You can take advantage of
‘s unused capacity at a significant cost savings by using Spot virtual machines (VM) and scale sets. However, at any point in time when Azure needs the capacity back, the Azure infrastructure will evict Azure Spot VMs. Therefore, This means that Azure Spot VMs should only be used for workloads that can handle interruptions like delayable batch or queue processing jobs, non-critical dev/test environments, and large, delayable compute workloads.
Azure Spot VM and scale sets do not have an SLA once created, which means that they can be terminated at any moment with up to 30 seconds of notice. Whenever Azure needs the capacity back, the Azure infrastructure will send your compute instance an eviction notice and proceed to evict that same instance based on your configured eviction policy.
This guide is meant to walk you through Azure Spot Eviction fundamentals and help you design a solution to support workload interruptions.
Cost optimization
Azure provisions its spare capacity along all its offered regions so it can respond on demand when new resources are created. While that capacity remains idle, you have an opportunity to deploy VMs in your subscription at discount prices and capped at pay-as-you-go prices using Azure Spot VMs and virtual machine scale sets.
Keeping operational expenses under control is common practice when running solutions on the cloud and the cost optimizations pillar from the Well Architected Framework can help you find the right strategy for your architecture.
We recommend that you use the Retail Rates Prices API to get retail prices for all Azure services. You will want to get familiar with this pricing API, because it will be another input parameter to consider along with eviction rates based on location and SKUs.
For more details on how to plan with costs in mind, see step 2 in the Planning section of our implementation process.
Purpose
While the number one reason to choose Azure Spot is the significant cost savings at the infrastructure level, keep in mind that you need to build reliable interruptible workloads that can run on top of this Azure managed service.
The goal is to design a workload that is fault tolerant and resilient, so that it’s capable of being unexpectedly and reliably interrupted. Successful designs have workloads that are able to deal with high levels of uncertainty at the time of being deployed and can recover after being forcedly shut down. Even better, they can gracefully shut down with under 30 seconds of notice prior to eviction.
Technology choice
Avoid using Azure Spot if:
- Your application is under a strict SLA that could be compromised by compute interruptions
- You’re planning to provision sticky session solutions
- Your workload isn’t specifically designed and tested to be interrupted
- Your workload is stateful by nature
If you find that Azure Spot is not the right service for you, go to Choose an Azure compute service for further assistance.
Some good candidates to run on top of Azure Spot VMs are:
- Batch processing applications
- Workloads that aren’t time critical for background processing jobs
- Large workloads that aren’t required to finish in a certain period of time (ex. data analytics)
- Tasks that are optional or have lower priority (ex. spawning a CI/CD agent for a dev/test environment)
- Short lived jobs that can lose their progress repeatedly without having an effect on the end result
Azure Virtual Machine Scale Sets are also offered with priority Spot and is an underlying service that will represent nodes for an Azure Kubernetes Service (AKS) cluster. As a result, stateless applications and opportunistic scale-out scenarios are possible candidates to build with Azure Spot virtual machine scale sets in mind if they’re meant to run from an AKS cluster.
Considerations
Azure Spot VM and scale sets are compute infrastructure as a service (IaaS) available in Azure that serves without an SLA once created. This means that it can be terminated at any moment with up to 30 seconds of notice. In other words, at any point in time when Azure needs the capacity back, the Azure infrastructure will evict the service by deallocating or deleting the resources based on your configured eviction policy.
You’re acquiring unused (if any) ephemeral compute capacity that offers no high availability guarantees. Given that, Azure Spot VM and scale sets are a limited resource that won’t always be at your disposal and you should event prepare to overcome a potential scenario in which a VM is evicted right after being created.
Deployment strategies
We recommend that any production workloads keep a guaranteed number of Azure VM instances with regular priority in addition to VMs with spot priority. This way you can optimize your costs and remain in compliance with your application SLA. If your workload is capable of being consistently interrupted and it doesn’t need an SLA, you might consider going full spot priority even in production. The following are some strategies to consider:
- The Priority Swap strategy consist of running Spot VMs initially. If after a considerable or safe amount of time you can’t complete a job because it gets interrupted, then you would swap over to using regular VMs. An example of a good candidate for this type of strategy would be running automated tests (CI).
- The Priority Balanced strategy is good for getting a mix of regular and Spot VMs initially based on your workload requirements. There is a chance under extreme circumstances that you might never get an Azure Spot VM at all.
