
So far in this series, we’ve been focused on generic concepts and console-based workflows. However, when you’re working with huge amounts of data or surfacing information to lots of different stakeholders, leveraging BigQuery programmatically becomes essential.
Source: BigQuery Admin reference guide: API landscape
In today’s post, we’re going to take a tour of BigQuery’s API landscape – so you can better understand what each API does and what types of workflows you can automate with it.
Leveraging Google Cloud APIs
You can access all the Google Cloud APIs from server applications with our client libraries in many popular programming languages, from mobile apps via the Firebase SDKs, or by using third-party clients. You can also access Cloud APIs with theGoogle Cloud SDK tools or Google Cloud Console. If you are new to Cloud APIs, see Getting Started on how to use Cloud APIs.
All Cloud APIs provide a simple JSON HTTP interface that you can call directly or via Google API Client Libraries,Most Cloud APIs also provide a gRPC interface you can call via Google Cloud Client Libraries, which provide better performance and usability. For more information about our client libraries, checkout Client Libraries Explained.
BigQuery v2 API
The BigQuery v2 API is where you can interact with the “core” of BigQuery. This API gives you the ability to manage data warehousing resources like datasets, tables (including both external tables and views), and routines (functions and procedures). You can also leverage BigQuery’s machine learningcapabilities, and create or poll jobs for querying, loading, copying or extracting data.
Programmatically getting query results
One common way to leverage this API is to programmatically get answers to business questions by running BigQuery queries and then doing something with the results. One example that quickly came to mind was automatically filling in a Google Slide template. This can be especially useful if you’re preparing slides for something like a quarterly business review – where each team may need a slide that shows their sales performance for the last quarter. Many times an analyst is forced to manually run queries and copy-paste the results into the slide deck. However, with the BigQuery API, Google Slides APIand a Google Apps Script we can automate this entire process!
If you’ve never used Google Apps scripts before, you can use them to quickly build serverless functions that run inside of Google Drive. Google Apps Scripts already have the Google Workspace and Cloud Libraries available, so you simply need to add the Slides and BigQuery service into your script.
In your script you can do something like loop through each team’s name and use it as a parameter to run a parameterized query. Finally, you can use that to replace a template in that team’s slide within the deck. Check out someexample code here, and look out for a future post on more details on the entire process!
Loading in new data
Aside from querying existing data available in BigQuery, you can also use the API to create and run a load job to add new data into BigQuery tables. This is a common scenario when building batch loading pipelines. One example might be if you’re transforming and bringing data into BigQuery from a transactional database each night. If you remember from our post on tables in BigQuery, you can actuallyrun an external query against a Cloud SQL database. This means that we can simply send a query job, through BigQuery’s API, to grab new data from the Cloud SQL table. Below, we’re using the magics command from the google.cloud.bigquery Python library to save the results into a pandas dataframe.
Next, we may need to transform the results. For example, we can use the Google Maps GeoCoding API to get the latitude and longitude coordinates for each customer in our data.
Finally, we can create a load job to add the data, along with the coordinates, into our existing native BigQuery table.
You can access this code in our sample Jupyter Notebook. However, if you were using this in production you may want to leverage something like a Google Cloud Function.
Reservations API
While the “core” of BigQuery is handled through the BigQuery v2 API, there are other APIs to manage tangential aspects of BigQuery. The Reservations API, for example, allows you to programmatically leverage workload management resources like capacity commitments, reservations and assignments as we discussed in a previous post.
Workload management
Let’s imagine that we have an important dashboard loading at 8am on the first Monday of each month. You’ve decided that you want to leverageOriginal Postroducts/data-analytics/introducing-bigquery-flex-slots" target="_blank" rel="noreferrer noopener">flex slotsto ensure that there are enough workers to make the dashboard load super fast for your CEO. So, you decide to write a program that purchases a flex slot commitment, creates a new reservation for loading the dashboard and then assigns the project where the BI tool will run the dashboard to the new reservation. Check out the full sample code here!
Storage API
Another relevant API for working with BigQuery is theStorage API. The Storage API allows you to use BigQuery like a Data Warehouse and a Data Lake. It’s real-time so that you don’t have to wait for your data, it’s fast so that you don’t need to reduce or sample your data, and it’s efficient so that you should only read the data you want. It’s broken down into two components.
- The Read Client exposes a data-stream suitable for reading large volumes of data. It also provides features for parallelizing reads, performing partial projections, filtering data, and offering precise control over snapshot time.
- The Write Client (preview) is the successor to the streaming mechanism found in the BigQuery v2 API. It supports more advanced write patterns such as exactly one semantics. More on this soon!
The Storage API was used to build a series of Hadoop connectors so that you can run your Spark workloads directly on your data in BigQuery. You can also build your own connectors using the Storage API!
Connections API
The BigQuery Connections API is used to create a connection to external storage systems, like Cloud SQL. This enables BigQuery users to issue live, federated, queries against other systems. It also supports BigQuery Omni to define multi-cloud data sources and structures.
