本記事では、昨今の生成AIや大規模言語モデル(LLM)の進化と普及が進む現状を踏まえ、自社でのAI活用を一歩進めるための運用視点とそのインフラを解説します。企業で生成AIの活用や投資が増加することは様々な調査で予測されていますが、自社のユースケースに沿った活用を考える場合、社内のデータをどのように運用するかが重要です。活用したいデータを5W1Hの観点で整理してみると、様々な性質を持っていることが分かるでしょう。そうした多様なデータの効率的な運用を手助けするのが、データパイプラインという概念やDataOpsという手法です。前編では、データパイプラインやDataOpsが企業のAI活用をどのように加速させるかについて紹介します。
あらゆる人がAI利用できる今、次のステップ
2022年11月に「ChatGPT」が公開されてから、生成AIや大規模言語モデル(LLM)に関する話題は盛り上がりを見せています。2024年からは、NTTやNECによる生成AIサービスの提供や、ソフトバンクによる日本最大規模の学習量を持つ生成AIの完成などが予定されており、この盛り上がりはまだまだ続きそうです。
生成AIが登場する以前は、システムを作る側にも使う側にも特別な知識が必要とされ、一般に浸透しているとは言いがたい状況でした。現在では状況は一変し、特別な知識を必要とせずに、文字通りあらゆる人がAIを利用できるようになりました。そうした状況は調査結果にも表れており、ネットアップが2023年10月に発表した「データ複雑性レポート2023」では、約4分の3(72%)の企業が既に何らかの形で生成AIを活用していると回答をしています。

Q:あなたの組織ではAIをどのように活用していますか?
[クリックすると拡大します]
また、5社に3社以上(63%)がAIへの投資のために新たな予算を追加しており、ほぼ5社に2社(37%)が既存の取り組みから予算を再配分していると答えています。

(左)Q:AIへの投資予算の増額はどこから?
(右)Q:AIイニシアチブを考慮した場合、既存のストレージベンダーをAIに利用すると思いますか、それとも新たなベンダーが必要になると思いますか?
[クリックすると拡大します]
このように様々な企業で生成AIの検討や活用が進むことで、自社のビジネスに活用する上で以下の3つのパターンがあることも分かってきました。
- 独自モデルのスクラッチ開発:GPT-3.5、GPT-4のような大規模モデルを自社で独自に開発する活用方法。大量の高品質のデータ、コンピューティングリソースが必要となる
- 既存モデルのファインチューニング:公開されている既存モデルに特定のドメイン知識を獲得させることで、自社のユースケースに沿ったモデルに微調整する活用方法。スクラッチ開発よりも必要なデータやコンピューティングリソースは少ない
- 検索拡張生成(RAG)による自社データの参照:ベクトル化した自社データを既存モデルと組み合わせる活用方法。モデルの開発やファインチューニングは不要だが、自社データの収集やベクトルデータベースの構築などが必要となる
いずれの活用パターンでもAI活用を進める上で重要となるのが、AIで活用するデータとモデルをどのように運用していくかという観点です。そもそも、既存モデルも大量なデータを学習することで作られています。既存モデルだけでは実現できない自社のユースケースに沿ったAI活用を行う場合は自社のデータを活用する必要があるためです。
次頁からは、生成AIやLLMを念頭に一歩踏み込んだ活用をする際に重要となる運用観点での考え方とそのインフラについて解説します。
まずは、多様な社内データの性質を整理する
AI活用の運用観点を考える前に、AI活用の元となるデータ自体について考えてみましょう。
たとえば、生成AIやLLMを考えた場合、活用元となるデータとして一般的に使われるものは、社内の製品ドキュメント、顧客の購買やサポート情報の履歴、映像や画像などのメディアといったものです。これらの多様で大量なデータを効率的にAIに活用するためには、データの性質を理解することが重要となります。データの性質を理解するための軸はいろいろとありますが、ここでは5W1Hでデータを考えてみましょう。
When(いつ)
データの収集時点と頻度を把握することは重要です。社内の製品ドキュメントは、製品のリリースやアップデートに合わせて作成されます。顧客情報は、必要に応じてCRMなどのシステム上に登録されます。また、映像や音声の場合はリアルタイムに生成されることがあります。すなわち、データの鮮度やリアルタイム性に応じて、適切なタイミングでデータを収集する仕組みを構築する必要があります。
Where(どこで)
データは様々な場所に存在します。前述の通り社内の製品ドキュメントは、ローカルのPC上で編集作業が行われ、ファイルサーバー上やクラウド上のオンラインストレージに保存されます。顧客情報はオンプレミスまたはクラウド上のデータベースに保存されることが一般的です。映像や音声の場合は、エッジで生成され、ネットワークを介して収集する必要があります。データの分散保存によって異なる保存場所が存在する場合は、保存場所ごとにデータの収集仕組みを考慮する必要があります。
Who(誰が)
データのオーナーシップを明確にすることは重要です。データのオーナーは、データの管理と保護に責任を持ちます。組織内でデータのガバナンスを確立するために、データオーナーシップを明確にする必要があります。それにより、経営者や関係部署がデータの管理と保護を適切に行い、データ活用の一貫性を確保することができます。
What(何を)
データには様々な形式や種類があります。社内の製品ドキュメントは、オフィスファイル形式(Word、Excelなど)で保存されます。顧客情報は、顧客データベースなどの構造化データとして保存されます。非構造化データには、映像や音声などのメディアファイルがあります。データの種類を把握することで、適切な前処理や解析手法が選択可能です。
Why(なぜ)
AIに限らず、データの利活用を行う際、どのような課題を解決したいかといった課題設定が重要です。課題を設定することで、その解決に必要なデータとその鮮度を絞り込むことで収集や前処理など具体的な方法が決まってきます。また、課題設定と共に、施策による効果を確認できる数値目標を設定し、継続的に監視をする必要もあります。
How(どのように)
データを収集するためには、適切な方法や手続きを選択する必要があります。ファイルサーバー上のデータを収集する場合、NFS(Network File System)やCIFS(Common Internet File System)などのプロトコルを使用してデータにアクセスします。データベースからのデータ収集では、適切なアカウントとデータベース固有のプロトコルを使用。また、リアルタイムに生成されるデータの場合、適切な通信プロトコルやデータ収集のためのエッジデバイスとの連携の方法を考慮する必要があります。データの性質や保存場所に応じて、データの収集方法を適切に選択するとよいでしょう。
以上のように、5W1Hの観点でデータを整理してみることで、利活用を行うデータが様々な性質を持っていることがおわかりいただけたでしょうか。これらの要素を考慮しながら、データの活用や運用における重要な観点を把握し、成功に向けた戦略を策定していくとよいでしょう。
データサイエンティストの手を煩わせない手法
「データサイエンティストはデータの準備に8割の時間をかけている」という言葉を聞いたことはありませんか。せっかく高給なデータサイエンティスト人材を採用しても、実際にAIモデルの開発などを行う時間は2割程度しかないということを表わすためによく利用される表現です。これは、2016年にCrowdFlower(現、Figure Eight)が行った調査が元となっています。現在ではかなり改善されており、約4割程度という調査結果も公表されています(Anaconda「2022 State of Data Science」より)。
そもそも、なぜデータサイエンティストがデータ準備に時間をかけるのでしょうか。ここまでの説明でわかるかもしれませんが、活用元のデータは多様な性質を持ち、それらを収集する仕組みが整備できていない、もしくは、整備できていても複雑化してしまっていることが一つの要因となります。
では、実際にそうしたデータの運用を行う際、どのようにすれば仕組みをシンプルに保ち、データサイエンティストを煩わせることなく活用できる状態にできるのでしょうか。その手助けになるのが、「データパイプライン」という概念と「DataOps」という手法です。
データパイプラインとは、以下のような様々なデータを収集、整形、蓄積、活用する一連の処理プロセスをパイプラインに見立てたものです。

