
In the most recent season of BigQuery Spotlight , we discussed key concepts like the BigQuery Resource hierarchy , query processing , and the reservation model . This blog focuses on extending those concepts to operationalize workload management for various scenarios.
Source: BigQuery workload management best practices
We will discuss the following topics:
- BigQuery’s Flexible Query Cost Options
- Workload Management Key Concepts
- Reservation Applications Patterns
- Capacity Planning Best Practices
- Automation Tips
BigQuery’s flexible query cost options
BigQuery provides predictable and flexible pricing models for workload management. There are mainly 2 types: On-demand pricing and Flat-rate pricing. You can easily mix and match these pricing models to get the best value for money.
With on-demand pricing, you pay per query. This is suitable for initial experimentation or small workloads. Flat-rate pricing consists of short-term and long-term commitments. For short-term commitments or flex slots, you can buy slots for as little as 60 second durations. These enable burst use cases like seasonal spikes. With long-term commitments, you can buy slots per month or year. Monthly and annual commitments are the best choice for on-going or complex workloads that need dedicated resources with fixed costs.
Workload management
In this section we will cover three key concepts: Commitments, Reservations and Assignments
With flat-rate pricing you purchase a commitment, where you purchase a dedicated number of BigQuery slots. The first time you buy a slot commitment, BigQuery creates a default reservation and assigns your entire Google Cloud Organization to it. Commitments are purchased in a dedicated administration project, which centralizes the billing and management of purchased slots. Slots are a regional resource, meaning they are purchased in a specific region or multi-region (e.g. US) and can only be used for jobs used on data stored in that region.
A reservation is a pool of slots created from a commitment. An assignment is used to allocate slots within a reservation to a project, folder or the entire organization. If you don’t create any assignment, BigQuery automatically shares the slots across your organization. You can specify which jobs should be using each reservation by indicating a job type of QUERY, PIPELINE (which includes LOAD, EXTRACT, and COPY jobs) or ML_EXTERNAL. You can also force a specific project to leverage on-demand slots by assigning it to a NONE reservation.

Check the managing your workloads and reservations documentation to learn more about using these concepts.
Resource Hierarchy
Each level in the GCP resource hierarchy inherits the assignment from the level above it, unless you override it. However, the lowest granularity of slot assignment always takes precedence. For example, let's say the organization is assigned to the “default” reservation. Any folder or project (like Project F) in the org will use the corresponding 100 slots. However, the dedicated reservation assignments for Storage (300) and Compute (500) folders will take precedence over the “default” reservation. Similarly, Project E’s “compute-dev” assignment with 100 slots will take precedence. In this case, precedence means that they will leverage the available slots from the “storage-prod” and “compute-prod” reservations before pulling from other reservations.
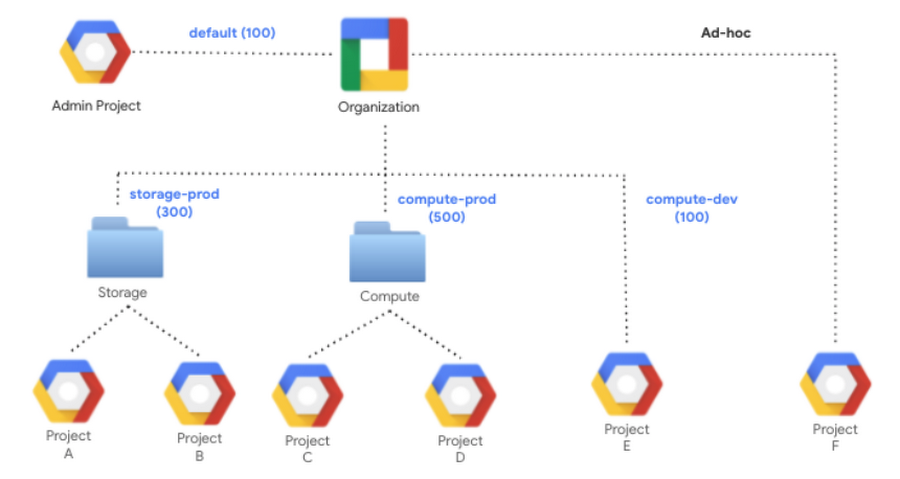
Idle slot sharing
BigQuery optimizes resource utilization with its unique idle slot sharing capability, not found in any other cloud based data warehouses, which allows any idle slots in a reservation to be available for other reservations to use. As soon as the reservation needs that capacity back, it gets it while queries consuming idle slots simply go back to using their resources as before. This happens in real-time for every slot. This means that all capacity in an organization is available to be used at any time.
