
VPC Flow Logs help you understand network traffic patterns, identify security issues, audit usage, and diagnose network connectivity on AWS. Customers often route their VPC flow logs directly to Amazon Simple Storage Service (Amazon S3) for long-term retention.
You can then use a custom format conversion application to convert these text files into an Apache Parquet format to optimize the analytical processing of the log data and reduce the cost of log storage. This custom format conversion step added complexity, time to insight, and costs to the VPC flow log traffic analytics. Until today, VPC flow logs were delivered to Amazon S3 as raw text files in GZIP format.
Today, we’re excited to announce a new feature that delivers VPC flow logs in the Apache Parquet format, making it easier, faster, and more cost-efficient to analyze your VPC flow logs stored in Amazon S3. You can also deliver VPC flow logs to Amazon S3 with Hive-compatible S3 prefixes partitioned by the hour.
Apache Parquet is an open-source file format that stores data efficiently in columnar format, provides different encoding types, and supports predicate filtering. With good compression ratios and efficient encoding, VPC flow logs stored in Parquet reduce your Amazon S3 storage costs. When querying flow logs persisted in Parquet format with analytic frameworks, non-relevant data is skipped, requiring fewer reads on Amazon S3 and thereby improving query performance. To reduce query running time and cost with Amazon Athena and Amazon Redshift Spectrum, Apache Parquet is often the recommended file format.
In this post, we explore this new feature and how it can help you run performant queries on your flow logs with Athena.
Create flow logs with Parquet file format
To take advantage of this feature, simply create a new VPC flow log subscription with Amazon S3 as the destination using the AWS Management Console, AWS Command Line Interface (AWS CLI), or API. On the console, when creating new a VPC flow log subscription with Amazon S3, you can select one or more of the following options:
- Log file format
- Hive-compatible S3 prefixes
- Partition logs by time
We now explore how each of these options can make processing and storage of flow logs more efficient
Apache Parquet formatted files
By default, your logs are delivered in text format. To change to Parquet, for Log file format, select Parquet. This delivers your VPC flow logs to Amazon S3 in the Apache Parquet format.
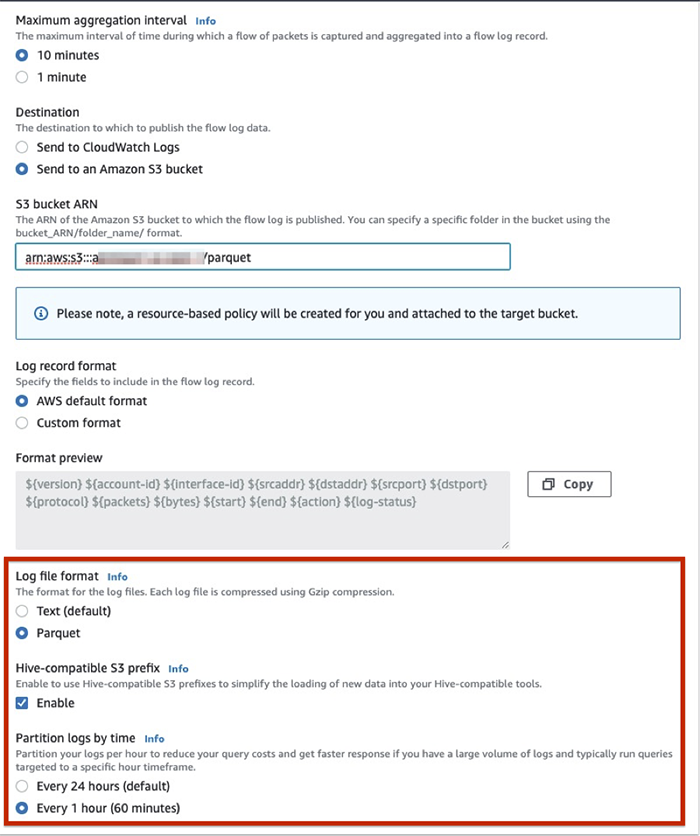
Note the following considerations:
- You can’t change existing flow logs to deliver logs in Parquet format. You need to create a new VPC flow log subscription with Parquet as the log file format.
