}-1.x86_64.rpm
COPY .odbc.ini .odbc.ini
COPY fetch_and_run.sh /usr/local/bin/fetch_and_run.sh
ENV ODBCINI=.odbc.ini
ENV ODBCSYSINI=/opt/amazon/redshiftodbc/Setup
ENV AMAZONREDSHIFTODBCINI=/opt/amazon/redshiftodbc/lib/64/amazon.redshiftodbc.ini
ENTRYPOINT ["/usr/local/bin/fetch_and_run.sh"]The following code example shows the .odbc.ini file. It defines an etl profile, which uses an 
Database, DbUser, and ClusterID parameters are set in AWS CDK. Also, AWS CDK replaces the Region parameter at runtime with the Region to which you deploy the stacks.
[ODBC]
Trace=no
[etl]
Driver=/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.so
Database=demo
DbUser=etl
ClusterID=redshiftblogdemo
Region=eu-west-1
IAM=1For more information about connecting to Amazon Redshift clusters with RSQL, see 
Our Docker image implements a well-known fetch and run integration pattern. To learn more about this pattern, see 
BATCH_SCRIPT_LOCATION. Our job also expects two other environment variables: DATA_BUCKET_NAME, which is the name of the S3 data bucket, and COPY_IAM_ROLE_ARN, which is the Amazon Redshift IAM role used for the COPY command to load the data into Amazon Redshift. All environment variables are set automatically by AWS CDK. The fetch_and_run.sh script is the entry point of the Docker container. See the following code:
#!/bin/bash
# This script expects the following env variables to be set:
# BATCH_SCRIPT_LOCATION - full S3 path to RSQL script to run
# DATA_BUCKET_NAME - S3 bucket name with the data
# COPY_IAM_ROLE_ARN - IAM role ARN that will be used to copy the data from S3 to Redshift
PATH="/bin:/usr/bin:/sbin:/usr/sbin:/usr/local/bin:/usr/local/sbin"
if [ -z "${BATCH_SCRIPT_LOCATION}" ] || [ -z "${DATA_BUCKET_NAME}" ] || [ -z "${COPY_IAM_ROLE_ARN}" ]; then
echo "BATCH_SCRIPT_LOCATION/DATA_BUCKET_NAME/COPY_IAM_ROLE_ARN not set. No script to run."
exit 1
fi
# download script to a temp file
TEMP_SCRIPT_FILE=$(mktemp)
aws s3 cp ${BATCH_SCRIPT_LOCATION} ${TEMP_SCRIPT_FILE}
# execute script
# envsubst will replace ${COPY_IAM_ROLE_ARN} and ${COPY_IAM_ROLE_ARN} placeholders with actual values
envsubst < ${TEMP_SCRIPT_FILE} | rsql -D etl
exit $?Create AWS Batch resources
Next, AWS CDK creates the AWS Batch compute environment, job queue, and job definition. As a fully managed service, AWS Batch helps you run batch computing workloads of any scale. AWS CDK creates a Fargate serverless compute environment for us. The compute environment deploys inside the same VPC as the Amazon Redshift cluster, inside the isolated subnets. The job definition uses our Docker image with Amazon Redshift RSQL.
This step turns Amazon Redshift RSQL into a serverless service. You can build complex ETL workflows based on this generic job.
Create a Step Functions state machine
AWS CDK then moves to the deployment of the Step Functions state machine. Step Functions enables you to build complex workflows in a visual way directly in your browser. This service supports over 9,000 API actions from over 200 AWS services.
You can use Amazon States Language to create a state machine on the Step Functions console. The Amazon States Language is a JSON-based, structured language used to define your state machine. You can also build them programmatically using AWS CDK, as I have done for this post.
After AWS CDK finishes, a new state machine is created in your account called ServerlessRSQLETLFramework. To run it, complete the following steps:
- Navigate to the Step Functions console.
- Choose the function to open the details page.
- Choose Edit, and then choose Workflow Studio New.
