This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland.
Cargotec (Nasdaq Helsinki: CGCBV) is a Finnish company that specializes in cargo handling solutions and services. They are headquartered in Helsinki, Finland, and operates globally in over 100 countries. With its leading cargo handling solutions and services, they are pioneers in their field. Through their unique position in ports, at sea, and on roads, they optimize global cargo flows and create sustainable customer value.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a data lake, transformed, and made available for analytics, machine learning (ML), and visualization. For this, Cargotec built an Amazon Simple Storage Service (Amazon S3) data lake and cataloged the data assets in AWS Glue Data Catalog. They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
In this blog, we discuss the technical challenges faced by Cargotec in replicating their AWS Glue metadata across AWS accounts, and how they navigated these challenges successfully to enable cross-account data sharing. By sharing their story, we hope to inspire readers facing similar challenges and provide insights into how our services can be customized to meet your specific needs.
Challenges
Like many customers, Cargotec’s data lake is distributed across multiple AWS accounts that are owned by different teams. Cargotec wanted to find a solution to share datasets across accounts and use Amazon Athena to query them. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views. Cargotec’s use cases also required them to create views that span tables and views across catalogs. Cargotec’s implementation covers three discrete AWS accounts, 25 databases, 150 tables, and 10 views.
Solution overview
Cargotec required a single catalog per account that contained metadata from their other AWS accounts. The solution that best fit their needs was to replicate metadata using an in-house version of a publicly available utility called Metastore Migration utility. Cargotec extended the utility by changing the overall orchestration layer by adding an Amazon SQS notification and an AWS Lambda. The approach was to programmatically copy and make available each catalog entity (databases, tables, and views) to all consumer accounts. This makes the tables or views local to the account where the query is being run, while the data still remains in its source S3 bucket.
Cargotec’s solution architecture
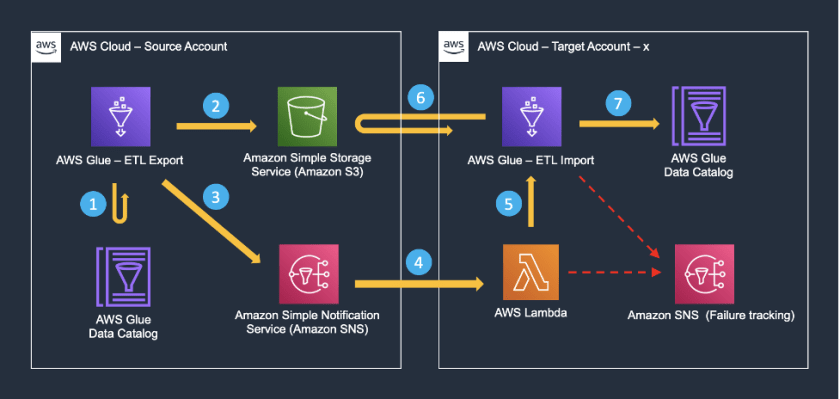
The following diagram summarizes the architecture and overall flow of events in Cargotec’s design.

Catalog entries from a source account are programmatically replicated to multiple target accounts using the following series of steps.
- An AWS Glue job (metadata exporter) runs daily on the source account. It reads the table and partition information from the source AWS Glue Data Catalog. Since the target account is used for analytical purposes and does not require real-time schema changes, the metadata exporter runs only once a day. Cargotec uses partition projection, which ensures that the new partitions are available in real-time.
- The job then writes the metadata to an S3 bucket in the same account. Please note that the solution doesn’t involve movement of the data across accounts. The target accounts read data from the source account S3 buckets. For guidance on setting up the right permissions, please see the Amazon Athena User Guide.
- After the metadata export has been completed, the AWS Glue job pushes a notification to an Amazon Simple Notification Service (Amazon SNS) topic. This message contains the S3 path to the latest metadata export. The SNS notification is Cargotec’s customization to the existing open-source utility.
- Every target account runs an AWS Lambda function that is notified when the source account SNS topic receives a push. In short, there are multiple subscriber Lambda functions (one per target account) for the source account SNS topics that get triggered when an export job is completed.
- Once triggered, the Lambda function then initiates an AWS Glue job (metadata importer) on the respective target account. The job receives as input the source account’s S3 path to the metadata that has been recently exported.
- Based on the path provided, the metadata importer reads the exported metadata from the source S3 bucket.
- The metadata importer now uses this information to create or update the corresponding catalog information in the target account.
All along the way, any errors are published to a separate SNS topic for logging and monitoring purposes. With this approach, Cargotec was able to create and consume views that span tables and views from multiple catalogs spread across different AWS accounts.
