コンピュータシステムの動きを可視化するためのツールやユースケースを紹介するObservability Conference 2022から、サイボウズのセッションを紹介する。セッションを担当したのはサイボウズ株式会社のストレージアーキテクトの武内覚氏だ。武内氏はCNCFのプロジェクトであるストレージオーケストレータRookのメンテナーとしても活動しているエンジニアだ。RookはKubernetesに適したストレージで、企業単位のコントリビューターとしてRed Hatなどとともにサイボウズの名前が挙げられていることから明らかなように、会社を挙げて積極的に活動していることがわかる。中でも武内氏は、Rookのコントリビュータの中でもトップ10に入る貢献をしていることがGitHubのページでも確認できる。
参考:https://github.com/rook/rook/graphs/contributors
 2022年3月の時点でRockに対して第9位の貢献を行っている武内氏
2022年3月の時点でRockに対して第9位の貢献を行っている武内氏
セッションの動画は以下から参照されたい。
動画:実践オブザーバビリティ ~ プロダクショングレード監視/ログ基盤とその実用例
このセッションではサイボウズが採用しているオブザーバビリティのユースケースを解説、特に後半ではサイボウズの中で発生した不具合に対して、ログとメトリクスを使って原因を解明したエピソードが解説されており、具体的にどうやってログから原因に辿り着けたのかをわかりやすく説明している。
最初に武内氏は一般的なオブザーバビリティの解説に続いて、サイボウズが考えるオブザーバビリティに必要な情報について解説を行った。
 システムを観測するために必要な情報はログとメトリクス
システムを観測するために必要な情報はログとメトリクス
オブザーバビリティと言えばログ、メトリクス、トレーシングの3つの要素が挙げられることが多いが、武内氏がログとメトリクスについてのみ解説を行ったのは、現状のシステムであればトレーシングまでは必要ないという発想だろうか。
 オブザーバビリティを高めるための方法論を解説
オブザーバビリティを高めるための方法論を解説
このスライドではオブザーバビリティを高めるための方法論を解説。メトリクスとログをローカルのサーバーに置かずに集約すること、集約されたデータの監視、そして異常を検知すること、最後にログとメトリクスを可視化するためのツールなどが必要であることを説明した。
