When building a Customer Data Platform (CDP), advertising and marketing Independent Software Vendors (ISVs) face a unique set of challenges. The ISV can help organizations with the heavy lifting required to build, secure, and maintain near real-time, high volume CDPs. However, architecting CDPs using traditional on-premises technologies can introduce multiple complexities and can limit deployment options. One strategy that may address these complexities is to use serverless technologies.
Serverless technologies feature automatic scaling, built-in high availability, and a pay-for-use billing model to increase agility, optimize costs, and reduce infrastructure management tasks such as capacity provisioning and patching. Using tools such as CloudFormation, each layer of the serverless CDP can be deployed on-demand in an independent manner to maximize portability and optimize performance.
A Software as a Service (SaaS) CDP usually has significantly more data in a multi-tenant environment than a single instance of a CDP. Clients of a SaaS solution need to continually expand across different channels, and often across many AWS Regions. In some cases, an ISV might have an existing infrastructure that was built before some of these modern capabilities and techniques were mature. Today, an ISV can build or even modernize an existing CDP and gain huge benefits from a serverless implementation.
This blog post explores how to use serverless technologies for the CDP. A modern, serverless CDP architecture can enable the ISV and the client companies to deliver in weeks instead of months, and provide a resilient infrastructure that supports agility and global deployment while maximizing operational efficiency and optimizing cost. This frees up technical resources to focus on differentiated product development instead of managing servers.
Serverless implementation of a CDP on AWS
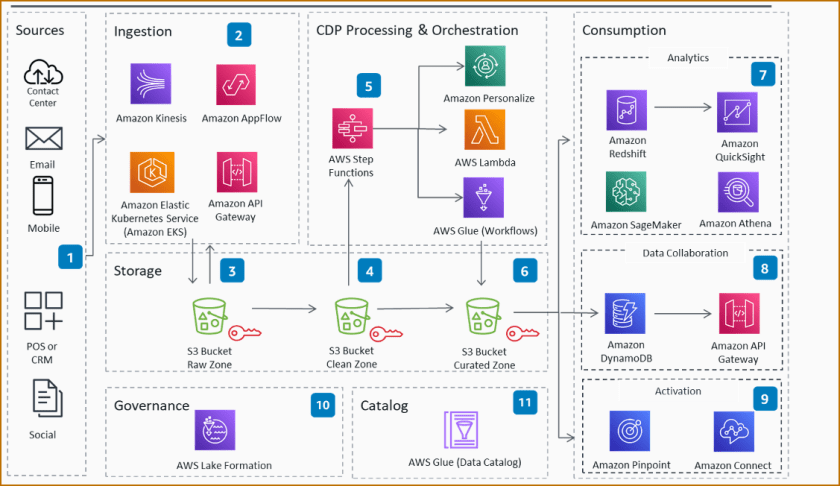
A serverless architecture uses AWS services that don’t require the configuration of a server to provide an implementation. Serverless technology allows you to focus more time on rapidly building different components of the marketing CDP. The benefits of a CDP include the collection, aggregation, and organization of customer data sources. Implementing the CDP using serverless technology reduces the need to focus on managing infrastructure while reducing time to market, increasing agility, and resulting in cost optimization. Figure 1 is an architecture diagram that describes how various data sources can be prepared for consumption in the component based Customer Data Platform.

Figure 1. Marketing CDP reference on AWS
- Source systems of customer data include customer interactions, clickstreams and call center logs.
- Data from customer touchpoints is ingested into the marketing customer data platform (CDP) data lake using Amazon Kinesis, Amazon AppFlow, Amazon EKS and an Amazon API Gateway.
- Ingested data is sent – in its original, immutable format – to an Amazon Simple Storage Service (Amazon S3) Raw Zone bucket
- Raw data is then transformed into efficient data formats – such as Parquet or Avro – and moved to a Clean Zone Amazon S3 bucket.
- CDP processing and pipeline orchestration is conducted using purpose-built data processing components and transformation libraries through AWS Step Functions and then Amazon Personalize, AWS Lambda, and AWS Glue.
- Data in the Amazon S3 Curated Zone is now ready for post-CDP-processing consumption and is organized by subject areas, segments, and profiles.
- The analytics layer uses Amazon Redshift, Amazon QuickSight, Amazon SageMaker and Amazon Athena to natively integrate with the Curated Zone for analytics, dashboards, ad hoc reporting, and ML purposes.
- Customer data is then aggregated across platforms and published using customer APIs for consumption using Amazon DynamoDB and an Amazon API Gateway.
- Amazon Pinpoint and Amazon Connect are used to activate multiple customer channels such as mobile push, voice, and email for targeted marketing communications.
