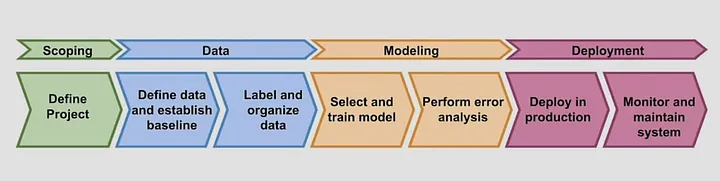
Machine Learning Lifecycle
This is my third article covering the Machine Learning Project Lifecycle. If you have not read the previous ones, consider checking them at Machine Learning Lifecycle I: Deployment | by Luís Fernando Torres | Feb, 2024 | Artificial Intelligence in Plain English (medium.com) and Machine Learning Lifecycle II: Select & Train Model | by Luís Fernando Torres | Feb, 2024 | Medium.
We already explored the deployment and modeling stages. In this article, we will explore the data collection stage.

Lifecycle of a Machine Learning Project. Source: Machine Learning Engineering for Production (MLOps) Specialization — DeepLearning.AI
Data Quality is Key for Model Success
In the last article, we discussed both data-centric and model-centric approaches in machine learning modeling. We have also highlighted how the data-centric approach tends to be more satisfactory for real-world scenarios.
With that in mind, you should now clearly know that data is the fuel of your models. That is why the data stage is so crucial for developing successful AI applications.
Define Data and Establish a Baseline
Defining the dataset you will work with can be quite challenging. Even though several datasets are available online for free or for purchase, you will probably encounter several projects where you must build the dataset from scratch.
Before starting, you must clearly define what should be your X and what should be your y. What are the predictors, and what is the target variable? The predictors, or features, should have a meaningful relationship with the target variable. You can’t predict if a car is more likely to break down within the next twelve months based on the phase of the moon during its manufacturing process. You do so by analyzing its maintenance history, vehicle age, mileage, etcetera.
Besides ensuring that predictors and the target variable share some degree of relationship, you must also ensure that labeling is consistent throughout the dataset. Take a look at the example below.

We have the same picture and the same device. However, we have three different forms of labeling. In the first image, the label only highlights a big scratch. In the second image, it highlights a big and a small scratch. In the third, it labels both as one single defect.
This type of inconsistency tends to be very common in Computer Vision tasks. Ensuring that every image throughout the dataset follows the same labeling pattern is vital for a high-performing model. Inconsistent labels translate into a confused model and poor performance.
The same issue is also common in labeling speech data, as there are different possible transcription patterns to follow.

When defining your input X, it is always relevant to ask:
- Are my images well-lit?
- Do I have a clear audio?
- Can a human effectively label this data?
If a human can’t understand what is on an image or what a person is saying in an audio file, your model will probably fail.
Improving Label Consistency
As mentioned in the last article, humans tend to be more efficient in labeling unstructured data, such as images and audio. It is fundamental to promote collaborative discussions between different labelers to agree on clear definitions for each label in the dataset and document it all for future reference to improve label consistency across the training data. Standardized labeling reduces ambiguity.
It is a good idea to sit down and reach an agreement on what exactly is a defect on a phone screen, for example. Set a threshold, such as defining that a phone defect will only be labeled as such when the scratch length on the screen is higher than 0.3 mm.