Implementation
The core of the catalog replication utility is two AWS Glue scripts:
- Metadata exporter – An AWS Glue job that reads the source data catalog and creates an export of the databases, tables, and partitions in an S3 bucket in the source account.
- Metadata importer – An AWS Glue job that reads the export that was created by the metadata exporter and applies the metadata to target databases. This code is triggered by a Lambda function once files are written to S3. The job runs in the target account.
Metadata exporter
This section provides details on the AWS Glue job that exports the AWS Glue Data Catalog into an S3 location. The source code for the application is hosted the AWS Glue GitHub. Though this may need to be customized to suit your needs, we will go over the core components of the code in this blog.
Metadata exporter inputs
The application takes a few job input parameters as described below:
--modekey accepts eitherto-s3orto-jdbc. The latter is used when the code is moving the metadata directly into a JDBC Hive Metastore. In the case of Cargotec, since we are moving the metadata to files on S3, the value for--modewill remainto-s3.--output-pathaccepts an S3 location to which the exported metadata should be written. The code creates subdirectories corresponding to databases, tables, and partitions.--database-namesaccepts a semicolon-separated list of databases on the source catalog that need to be replicated to the target
Reading the catalog
The metadata about the database, tables, and partitions are read from the AWS Glue catalog.
dyf = glue_context.create_dynamic_frame.from_options(
connection_type=’com.amazonaws.services.glue.connections.DataCatalogConnection‘,
connection_options = {
'catalog.name': ‘datacatalog’,
'catalog.database': database,
'catalog.region': region
})
The above code snippet reads the metadata into an AWS Glue DynamicFrame. The frame is then converted to a Spark DataFrame. It is filtered into individual DataFrames based on it being either part of a database, table, or partition. A schema is attached to the data frame using one of the below:
DATACATALOG_DATABASE_SCHEMA =
StructType([
StructField('items', ArrayType(
DATACATALOG_DATABASE_ITEM_SCHEMA, False),
True),
StructField('type', StringType(), False)
])
DATACATALOG_TABLE_SCHEMA =
StructType([
StructField('database', StringType(), False),
StructField('type', StringType(), False),
StructField('items', ArrayType(DATACATALOG_TABLE_ITEM_SCHEMA, False), True)
])
DATACATALOG_PARTITION_SCHEMA =
StructType([
StructField('database', StringType(), False),
StructField('table', StringType(), False),
StructField('items', ArrayType(DATACATALOG_PARTITION_ITEM_SCHEMA, False), True),
StructField('type', StringType(), False)
])
For details on the individual item schema, refer to the schema definition on GitHub.
Persisting the metadata
After converting to a DataFrame with schema, it is persisted to the S3 location marked by the output-path parameter
databases.write.format('json').mode('overwrite').save(output_path + 'databases')
tables.write.format('json').mode('overwrite').save(output_path + 'tables')
partitions.write.format('json').mode('overwrite').save(output_path + 'partitions')
Exploring the output
Navigate to the S3 bucket that contains the output location, and you should be able to see the output metadata in format. An example export for a table would look like the following code snippet.
{
"database": "default",
"type": "table",
"item": {
"createTime": "1651241372000",
"lastAccessTime": "0",
"owner": "spark",
"retention": 0,
"name": "an_example_table",
"tableType": "EXTERNAL_TABLE",
"parameters": {
"totalSize": "2734148",
"EXTERNAL": "TRUE",
"last_commit_time_sync": "20220429140907",
"spark.sql.sources.schema.part.0": "{redacted_schema}",
"numFiles": "1",
"transient_lastDdlTime": "1651241371",
"spark.sql.sources.schema.numParts": "1",
"spark.sql.sources.provider": "hudi"
},
"partitionKeys": [],
"storageDescriptor": {
"inputFormat": "org.apache.hudi.hadoop.HoodieParquetInputFormat",
"compressed": false,
"storedAsSubDirectories": false,
"location": "s3://redacted_bucket_name/table/an_example_table",
"numberOfBuckets": -1,
"outputFormat": "org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat",
"bucketColumns": [],
"columns": [{
"name": "_hoodie_commit_time",
"type": "string"
},
{
"name": "_hoodie_commit_seqno",
"type": "string"
}
],
"parameters": {},
"serdeInfo": {
"serializationLibrary": "org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe",
"parameters": {
"hoodie.query.as.ro.table": "false",
"path": "s3://redacted_bucket_name/table/an_example_table",
"serialization.format": "1"
}
},
"skewedInfo": {
"skewedColumnNames": [],
"skewedColumnValueLocationMaps": {},
"skewedColumnValues": []
},
"sortColumns": []
}
}
}
Once the export job is complete, the output S3 path will be pushed to an SNS topic. A Lambda function at the target account processes this message and invokes the import AWS Glue job by passing the S3 import location.