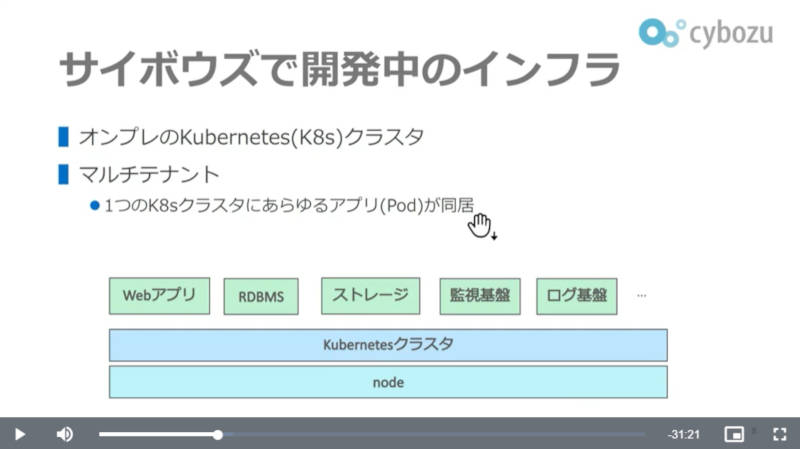 サイボウズのインフラストラクチャーはオンプレのKubernetesクラスターだ
サイボウズのインフラストラクチャーはオンプレのKubernetesクラスターだ
サイボウズのインフラは、ひとつのクラスターの上にアプリケーションからデータベース、ストレージなどが実装されているという。
 サイボウズのオブザーバビリティに使われているVictoriaMetrics
サイボウズのオブザーバビリティに使われているVictoriaMetrics
その中からオブザーバビリティのためのツールとして選択したのが、VictoriaMetricsとLoki、そしてGrafanaだ。この3つが現在のサイボウズのオブザーバビリティのための主要なツールということになる。
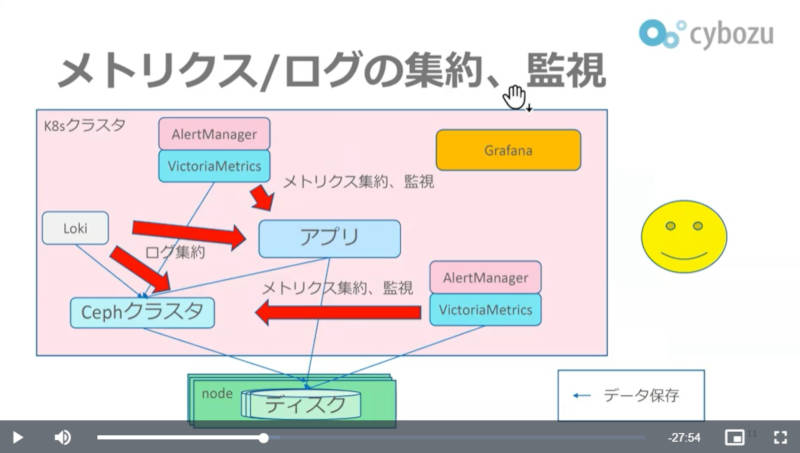 ログとメトリクス集約の仕組み
ログとメトリクス集約の仕組み
Kubernetes上で実行されるアプリケーションはVictoriaMetricsとLokiによってメトリクスとログが収集され、同じKubernetes上のCephの分散ストレージの中に集約される。上記のスライドにおいて、VictoriaMetricsとAlertManagerのセットが2つ存在するのは、それぞれアプリケーションとCephの監視用に独立しているからだ。メトリクスとログを集約するストレージのCephにトラブルが発生した際にメトリクスが使えなくなることを防ぐために、Ceph専用のVictoriaMetricsを用意してストレージの問題を切り離すように二重構成になっているわけだ。またログの収集はFluentbitを使っているという。
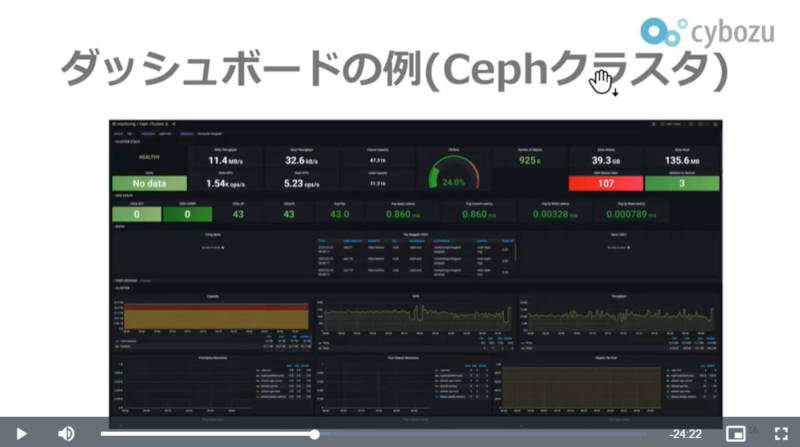 Grafanaで表示されるダッシュボードの例
Grafanaで表示されるダッシュボードの例
Grafanaは可視化ツールとしてVictoriaMetrics、Lokiのデータをダッシュボードとして表示&操作するために使われている。
Kubernetesのオブザーバビリティ用ツールと言えばまず思い起こされるのは、CNCFのプロジェクトでもあるPrometheusだろう。サイボウズがVictoriaMetricsを選択したのは、Prometheusとプラグインなども含めて互換性があること、HA(High Availability)構成が基本機能として組み込まれていること、そしてメトリクスを保存するデータストアが長期保存に向いていることなどを挙げた。