- Consider using a higher maximum aggregation interval (10 minutes) when aggregating flow packets to ensure larger Parquet files on Amazon S3.
- Refer to Original Postricing/" target="_blank">Amazon CloudWatch pricing for pricing of log delivery in Apache Parquet format for VPC flow logs
Hive-compatible partitions
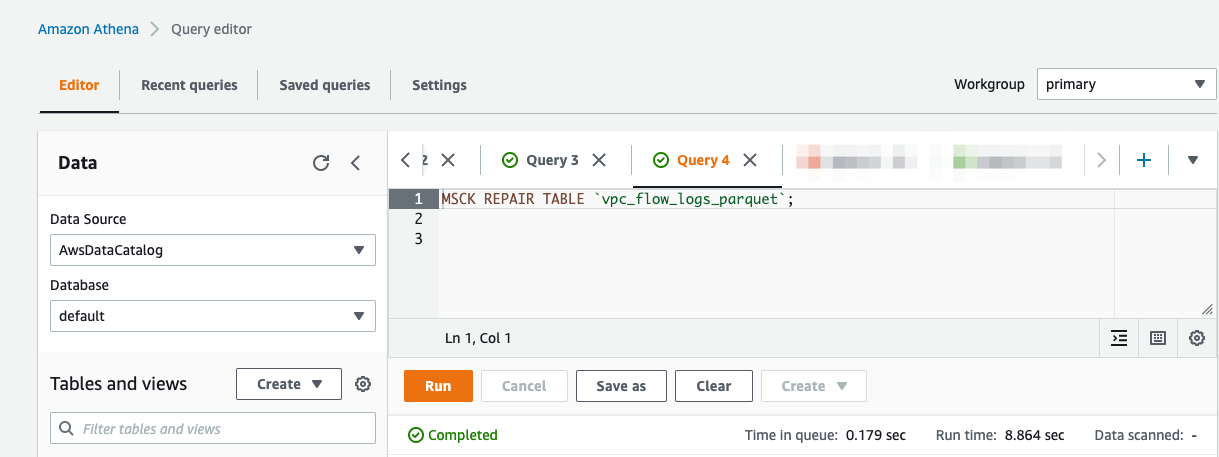
Partitioning is a technique to organize your data to improve the efficiency of your query engine. Partitions aligned with the columns that are frequently used in the query filters can significantly lower your query response time. You can now specify that your flow logs be organized in Hive-compatible format. This allows you to run the MSCK REPAIR command in Athena to quickly and easily add new partitions as they get delivered into Amazon S3. Simply select Enable for Hive-compatible S3 prefix to set this up. This delivers the flow logs to Amazon S3 in the following path:
s3://my-flow-log-bucket/my-custom-flow-logs/AWSLogs/aws-account-id=123456789012/aws-service=vpcflowlogs/aws-region=us-east-1/year=2021/month=10/day=07/123456789012_vpcflowlogs_us-east-1_fl-06a0eeb1087d806aa_20211007T1930Z_d5ab7c14.log.parquetPer-hour partitions
You can also organize your flow logs at a much more granular level by adding per-hour partitions. You should enable this feature if you constantly need to query large volumes of logs with a specific time frame as the predicate. Querying logs only during certain hours results in less data scanned, which translates to lower cost per query with engines such as Athena and Redshift Spectrum.
You can also set per-hour partitions via an API or the AWS CLI using the --destination-options parameter in create-flow-logs:
aws ec2 create-flow-logs \
--resource-type VPC \
--resource-ids vpc-001122333 \
--traffic-type ALL \
--log-destination-type s3 \
--log-destination arn:aws:s3:::my-flow-log-bucket/my-custom-flow-logs/ \
--destination-options FileFormat=parquet,HiveCompatiblePartitions=True, PerHourPartition=TrueThe following is a sample flow log file deposited into an hourly bucket. By default, the flow logs in Parquet are compressed using Gzip format, which has the highest compression ratio compared to other compression formats.
s3://my-flow-log-bucket/my-custom-flow-logs/AWSLogs/aws-account-id=123456789012/aws-service=vpcflowlogs/aws-region=us-east-1/year=2021/month=10/day=07/hour=19/123456789012_vpcflowlogs_us-east-1_fl-06a0eeb1087d806aa_20211007T1930Z_d5ab7c14.log.parquetQuery with Athena
You can use the Athena integration for VPC Flow Logs from the Amazon VPC console to automate the Athena setup and query VPC flow logs in Amazon S3. This integration has now been extended to support these new flow log delivery options to Amazon S3.
