This article describes how a fictional city planning office could use this solution. The solution provides an end-to-end data pipeline that follows the MDW architectural pattern, along with corresponding DevOps and DataOps processes, to assess parking use and make more informed business decisions.
Architecture
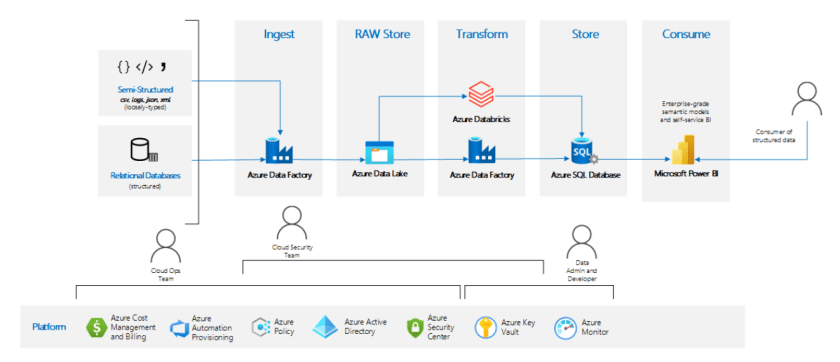
The following diagram shows the overall architecture of the solution.
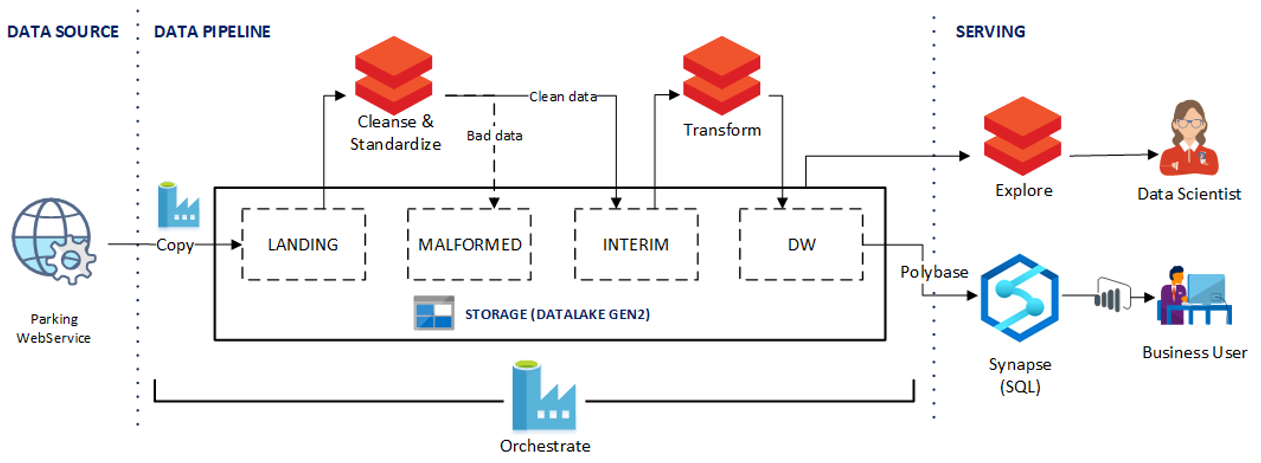
Dataflow
Azure Data Factory (ADF) orchestrates and Azure Data Lake Storage (ADLS) Gen2 stores the data:
- The Contoso city parking web service API is available to transfer data from the parking spots.
- There’s an ADF copy job that transfers the data into the Landing schema.
- Next, Azure Databricks cleanses and standardizes the data. It takes the raw data and conditions it so data scientists can use it.
- If validation reveals any bad data, it gets dumped into the Malformed schema.
Important
People have asked why the data isn’t validated before it’s stored in ADLS. The reason is that the validation might introduce a bug that could corrupt the dataset. If you introduce a bug at this step, you can fix the bug and replay your pipeline. If you dumped the bad data before you added it to ADLS, then the corrupted data is useless because you can’t replay your pipeline.
- There’s a second Azure Databricks transform step that converts the data into a format that you can store in the data warehouse.
- Finally, the pipeline serves the data in two different ways:
- Databricks makes the data available to the data scientist so they can train models.
- Polybase moves the data from the data lake to Azure Synapse Analytics and Power BI accesses the data and presents it to the business user.
Components
The solution uses these components:
Scenario details
A modern data warehouse (MDW) lets you easily bring all of your data together at any scale. It doesn’t matter if it’s structured, unstructured, or semi-structured data. You can gain insights to an MDW through analytical dashboards, operational reports, or advanced analytics for all your users.
Setting up an MDW environment for both development (dev) and production (prod) environments is complex. Automating the process is key. It helps increase productivity while minimizing the risk of errors.