データパイプライン自体は、古くからあるもので、具体的な基盤を実装する際のベストプラクティスが固まっています。たとえば、簡単な分析や視覚化といった用途では蓄積レイヤーとしてDWHを、AIやビッグデータといった用途では蓄積レイヤーとしてオブジェクトストレージのデータレイクを利用することが現在では一般的になっています。いきなりすべての基盤を整備するのではなく、以下のようなデータパイプラインの全体像をイメージしながら必要に応じて少しずつ基盤の実装をしていく進め方がおすすめです。
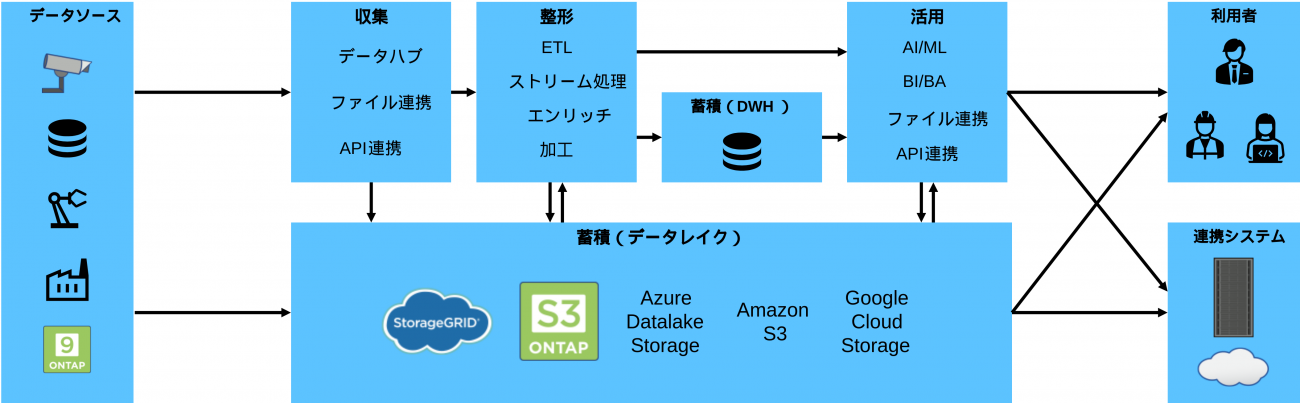
このように、データの収集からAI活用までを、ベストプラクティスに沿ったデータパイプラインの構成を参考にしつつ、共通基盤として整備していくことで、最小限の労力で実現可能となります。
DataOpsとは、高品質なデータを俊敏にかつ継続的に処理できるようにするためのデータマネジメント手法です。アプリケーション開発のプラクティスとして浸透しているDevOpsの考え方をデータの領域に応用したもので、2018年にGartnerのハイプ・サイクルに取り上げられたことで浸透しつつあります。
DevOpsのプラクティス同様、高品質データを迅速に提供するといった目的に対して、データパイプラインの各プロセスを自動化しつつ、状況をモニタリングし継続的に改善を行います。また、前項でも説明しましたが、データは様々な所有者によって分散して保存されています。経営層は現場に適切な権限を与えて、「高品質なデータを俊敏かつ継続的に処理する」という共通の目的を持って事業部間で連携できるよう支援する必要があります。そうすることで、各事業部が協調してデータの標準化やプロセスの見直しが行えるようになります。
具体的な手段という点では、「Apache Airflow」など DataOpsを支援するためのオープンソースツールやソフトウェアもあるので、必要に応じて取り入れることで、効率的にDataOpsを進めることができるでしょう。
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.