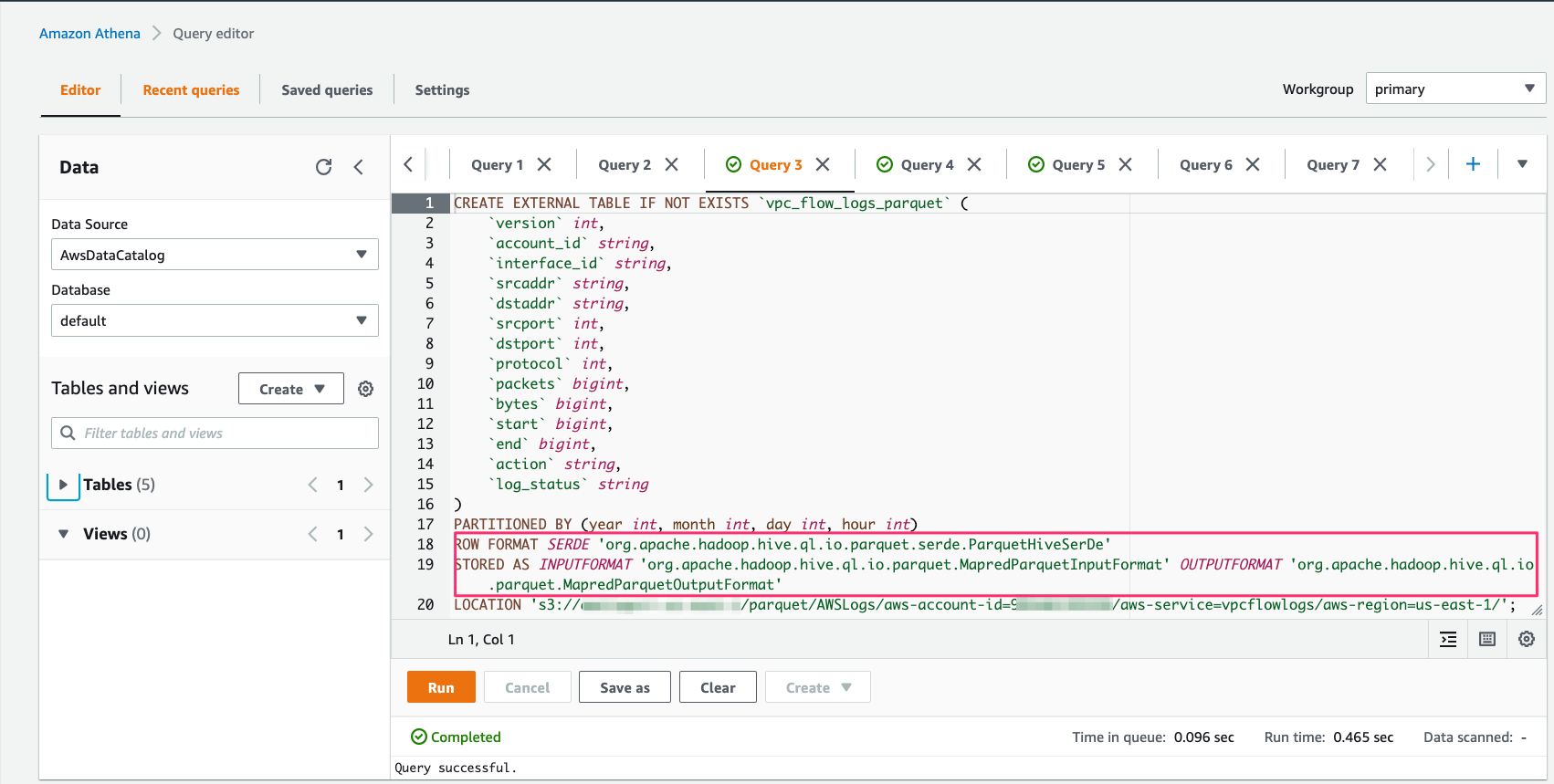
To demonstrate querying flow logs in Parquet and in plain text in this blog, let’s start from the Amazon Athena console. We begin by creating an external table pointing to flow logs in Parquet.