Consistent labels also help measure human-level performance — HLP — in the task. We can then use the HLP as a baseline to compare model performance.
Human-level performance is a neat metric that helps us set realistic expectations for model performance and reveal where the model struggles the most. However, beware that inconsistent labeling may artificially reduce HLP, making it possible to end up with a model that “outperforms” the HLP without being better in any meaningful way.
Label and Organize Data
You are probably aware that the machine learning process is highly iterative. This fact holds for data collection as well.
Andrew Ng alerts to spending too much time on an initial data collection. Consider the costs and time involved in collecting the data. Start with a small dataset, then train your model. Perform error analysis to evaluate performance and only then ask: do we need more data?
There are several factors to consider besides cost and time for data collection. You must ensure the quality of that data for the task at hand and that it complies with privacy regulations and ethical concerns.
Labeling comes in question once more. Depending on the task, the budget, and the size of the dataset, you have different labeling options:
Internal Labeling
- Your team of Machine Learning Engineers labels the data.
- It ensures quality control depending on the degree of expertise of the team. It is also fast for initial project stages to build intuition about the data.
- It might not be scalable for large datasets and can be expensive if these engineers spend a significant time labeling the data.
Outsourced Labeling
- You hire a specialized company to label your data.
- It ensures expertise in handling specific data types, such as having medical experts label medical images, for example.
- It can be costly, depending on the complexity of the data.
Crowdsourced Labeling
- The labeling task is broken down and distributed across a large group of people.
- It allows you to have a large pool of potential labelers for tasks requiring general knowledge and potentially lower costs than outsourcing companies.
- If the task is complex and requires specific expertise, it becomes difficult to ensure quality control. It is definitely not suitable for sensitive data.
Data Pipelines
Data pipelines involve multiple processing steps for the data before it reaches its final form for the machine learning model. Raw data in real-world scenarios is messy and often needs cleaning before it can be fed into an algorithm to predict an outcome for the target variable.
Consider a model built to predict if a user is looking for a job based on their personal information. The raw data might require the removal of spam accounts or the merging of user IDs for better usability.

A core challenge is replicability. You must ensure that the processing steps are done consistently during development and during production. During the development of the application, messy scripts and manual processes might be acceptable, especially for proof-of-concept projects. The focus is on making the prototype work before releasing it as a product or service — and don’t forget to take notes for later replication.
As soon as the project moves into production, replicability becomes crucial. Tools like TensorFlow Transform and Apache Beam are very helpful in helping you manage complex data pipelines and ensure consistency through data processing.
Three other concepts that you must be familiar with while working with complex data pipelines are data provenance, lineage, and metadata. Data provenance tracks the origin of the data, whereas data lineage tracks the processing steps taken during development. Knowing this information helps maintain the system and fix errors quickly and effectively.
Metadata is the data about data. It provides details about the data itself. For instance, when analyzing phone images for defects, metadata might include the factory, line number, and camera settings.
It is very helpful during error analysis. If a specific factory or line constantly produces error-prone images, the metadata helps identify the root cause.
Data Splits
Last — but not least — is the importance of balanced training, development, and test splits.
A balanced split of the dataset ensures the proportion of positive examples, such as defective phones, is consistent across the training, dev, and test sets, leading to a more representative evaluation. When working with large datasets, you can randomly split your data since the different datasets are likely representative of the overall data.
However, on small datasets, random splits can destroy your perception of the model’s actual performance since there is a high chance of inconsistent negative and positive ratios across the training, dev, and test sets. Ensuring balanced splits of negative and positive examples is crucial in how accurately dev and test sets reflect real-world performance.
Conclusion
In this article, we explored the importance of the data collection stage in the Machine Learning Project Lifecycle. High-quality data is crucial for data-centric approaches, which tend to be more effective in developing real-world applications as a service or product.
Ensuring data quality can be challenging. You might encounter structured and unstructured data, large and small datasets. Each comes with its own intricacies and set of adequate steps to extract the best the data has to offer.
Overall, the keyword for the subject we discussed is consistency.
Consistent labels ensure the model can learn from the data and perform well in predicting the target variable. Consistency is also vital during feature engineering and the preprocessing steps to ensure that the model behaves the same it did during training and development while in production. Once again, consistency is vital to ensure a balanced split into training, dev, and testing sets.
Thank you very much for reading so far!
In the next article, we’re going to discuss the scoping process, where we’ll dive into defining the problem and setting clear goals for your AI project.
Luis Fernando Torres
Let’s connect!🔗
LinkedIn • Kaggle • HuggingFace
Like my content? Feel free to Buy Me a Coffee ☕ !
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.