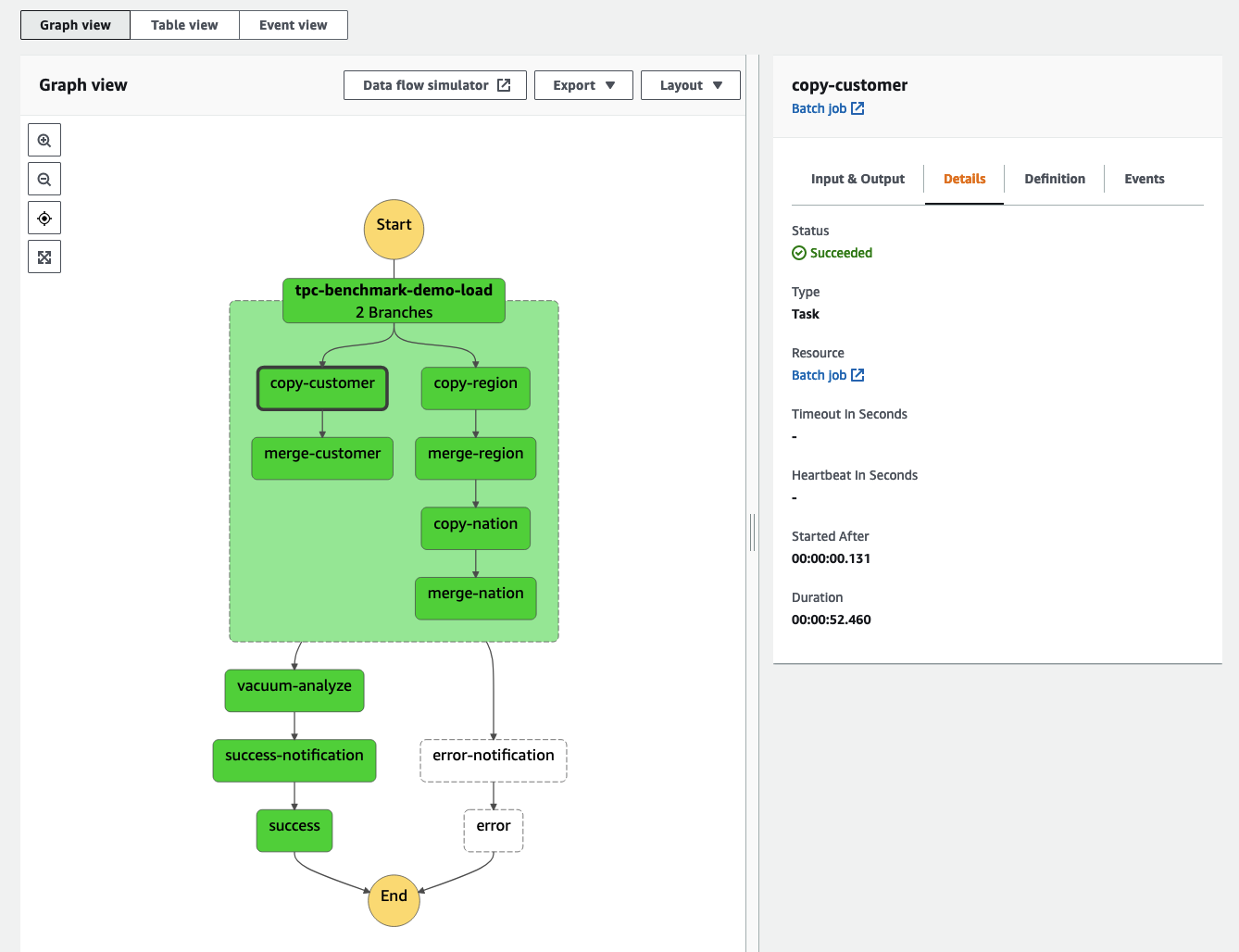
The following screenshot shows our state machine.
- Choose Cancel to leave Workflow Studio, then choose Cancel again to leave the edit mode.
You will be brought back to the details page. - Choose Start execution.
A dialog box appears. By default, the Name parameter is set to a random identifier, and the Input parameter is set to a sample JSON document. - Delete the Input parameter and choose Start execution to start the state machine.
The Graph view on the details page updates in real time. The state machine starts with a parallel state with two branches. In the left branch, the first job loads customer data into staging table, then the second job merges new and existing customer records. In the right branch, two smaller tables for regions and nations are loaded and then merged one after another. The parallel state waits until all branches are complete before moving to the vacuum-analyze state, which runs VACUUM and ANALYZE commands on Amazon Redshift. The sample state machine also implements the Amazon SNS Publish API actions to send notifications about success or failure.
From the Graph view, you can check the status of each state by choosing it. Every state that uses an external resource has a link to it on the Details tab. In our example, next to every AWS Batch Job state, you can see a link to the AWS Batch Job details page. Here, you can view the status, runtime, parameters, IAM roles, link to 
Clean up
To avoid ongoing charges for the resources that you created, delete them. AWS CDK deletes all resources except data resources such as S3 buckets and Amazon ECR repositories.
- First, delete all AWS CDK stacks. In the following code, provide your own AWS account and AWS Region:
./cdk.sh 123456789012 eu-west-1 destroy --all - On the Amazon S3 console, empty and delete buckets with names starting with:
s3stack-rsqletldemodatas3stack-rsqletldemoscriptss3stack-rsqletldemologging
- Finally, on the Amazon ECR console, delete repositories with names starting with:
ecrrepositorystack-amazonlinuxrsqlcdk-container-assets
Next steps
Here are some ideas of additional enhancements that you can add to the described solution.
You can break large complex state machines into smaller building blocks by creating self-contained state machines. In our example, you could create state machines for every pair of copy and merge jobs. You could create three such state machines: Copy and Merge Customer, Copy and Merge Region, and Copy and Merge Nation, and then call them from the main state machine. For complex workflows, a different team can work on each sub-state machine in parallel. Also, this pattern promotes reuse of existing components, best practices, and security mechanisms.
You can use Amazon S3 Object Functions or Amazon S3 EventBridge notifications to start a state machine automatically after you upload a file to an S3 bucket. To learn more about Amazon S3 integration with 
Summary
You can use Amazon Redshift RSQL, AWS Batch, and Step Functions to create modern, serverless, and cost-effective ETL workflows. There is no infrastructure to manage, and Amazon Redshift RSQL works as a serverless RSQL service. In this post, we demonstrated how to use this serverless RSQL service to build more complex ETL workflows with Step Functions.
Step Functions integrates natively with over 200 AWS services. This opens a new world of possibilities to AWS customers and partners, who can integrate their processes with other data, analytics, machine learning, and compute services such as Amazon S3, 
In this post, I used RSQL automation scripts as the building blocks of ETL workflows. Using RSQL is a common integration pattern that we see for customers migrating from Teradata BTEQ scripts. However, if you have simple ETL or ELT processes that can be written as plain SQL, you can invoke the 
About the author
Lukasz is a Principal Software Dev Engineer working in the AWS DMA team. Lukasz helps customers move their workloads to AWS and specializes in migrating data warehouses and data lakes to AWS. In his free time, Lukasz enjoys learning new human languages.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.