Programmatically Managing Federation Connections
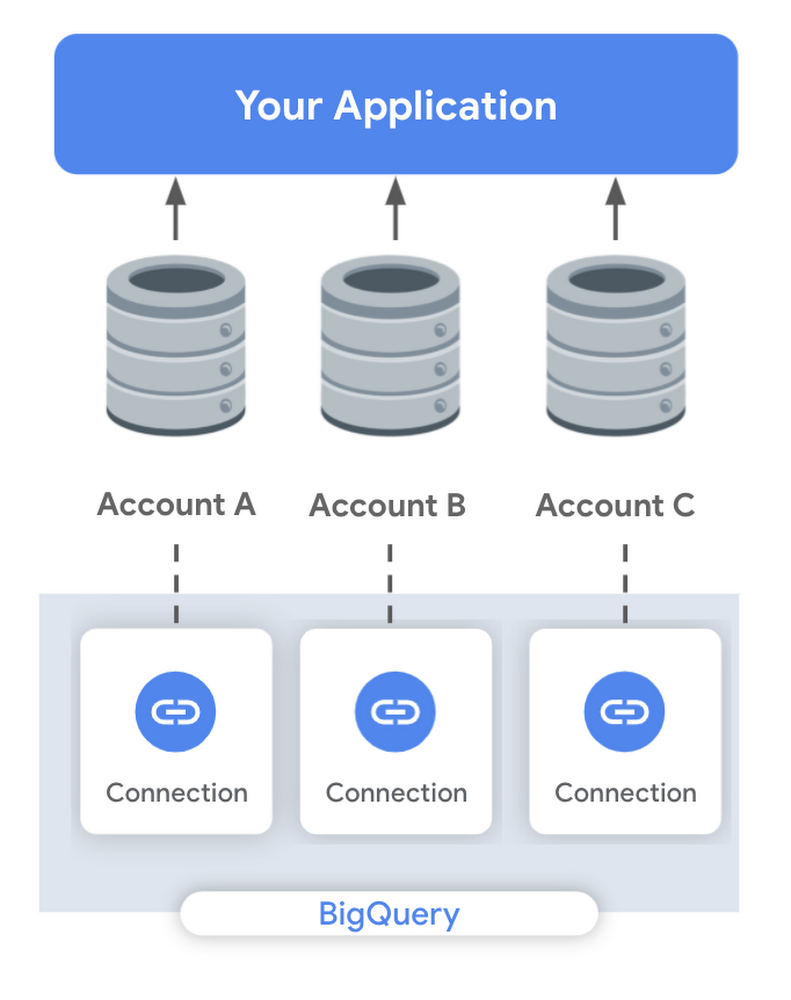
Let’s imagine that you are embedding analytics for your customers. Your web application is structured such that each customer has a single-tenant Cloud SQL instance that houses their data. To perform analytics on top of this information, you may want to create connections to each Cloud SQL database. Instead of manually setting up each connection, one option could be using the Connections API to programmatically create new connections during the customer onboarding process.
Data Transfer Service API
BigQuery data transfer serviceallows you to automate work to ingest data from known data sources, with standard scheduling. DTS offers support for migration workloads, such as specialized integrations that help with synchronizing changes from a legacy, on premise warehouse. Using the API you can do things likecheck credentials, trigger manual runs and get responses from prior transfers.
Data QnA API
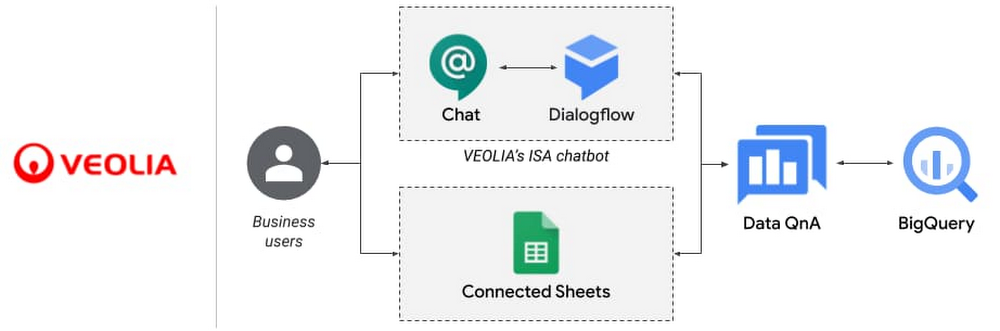
The last API I’ll mention is one of my favorites—Data QnA which is currently in preview. Are business users at your organization always pinging you to query data on their behalf? Well, with the QnA API you can convert natural language text inquiries into SQL – meaning you can build a super powerful chatbot that fulfills those query requests, or even give your business users access to connected sheets so they can ask analytics questions directly in a spreadsheet. Check out this post to learn more about how customers are using this API today!
Wrapping up
Hopefully this post gave you a good idea of how working with the BigQuery APIs can open up new doors for automating data-fueled workflows. Keep in mind that there are lots of more relevant APIs when working with BigQuery, like some of the platforms we discussedlast week in our post on Data Governance– including IAM for managing access policies, DLP for managing sensitive data, andData Catalog for tracking and searching metadata.
Next week is our last post for this season of ourBigQuery Spotlight YouTube series, and we’ll be walking through monitoring use cases. Remember to follow me on LinkedIn and Twitter!
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.