Reservation applications patterns
Priority based allocation
Organizations can leverage priority based slot consumption using reservations and idle slot sharing. Reservations with high-priority or low-priority can be used for frequent movement of jobs in and out of the critical and non-critical projects respectively. You can leverage reservations with a small number of slots, and with the idle slots sharing option disabled, to handle expensive queries or ad-hoc workloads. You can also disable the idle slot sharing option when you are looking to get slot estimates for proof-of-concept workloads. Finally, the default reservation, or reservations with no slots can be used for running jobs with lowest priority, projects assigned to these reservations will only use idle slots.
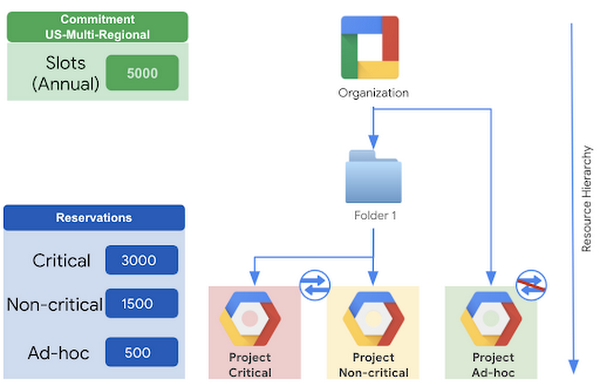
For example,
- A company has a 5000 slot annual commitment for their organization
- All projects in the organization are sharing these 5000 slots (see BigQuery fair scheduling for more details)
- Without flat rate pricing, they have found that some critical business reports are delayed, or they are running after the non-critical ones
- Additionally, some unapproved or ad-hoc workloads are consuming a lot of slots
- Instead, we would recommend that they create 3 compute projects
- Critical – assigned to a reservation with 3000 slots
- Non-critical – assigned to a reservation with 1500 slots
- Idle slots are freely consumed by the above 2
- Ad-hoc – assigned to a reservation with 500 slots and idle slots sharing disabled
- With this method, critical workloads are guaranteed at least 3000 slots, non-critical workloads are guaranteed at least 1500 slots, and ad-hoc workloads are guaranteed to consume no more than 500 slots
Mixed-mode reservation
Organizations do not need to pick just one pricing method, instead they can leverage flat-rate for some use cases and on-demand for others. Many BigQuery administrators chose to use an on-demand project for loading data. However, if you need to guarantee that data is loaded using a certain number of slots (ensuring a faster turnaround time), then you can leverage assignments for LOAD jobs.
Additionally, on-demand projects can be useful for predictable workloads that are cost effective. Below, we highlight an example of mixing and matching both pricing models in the same organization.
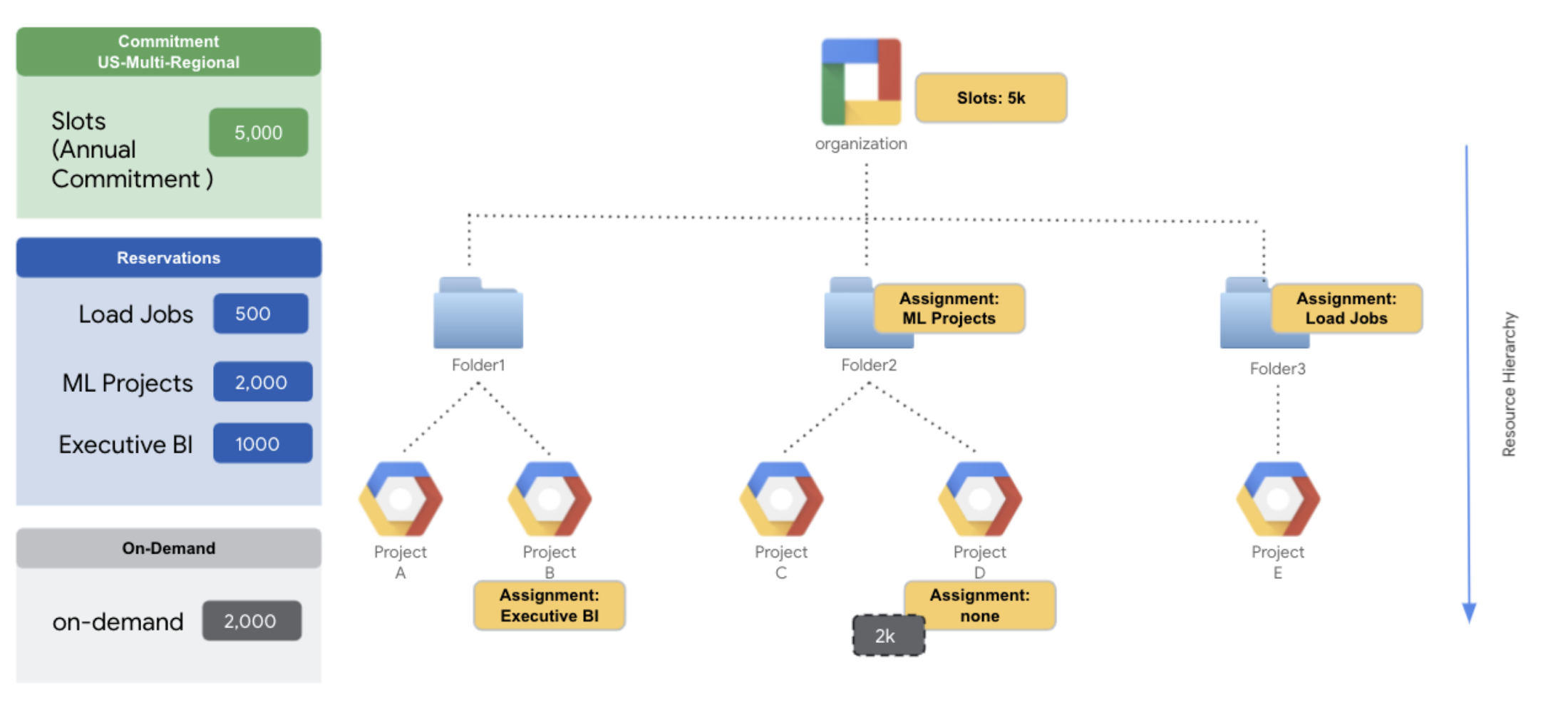
- Folder 1 projects have access to all the idle slots up from the 5k commitment.