This article describes how a fictional city planning office could use this solution. The solution provides an end-to-end data pipeline that follows the MDW architectural pattern, along with corresponding DevOps and DataOps processes, to assess parking use and make more informed business decisions.
Solution requirements
- Ability to collect data from different sources or systems.
- Infrastructure as code: deploy new dev and staging (stg) environments in an automated manner.
- Deploy application changes across different environments in an automated manner:
- Pipeline as Code: ensure the CI/CD pipeline definitions are in source control.
- Carry out integration tests on changes using a sample data set.
- Run pipelines on a scheduled basis.
- Support future agile development, including the addition of data science workloads.
- Support for both row-level and object-level security:
- The security feature is available in SQL Database.
- You can also find it in Azure Synapse Analytics, Azure Analysis Services (AAS) and Power BI.
- Support for 10 concurrent dashboard users and 20 concurrent power users.
- The data pipeline should carry out data validation and filter out malformed records to a specified store.
- Support monitoring.
- Centralized configuration in a secure storage like Azure Key Vault.
Potential use cases
This article uses the fictional city of Contoso to describe the use case scenario. In the narrative, Contoso owns and manages parking sensors for the city. It also owns the APIs that connect to and get data from the sensors. They need a platform that will collect data from many different sources. The data then must be validated, cleansed, and transformed to a known schema. Contoso city planners can then explore and assess report data on parking use with data visualization tools, like Power BI, to determine whether they need more parking or related resources.
Deploy this scenario
The following list contains the high-level steps required to set up the Parking Sensors solution with corresponding Build and Release Pipelines. You can find detailed setup steps and prerequisites in this Azure Samples repository.
Setup and deployment
- Initial setup: Install any prerequisites, import the Azure Samples GitHub repository into your own repository, and set required environment variables.
- Deploy Azure resources: The solution comes with an automated deployment script. It deploys all necessary Azure resources and AAD service principals per environment. The script also deploys Azure DevOps pipelines, variable groups, and service connections.
- Set up git integration in dev Data Factory: Configure git integration to work with the imported GitHub repository.
- Carry out an initial build and release: Create a sample change in Data Factory, like enabling a schedule trigger, then watch the change automatically deploy across environments.
Deployed resources
If deployment is successful, there should be three resources groups in Azure representing three environments: dev, stg, and prod. There should also be end-to-end build and release pipelines in Azure DevOps that can automatically deploy changes across these three environments.
For a detailed list of all resources, see the Deployed Resources section of the DataOps – Parking Sensor Demo README.
Continuous integration and continuous delivery
The diagram below demonstrates the CI/CD process and sequence for the build and release pipelines.
- Developers develop in their own sandbox environments within the dev resource group and commit changes into their own short-lived git branches. For example,
<developer_name>/<branch_name>. - When changes are complete, developers raise a pull request (PR) to the main branch for review. Doing so automatically kicks-off the PR validation pipeline, which runs the unit tests, linting, and data-tier application package (DACPAC) builds.
- On completion of the PR validation, the commit to main will trigger a build pipeline that publishes all necessary build artifacts.
- The completion of a successful build pipeline will trigger the first stage of the release pipeline. Doing so deploys the publish build artifacts into the dev environment, except for ADF.
Developers manually publish to the dev ADF from the collaboration branch (main). The manual publishing updates the Azure Resource Manager (ARM) templates in the
adf_publishbranch. - The successful completion of the first stage triggers a manual approval gate.
On Approval, the release pipeline continues with the second stage, deploying changes to the stg environment.
- Run integration tests to test changes in the stg environment.
- Upon successful completion of the second stage, the pipeline triggers a second manual approval gate.
On Approval, the release pipeline continues with the third stage, deploying changes to the prod environment.
For more information, read the Build and Release Pipeline section of the README.
Testing
The solution includes support for both unit testing and integration testing. It uses pytest-adf and the Nutter Testing Framework. For more information, see the Testing section of the README.
Observability and monitoring
The solution supports observability and monitoring for Databricks and Data Factory. For more information, see the Observability/Monitoring section of the README.
Considerations
The following list summarizes key learnings and best practices demonstrated by this sample solution:
Note
Each item in the list below links out to the related Key Learnings section in the docs for the parking sensor solution example on GitHub.
Next steps
If you’d like to deploy the solution, follow the steps in the How to use the sample section of the DataOps – Parking Sensor Demo README.
Solution code samples on GitHub
Observability/monitoring
Azure Databricks
Data Factory
Synapse Analytics
Azure Storage
Resiliency and disaster recovery
Azure Databricks
Data Factory
Synapse Analytics
Azure Storage
Videos
For a detailed walk-through of the solution and key concepts, watch the following video recording: DataDevOps for the Modern Data Warehouse on Microsoft Azure
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.