武内氏に確認したところ、アプリケーション用とメトリクスを集約するCephのためのVictoriaMetricsは、それぞれ2セットずつ用意されてHA構成として実装されているという。実際にPrometheusに対する長所がそのまま活かされている構成だ。
 VictoriaMetricsを選んだ理由を説明
VictoriaMetricsを選んだ理由を説明
このスライドでアプリケーションの監視をするVictoriaMetricsとCephストレージの監視を行うVictoriaMetricsの概要が解説されている。
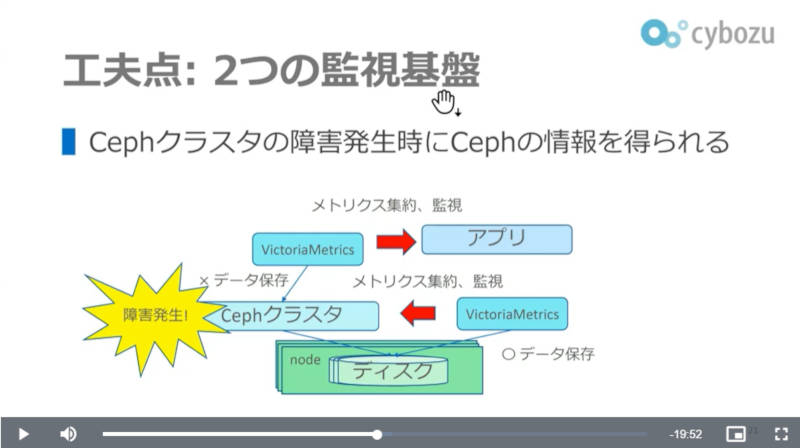 2つのVictoriaMetricsで構成されるメトリクス監視構成
2つのVictoriaMetricsで構成されるメトリクス監視構成
またアラートなどの通知に関してもすべてを運用担当者に送信するのではなく、アラートの重大さによってSlackのチャンネルを使い分けることなどが工夫点として説明された。
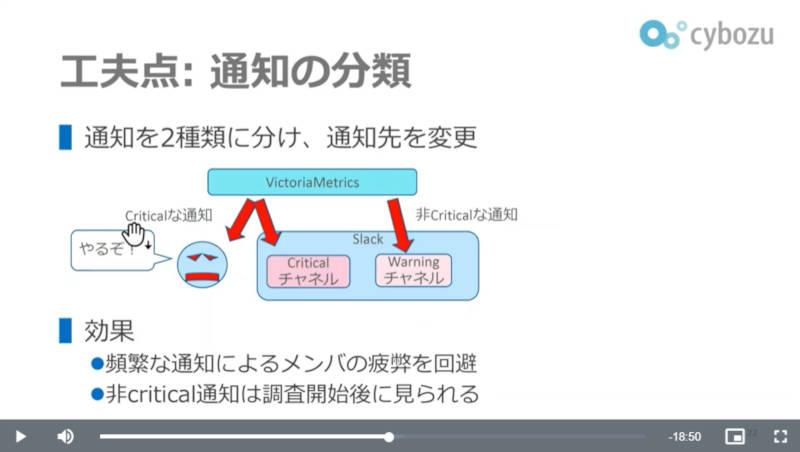 通知を重大なものとそれ以外に分けることで担当者の疲弊を避ける工夫
通知を重大なものとそれ以外に分けることで担当者の疲弊を避ける工夫
また現時点での課題としてVictoriaMetricsは二重化されて可用性を高めているが、ログに関しても同様に別のCephクラスター専用のLokiを用意する予定であることが説明された。
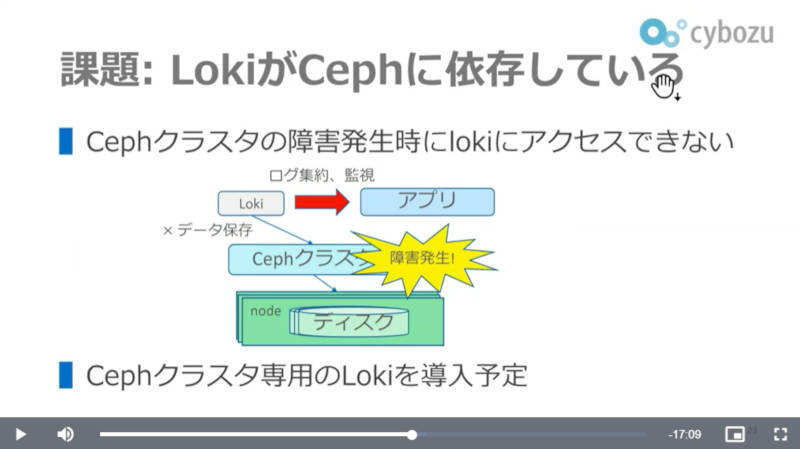 Lokiの二重化も計画中
Lokiの二重化も計画中
さらに通知に関しては、単にエラーメッセージや異常値を示すだけではなく、「こういうメッセージや値が出たら何をするべきか?」という具体的な操作までを含んだ内容にすることで、経験が浅い運用担当者であっても次に何をするのかを理解できるようにしたことを説明した。
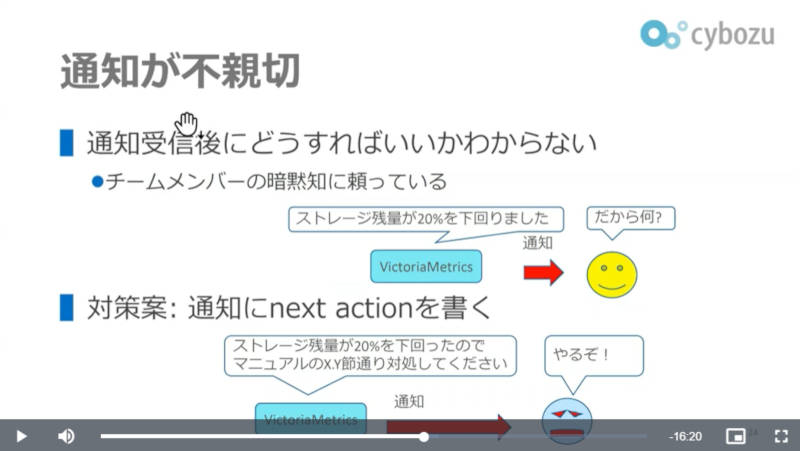 運用担当者に具体的なアクションを提示するメッセージを加える工夫
運用担当者に具体的なアクションを提示するメッセージを加える工夫
ここからは実際に発生したエラーを使ってエラーの原因を解明していく様子を解説した。
 オブジェクトストレージの障害を使って原因究明を解説