Note that this feature supports specifying flow logs fields in Parquet’s native data types. This eliminates the need for you to cast your fields when querying the traffic logs.
Then run MSCK REPAIR TABLE.
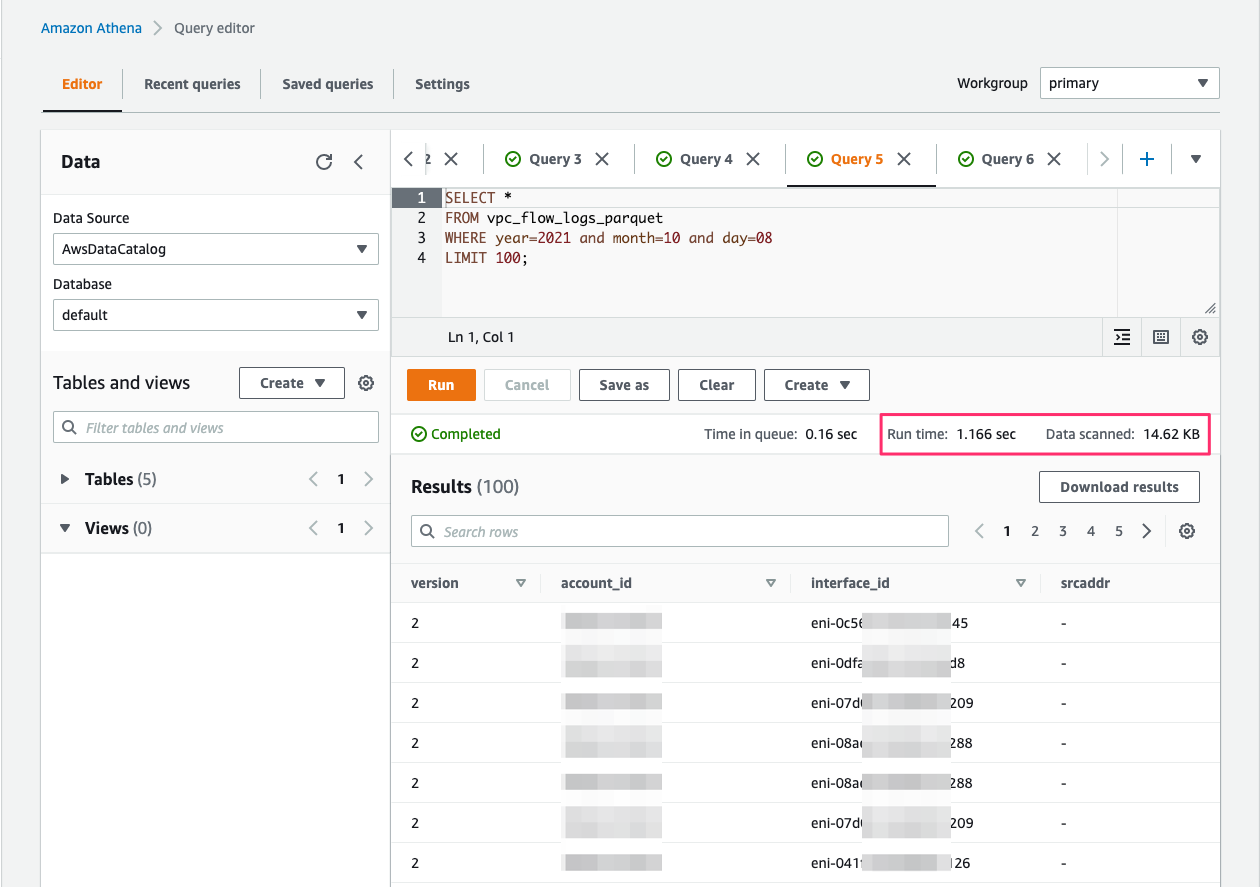
Let’s run a sample query on these Parquet-based flow logs.