- Project B has been explicitly assigned to the ‘Executive BI’ reservation with 1000 slots – to make sure project B gets a minimum of 1000 slots for critical analytics workloads.
- Folder 2 projects also have access to all the idle slots from the 5k commitment
- Folder 2 has also been assigned to the ‘ML Projects’ reservation – to make sure that projects within the folder have access to a minimum of 2k slots for ML activities.
- However, project D has been explicitly assigned to the reservation called ‘none’ to have that project use on-demand slots instead of any slots from the commitment. This is because it is more cost effective for this team to run predictable transformation workloads for machine learning activity in this project, which will have access to a pool of 2k on-demand slots.
- Folder 3 has been assigned the reservation ‘Load Jobs’ for ingestion workloads. Therefore, project E would have access to minimum 500 slots for critical data load with access to any additional idle slots from org level reservation.
Capacity planning best practices
The following are general guidelines for pricing options for given workloads:
- For highly interactive compute projects, we recommend that you test performance and concurrency needs to assign the proper number of committed slots to the project (more on this below).
- For projects with a low interactivity i.e. mainly batch processes with high data processing, we recommend using on-demand slots as a better cost effective option.
- High-priority workloads with strict SLAs such as critical BI reports and ML models would benefit from using dedicated slots.
- During use case on-boarding, make sure to review the dataset sizes and understand the batch jobs. Potential load sizing can be done via estimation or through technical proof-of-concepts.
- Actively monitor slot utilization to make sure you have purchased and assigned an optimal number of slots for given workloads.
Scaling throughput with slots

- 【High Speed RAM And Enormous Space】16GB DDR4...
- 【Processor】Intel Celeron J4025 processor (2...
- 【Display】21.5" diagonal FHD VA ZBD anti-glare...
- 【Tech Specs】2 x SuperSpeed USB Type-A 5Gbps...
- 【Authorized KKE Mousepad】Include KKE Mousepad

- 【EFFICIENT PERFORMANCE】ACEMAGIC Laptop...
- 【16GB RAM & 512GB ROM】Featuring 16GB of DDR4...
- 【15.6" IMMERSIVE VISUALS】This 15.6 inch laptop...
- 【NO LATENCY CONNECTION】The laptop computer...
- 【ACEMAGIC CARE FOR YOU】 This slim laptop will...