オブジェクトストレージの障害を使って原因究明を解説
この例はCephが使うRADOS GatewayのPodにアクセスができなくなるという障害だ。
 障害切り分けとこの障害において幸運だったことを説明
障害切り分けとこの障害において幸運だったことを説明
この障害では、Podが自ら終了してしたのか、それとも外部から強制終了させられているのかを切り分けることが最初のステップだったことを説明。そしてLokiが収集するログに関しては最新の1時間がノードのストレージにも保存される仕様であったことで、Cephに集約されたログが読めないという事態を避けられたとして、これは幸運だったと語った。
ログを分析したところ、Cephのシャーディング処理の中でKubernetesの死活確認のためのProbeを正常に返せなかったために、KubernetesがPodを強制終了させられていることがわかった。再起動されたPodも同様に強制終了され、起動~強制終了を繰り返していたことが解明されたという。
 障害の原因に対する仮説
障害の原因に対する仮説
今回は、Lokiのログが残っていたために原因解明が行えたとして、前述したLokiの二重化が必要だと説明した。
 改善点を解説
改善点を解説
最後にオブザーバビリティに関するポイントとして、最初から完全を目指さずシンプルなログ/メトリクスの基盤を作り、それの改善を続けること、定期的にダッシュボードを確認することで「正常値」に対する感覚を身に付けること、そして問題検知のためにはオブザーバビリティへの投資は惜しまないことなどを解説してセッションを終えた。
 オブザーバビリティへ投資を惜しまないことがポイント
オブザーバビリティへ投資を惜しまないことがポイント
最後の投資を惜しまないという部分には実際に障害を経て「もしもこれがなかったら原因がわからなかったかもしれない」という実体験に基づいた感想だろう。日常、クルマを運転する時に車両保険やJAFのサービスに考えが及ぶ人は少ないだろうが、実際に事故や故障に遭遇してしまった場合にその効果を痛感するということとも通じる感覚かもしれない。障害解決までの時間短縮以外にも運用担当者の疲労までも軽減できたという体験は、コストを理由にオブザーバビリティの強化に腰が引けている管理者にとって参考になる情報だろう。
VictoriaMetricsについては以下の公式サイトを参照されたい。
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.