Now, let’s create a table for flow logs delivered in plain text.

We add the partitions using the ALTER TABLE statement in Athena.
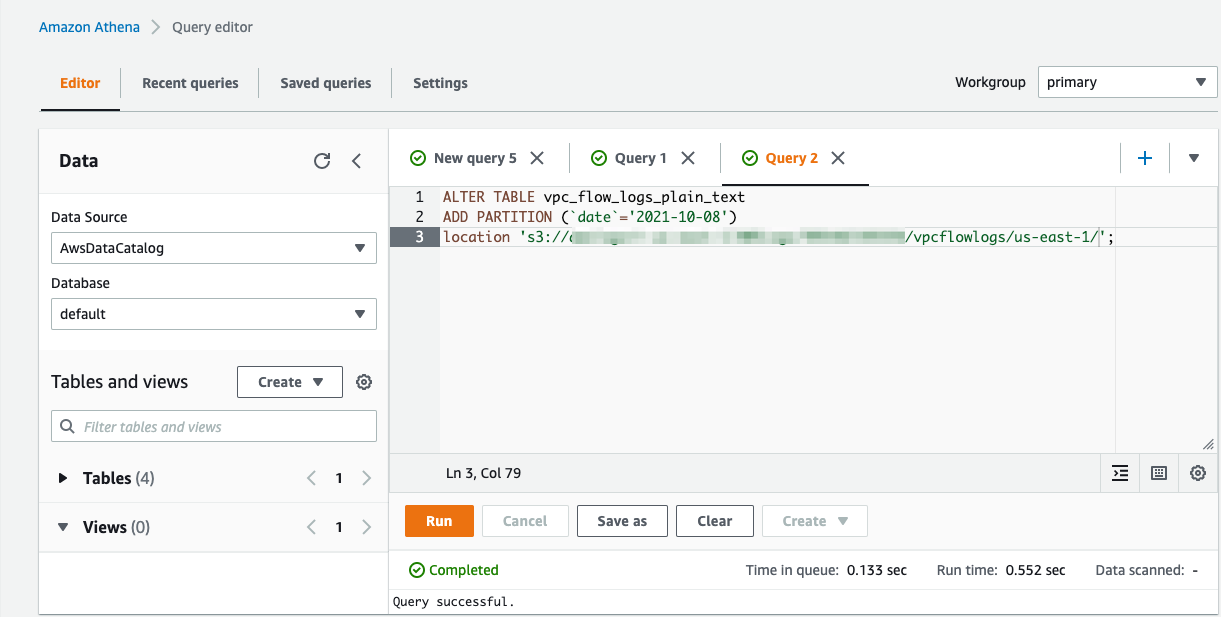
Run a simple flow logs query and note the time it took to run the query.