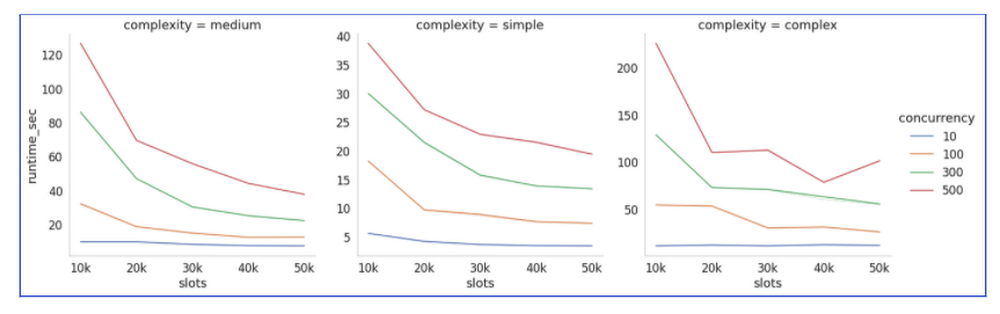
BigQuery dynamically re-assesses how many slots should be used to execute each stage of a query, which enables powerful performance with respect to throughput and runtime. The following chart displays how BigQuery scales for throughput with an increase in the number of available slots. The chart below highlights throughput test comparison against traditional databases (TD: black line). The test was done with more than 200 TB of data with various degrees of query complexity, and the throughput was measured using number of queries completed within 20 min for the given slot capacity.
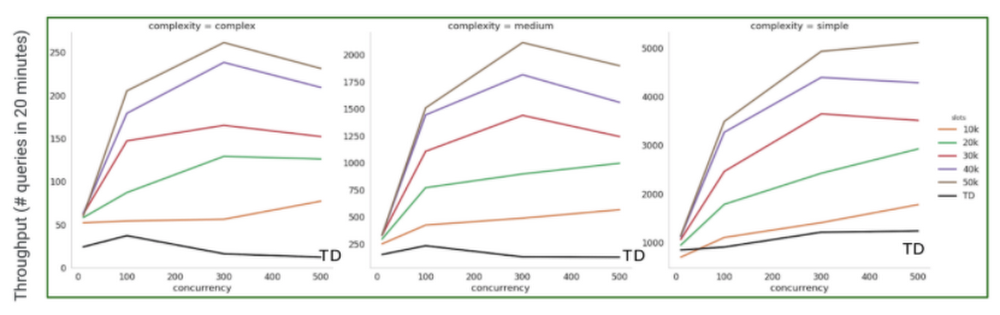
Leveraging the performance test metrics above, one can estimate the number of slots needed for simple to medium complexity queries to achieve the desired level of throughput. In general, BigQuery’s throughput increases with a small increase in the number of concurrent queries. However, for larger increases, there are other options to achieve the desired level of throughput. For example, in the chart above, if the number of concurrent queries increases from 200 to 300 for simple queries, there are two options to achieve the desired level of throughput:
- Fixed slots: With fixed slots capacity, let's say 10K slots, the throughput increases from 1000 to 1200 (as seen above). This is due to BigQuery’s fair resource sharing and dynamic optimization for each step of the query. So, if the average runtime is not impacted, you can continue to use the same capacity (or fixed slots). However, you need to monitor and ensure that the average runtime is not dropping below the acceptable SLA.
- Increased slot capacity: If you need the same or better runtime, and higher throughput, for workloads with more concurrent queries than you would need more slots. The chart shows how providing more slots results in more throughput for the same number of concurrent queries.
Scaling run-time with slots
BigQuery’s query runtime depends on the four main factors: the number of slots, the number of concurrent queries, the amount of data scanned and the complexity of the query. Increasing the number of slots results in a faster runtime, so long as the query work can continue to be parallelized. Even if there are additional slots available, if a part of the query cannot be delegated to “free” slots then adding more slots will not make it run faster. In the chart below, you can see that for complex queries the runtime changes from 50 seconds to 20 seconds when you increase slot capacity from 20k to 30k (with 100 concurrent queries).
You can test out your own query runtime and throughput to determine the optimal number of slots to purchase and reserve for certain workloads. Some tips for running BigQuery performance testing are:
- Use large datasets, if possible > 50 TB for throughput testing
- Use queries of varying complexity
- Run jobs with a varying amount of available slots
- Use Jmeter for automation (check resources in Original Posterformance_testing/jmeter" target="_blank" rel="noreferrer noopener">github)
Create trend reports for:
- Avg slot usage and query runtimes
- Number of concurrent queries
- Throughput (how many queries complete over X duration of time)
- Slot utilization (total slot usage / total available capacity for X duration of time)
- Avg. wait time
Load slots estimation workflow
If you are looking for guaranteed SLAs and better performance with your data ingestion, we recommend creating dedicated reservations for your load jobs. Estimating slots required for loading data is easy with this publicly available load slot calculator and the following estimation workflow.