Metadata importer
The import job runs on the target account. The code for the job is available on GitHub. As with the exporter, you may need to customize it to suit your specific requirements, but the code as-is should work for most scenarios.
Metadata importer inputs
The inputs to the application are provided as job parameters. Below is a list of parameters that are used for the import process:
--modekey accepts eitherfrom-s3orfrom-jdbc. The latter is used when migration is from a JDBC source to the AWS Glue Data Catalog. At Cargotec, the metadata is already written to Amazon S3, and hence the value for this key is always set tofrom-s3.--regionkey accepts a valid AWS Region for the AWS Glue Catalog. The target Region is specified using this key.--database-input-pathkey accepts the path to the file containing the database metadata. This is the output of the previous import job.--table-input-pathkey accepts the path to the file containing the table metadata. This is the output of the previous import job.--partition-input-pathkey accepts the path to the file containing the partition metadata. This is the output of the previous import job.
Reading the metadata
The metadata, as previously discussed, are files on Amazon S3. They are read into individual spark data frames with their respective schema information
databases = sql_context.read.json(path=db_input_dir, schema=METASTORE_DATABASE_SCHEMA)
tables = sql_context.read.json(path=tbl_input_dir, schema=METASTORE_TABLE_SCHEMA)
partitions = sql_context.read.json(path=parts_input_dir, schema=METASTORE_PARTITION_SCHEMA)
Loading the catalog
Once the spark data frames are read, they are converted to AWS Glue DynamicFrame and then loaded to the catalog, as shown in the following snippet.
glue_context.write_dynamic_frame.from_options(
frame=dyf_databases,
connection_type='catalog',
connection_options={
'catalog.name': datacatalog_name,
'catalog.region': region
}
)
glue_context.write_dynamic_frame.from_options(
frame=dyf_tables,
connection_type='catalog',
connection_options={
'catalog.name': datacatalog_name,
'catalog.region': region
}
)
glue_context.write_dynamic_frame.from_options(
frame=dyf_partitions,
connection_type='catalog',
connection_options={
'catalog.name': datacatalog_name,
'catalog.region': region
}
)
Once the job concludes, you can query the target AWS Glue catalog to ensure the tables from the source have been synced with the destination. To keep things simple and easy to manage, instead of implementing a mechanism to identify tables that change over time, Cargotec updates the catalog information of all databases or tables that are configured in the export job.
Considerations
Though the setup works effectively for Cargotec’s current business requirements, there are a few drawbacks to this approach, which are highlighted below:
- The solution involves code. Customizations were made to the existing open-source utility to be able to publish an SNS notification once an export is complete and a Lambda function to trigger the import process.
- The export process on the source account is a scheduled job. Hence there is no real-time sync between the source and target accounts. This was not a requirement for Cargotec’s business process.
- For tables that don’t use Athena partition projection, query results may be outdated until the new partitions are added to the metastore through MSCK REPAIR TABLE, ALTER TABLE ADD PARTITION, AWS Glue crawler, and so on.
- The current approach requires syncing all the tables across the source and target. If the requirement is to capture only the ones that changed instead of a scheduled daily export, the design needs to change and could benefit from the Amazon EventBridge integration with AWS Glue. An example implementation of using AWS Glue APIs to identify changes is shown in Identify source schema changes using AWS Glue.
Conclusion
In this blog post, we have explored a solution for cross-account sharing of data and tables that makes it possible for Cargotec to create views that combine data from multiple AWS accounts. We’re excited to share Cargotec’s success and believe the post has provided you with valuable insights and inspiration for your own projects.
We encourage you to explore our range of services and see how they can help you achieve your goals. Lastly, for more data and analytics blogs, feel free to bookmark the AWS Blogs.
About the Authors
Sumesh M R is a Full Stack Machine Learning Architect at Cargotec. He has several years of software engineering and ML background. Sumesh is an expert in Sagemaker and other AWS ML/Analytics services. He is passionate about data science and loves to explore the latest ML libraries and techniques. Before joining Cargotec, he worked as a Solution Architect at TCS. In his spare time, he loves to play cricket and badminton.
Tero Karttunen is a Senior Cloud Architect at Knowit Finland. He advises clients on architecting and adopting Data Architectures that best serve their Data Analytics and Machine Learning needs. He has helped Cargotec in their data journey for more than two years. Outside of work, he enjoys running, winter sports, and role-playing games.
Arun A K is a Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on AWS Glue, AWS Lake Formation, Amazon Athena, and Amazon EMR. In his free time, he likes to spend time with his friends and family.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.