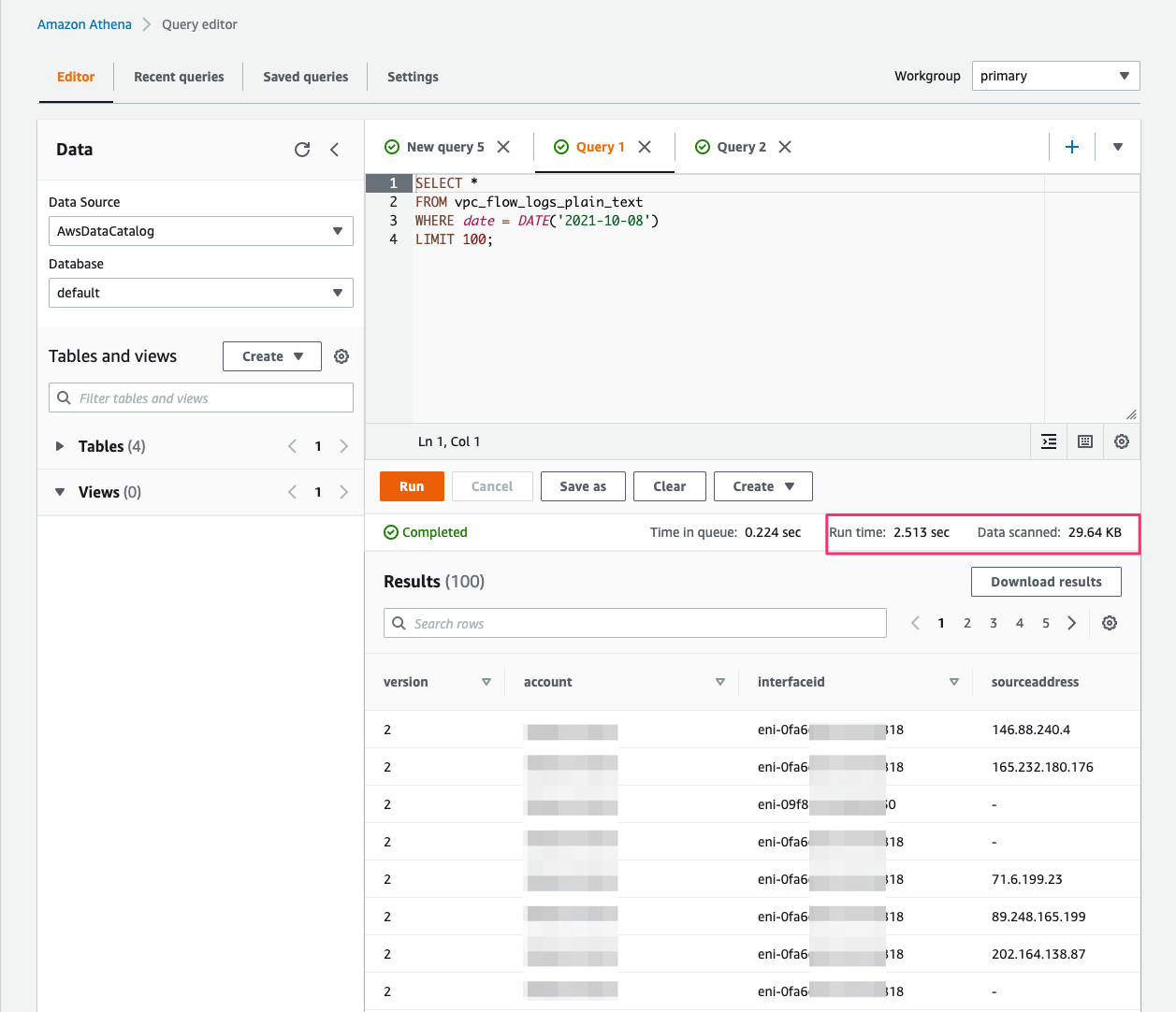
The Athena query run time with flow logs in Parquet (1.16 seconds) is much faster than the run time with flow logs in plain text (2.51 seconds).
For benchmarks that further describe the cost savings and performance improvements from persisting data in Parquet in granular partitions, see Top 10 Performance Tuning Tips for Amazon Athena.
Summary
You can now deliver your VPC flow logs to Amazon S3 with three new options:
- In Apache Parquet formatted files
- With Hive-compatible S3 prefixes
- In hourly partitioned files
These delivery options make it faster, easier, and more cost-efficient to store and run analytics on your VPC flow logs. To learn more, visit VPC Flow Logs documentation. We hope you will give this feature a try and share your experience with us. Please send feedback to the AWS forum for Amazon VPC or through your usual AWS support contacts.
About the Authors
Radhika Ravirala is a Principal Streaming Architect at Amazon Web Services, where she helps customers craft distributed streaming applications using Amazon Kinesis and Amazon MSK. In her free time, she enjoys long walks with her dog, playing board games, and reading widely.
Vaibhav Katkade is a Senior Product Manager in the Amazon VPC team. He is interested in areas of network security and cloud networking operations. Outside of work, he enjoys cooking and the outdoors.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.