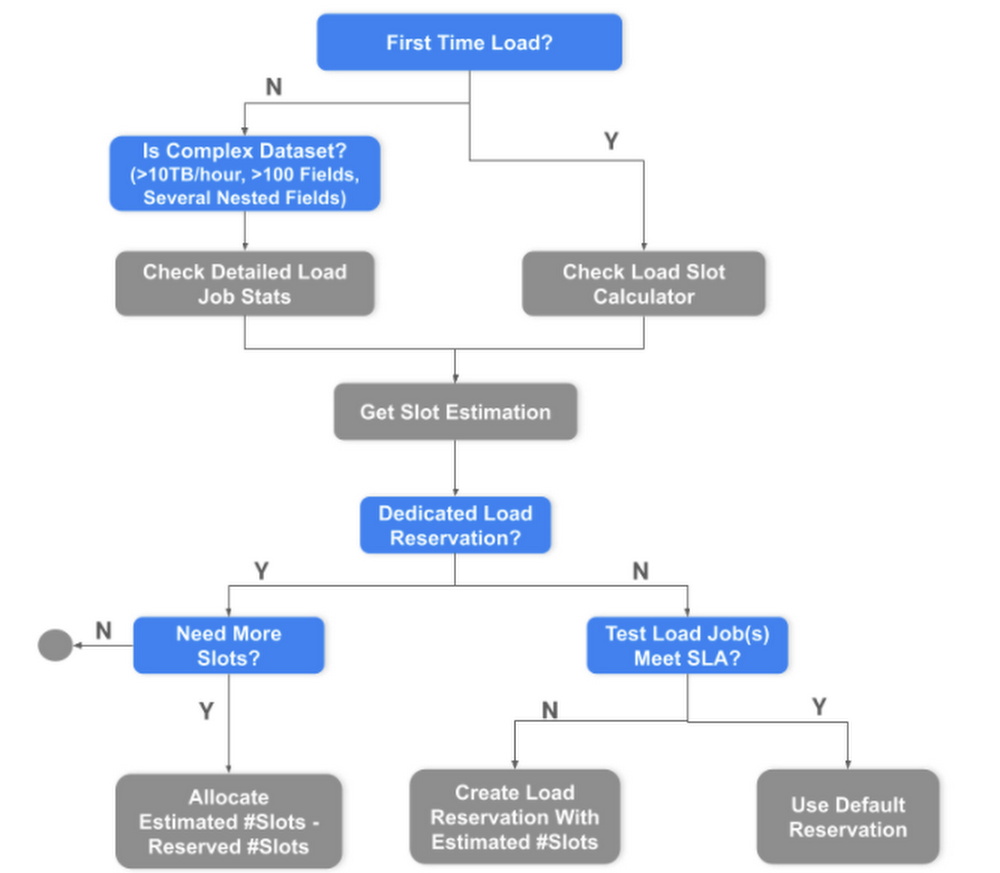
The following factors need to be considered to get load slot estimations:
- Dataset size
- Dataset Complexity: Number of fields | Number of nested/repeated fields
- Data Format/ Conversion: Thrift LZO | Parquet LZO | Avro
- Table Schema: Is the table Partitioned or Clustered?
- Load frequency: Hourly | Daily | Every n-hours
- Load SLA: 1 hour for hourly partition loads | 4 hours for daily/snapshot loads
- Historical Load Throughput: Estimated data size loaded per 2K slots per day
Automation tips
Optimization with flex slots

- [High Speed RAM And Enormous Space] 64GB...
- [Processor] Intel Core i7-13700 (16 Cores, 24...
- [Tech Specs] 1 x USB 3.2 Type-C, 4 x USB 3.2...
- [Operating System] Windows 11 Home - Beautiful,...

- AMD Ryzen 5 3600 6-Core 3.6 GHz (4.2 GHz Turbo)...
- GeForce RTX 3060 12GB GDDR6 Graphics Card (Brand...
- 802.11AC | No Bloatware | Graphic output options...
- Heatsink & 3 x RGB Fans | Powered by 80 Plus Gold...
- 1 Year Warranty on Parts and Labor | Lifetime Free...

- 【Excellent performance】 Laptop is equipped...