- Using AWS Lake Formation, fine-grained access controls can be enforced on catalog tables, columns, and rows on the data lake.
- The resulting catalog in AWS Glue helps you manage both business and technical metadata, with versioning, at scale.
Serverless implementation for ingestion
There are several methods of ingesting customer data, both internal to a customer and from external sources. Serverless options for ingestion could provide benefits to an ISV like cost or agility but it depends upon the use case. Examining serverless options for ingestion should be part of any modernization effort. If the CDP needs to stream data sources and ingest that data in near-real time, the ISV can use Amazon Kinesis. If you want a more traditional extract, transform, and load (ETL) tool, AWS Glue offers a serverless option to generate code that can be customized. AWS Glue DataBrew offers a visual data preparation tool. For more advanced governance and control, you can use AWS Lake Formation. To ingest sources using an API, the Amazon API Gateway provides a serverless approach. If you need more control over the ingestion, the use of customized scripts in Amazon AppFlow or Amazon Managed Streaming for Apache Kafka (Amazon MSK) can provide a solution.
Serverless storage implementation
Amazon Simple Storage Service (Amazon S3) provides a serverless, cost-effective solution for virtually unbounded amounts of storage and read-write bandwidth. As per the reference architecture, there are three purpose-specific zones:
- A raw zone containing the original, immutable version of data
- A trusted zone which can be used as a working area to combine, enhance and clean the data
- A refined zone containing data ready for consumption by users and applications
This structure allows the improvement of customer data and profiles, and provides the ability to integrate various data sources and a structure that allows customer data to be recreated in a manner consistent with changing business rules.
Serverless cataloging implementation
The cataloging services provide a grouping of the elements contained in structured and unstructured data sources that is intuitive and easy to understand, similar to a single relational database. AWS Glue Data Catalog gives logical structure to the data lake by allowing users to define tables and columns on top of Amazon S3 data sets. This serverless solution integrates with other analytics tools to enable data discovery and consistent usage. Fine-grained governance and access can also be enforced by AWS Lake Formation.
Serverless processing
There are great choices for implementing processing, using serverless technologies. A CDP platform can package code and run on demand without servers using AWS Lambda or AWS Step Functions depending up the complexity of the processing pipeline. These services can enable complex processing on customer data and profiles. Amazon SageMaker is a great serverless choice for incorporating artificial Intelligence / machine learning into your processing stream. For processing using big data techniques Amazon EMR Serverless is a good serverless option.
Serverless implementation for consumption
Analytics for the CDP provides several serverless technologies that enable different types of insights. For interactive SQL queries that integrate with our serverless AWS Glue Catalog, there is Amazon Athena. Athena provides SQL access to various data source, and can also use federated query functionality to connect to third-party sources, even if that data is sitting on another cloud or in a vendor’s environment. Athena can also work as an interface (middleware) to other reporting solutions.
If performance is a concern, Amazon Redshift is fast, petabyte-scale data warehouse solution that has a serverless option and fully integrates with these solutions. For a data visualization tool that can be embedded in your application or work as a standalone portal, examine Amazon QuickSight.
To enable collaboration, many use cases can use Amazon API Gateway to securely publish and expose API endpoints for consuming applications. This allows data to be shared from a single source of truth to consumers that use customer data for their processes. Most customers want to activate their customer data through marketing or advertising campaigns. To activate marketing communication over voice, email, text, or in-app messaging, you can use a serverless service called Amazon Pinpoint. For an omnichannel contact center support, we recommend Amazon Connect, which uses AI/ML and the CDP data to analyze customer sentiment, implement chatbots, and authenticate voice callers.
Serverless implementation for governance
AWS Lake Formation simplifies the process of configuring and securing access to the CDP. It can help orchestrate processing and ingestion, as well as enforcing fine-grained access controls on data catalogs. Other services such as AWS Glue DataBrew or Amazon Macie can identify and help mitigate exposure of Personally identifiable information (PII). AWS Config enables you to assess, audit, and evaluate the configurations of your AWS resources to automate the evaluation of recorded configurations against desired configurations.
Conclusion
This post described just some of the serverless solutions that are managed by AWS that allow you to build a modern, low-cost, data lake-centric CDP architecture in an accelerated manner. A decoupled, component-driven architecture lets you start small and quickly add new services to each independent component of the CDP. Use the Data Analytics Lens for guidance on designing, deploying, and architecting your analytics solution workloads in the AWS Cloud. Using this framework, you will learn the architectural best practices for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud. Follow the links in this article to learn more about the services available in AWS that can help you build a serverless CDP.
Further reading
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.