- 【Do Your Tasks Easily】 Laptop computer comes...
- 【Amazing Visuals】 The 17.3-inch laptop...
- 【Poweful Cooling System】Laptops are equipped...
- 【External Ports Design】Notebook computer comes...
Consider a scenario with a compute project that has spikes in analysis during the last five days of every month, something common in many financial use cases. This is a predictable compute resource needed for a short duration of time. In contrast, there could be spikes on completely ad-hoc and non-seasonal workloads. The following automation can be applied to optimize cost and resource utilization without paying for peak usage for the long commitment periods.
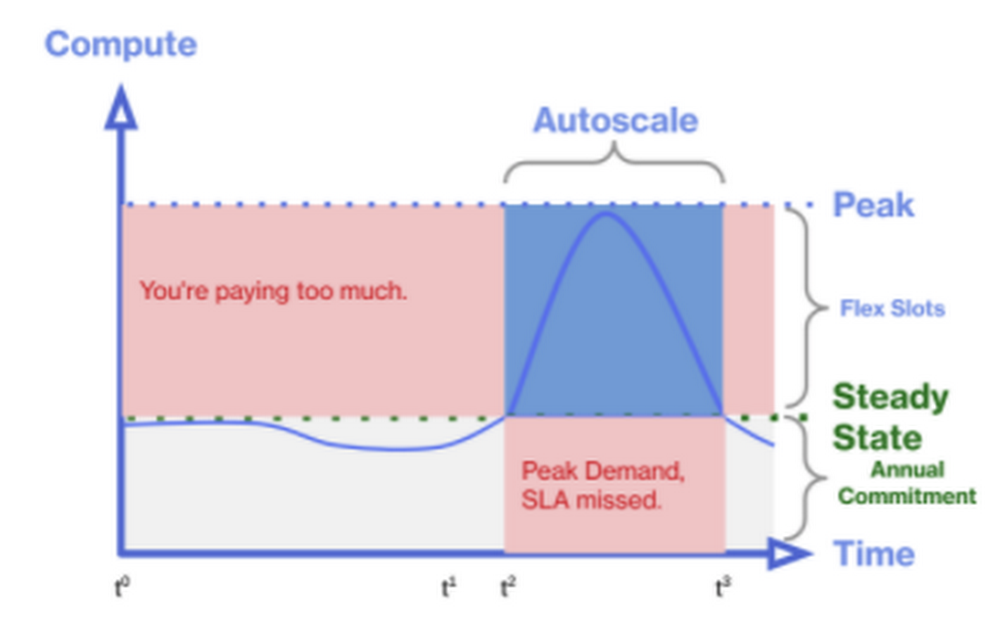
A better solution would be to monitor for a rise in slot consumption and purchase flex slots, either using the Reservation API or Data Control statements (DCL), then assign the slots to the necessary resources. You can use quota settings, automate the end-to-end flex slots cycle with alerts that trigger the flex slot purchase. For more details, check out this Practical Example for leveraging alerts and an example of putting everything together as a flow.
Take action
By default, BigQuery projects are assigned to the on-demand pricing model, where you pay for the amount of bytes scanned. Using BigQuery Reservations, you can switch to flat-rate pricing by purchasing commitments. Commitments are purchased in units of BigQuery slots. The cost of all bytes processed is included in the flat-rate price. Key benefits of using BigQuery Reservations include:
- Predictability: Flat-rate pricing offers predictable and consistent costs. You know up-front what you are spending.
- Flexibility: You choose how much capacity to purchase. You are billed a flat rate for slots until you delete the capacity commitment. You can also combine both the billing models!
- Commitment discounts: BigQuery offers flat-rate pricing at a discounted rate if you purchase slots over a longer duration of time (monthly, annual).
- Workload management: Slot commitments can be further bucketed into reservations and assigned to BigQuery resources to provide dedicated capacity for various workloads, while allowing seamless sharing of any unused slots across workloads.
- Centralized purchasing: You can purchase and allocate slots for your entire organization. You don't need to purchase slots for each project that uses BigQuery.
- Automation: By leveraging flex slots for seasonal spikes or ad-hoc demand rise, you can manage capacity to scale in need. Additionally, you can automate the entire process!
With capacity planning in the works, it is important that you also have a framework in place for on-going monitoring of slots for continuous optimization and efficiency improvements. Check out this blog for a deep-dive on leveraging the INFORMATION_SCHEMA and use this data studio dashboard, or this Looker block, as a monitoring template.