Caution
At a macro level in production, it is especially important for you to anticipate and plan for evictions as they will greatly impact your performance. For example, if you have 100 Spot VMs allocated and you lose 10% of your capacity on compute as a result of an eviction, that is going to noticeably impact the overall throughput of your application.
Spot VM states
When architecting interruptible workloads, it’s important to understand the characteristics of the application platform you are running on. Azure Spot VM and scale sets instances will transition states and your workload must be able to behave accordingly. Considering these states and their transitions can help in the designing of your system. The diagram below visualizes the following states:
- Stopped or Deleted (eviction policy based)
- Running (based on capacity and max price you set)
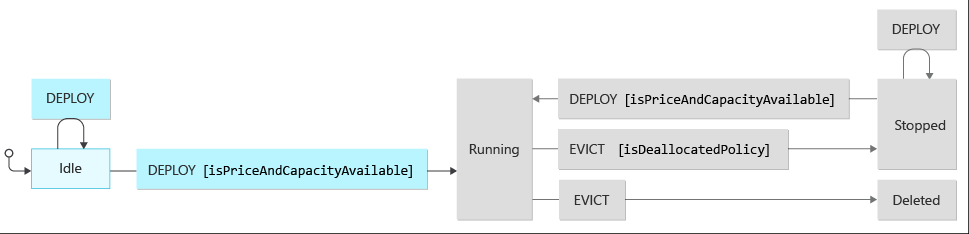
The following table breaks down the expected outcome and state for a Spot VM based on the VMs current state, the input it receives from the Azure infrastructure, and the conditions you set (price limits and eviction policy).
| Current State | Input | Conditions | Next State | Output |
|---|---|---|---|---|
| * | Deploy | Max Price >= Current Price and Capacity = Available | Running | You pay the Max Price you set and underlying disks |
| Running | Evict | Max Price = -1 and Capacity = Available | Running | You pay the VM Price and underlying disks |
| Running | Evict | Capacity = Unavailable and Policy = Deallocate | Stopped | Compute capacity gets deallocated while you pay for underlying disk. It’s possible to restart the machine |
| Running | Evict | Capacity = Unavailable and Policy = Delete | Deleted | You’re not charged at this point since disks are deleted |
| Running | Evict | Max Price < Current Price and Policy = Deallocate | Stopped | You pay for underlying disk and can restart the machine |
| Running | Evict | Max Price < Current Price and Policy = Delete | Delete | You’re not charged at this point since disks are deleted |
| Stopped | Restart | Max Price < Current Price and Policy = Deallocate | Stopped | You pay for underlying disk and can restart the machine |
| Stopped | Restart | Max Price < Current Price and Policy = Delete | Delete | You’re not charged at this point since disks are deleted |
| Stopped | Restart | Max Price >= Current Price and Capacity = Available | Running | You pay the Max Price you set and underlying disks |
Important
If a constraint capacity event occurs at a particular location and/or the current market price surpass the Max Price you set, the Azure infrastructure will collect its compute capacity for the Azure Spot VM according to your configured Eviction Policy. If you configured your Azure Spot VM for deallocation under an eviction event, it’s the application operator’s responsibility to automatically or manually restart the Azure Spot VM once the capacity becomes available.
Concepts
There are several important considerations when architecting solutions on top of Azure Spot VM instances.
Subscription limits
The number of cores in a subscription are variable, depending on the subscription type and other considerations. Some subscription types aren’t supported. Refer to Azure subscription and service limits, quotas, and constraints for more information.
Eviction
There are several conditions that affect an eviction. When architecting solutions to maximize cost optimization by using spot, having an understanding of what factors you’ll be facing that cause interruption are important. The following list goes into detail on every element you should consider.
- Rate – The rate is nothing more but the chances of being evicted at a specific location, based on historical trends. The eviction rates are available by SKU to help in compute sizing choices. To help with the selection process, query the pricing history view in the Azure portal in addition to Azure Spot advisor.
- Type – You can choose between Max Price or Capacity or Capacity Only.
- Capacity – If the Azure infrastructure evicted and took back capacity, this configuration looks for spare capacity. If space capacity is located, the configuration will attempt to redeploy your deallocated instances on top of them. This configuration provides your Azure Spot virtual machines with better chances of surviving next time an eviction event kicks in.
Your architecture is most likely to thrive with this type when you have built in intentional flexibility in VM SKU, operating region, and calendar/time. Meaning your architecture and ops processes are explicitly designed with the intent that you will need to likely switch VM SKUs, regions, and/or pick up work at a later date/time. Designing that flexibility into your architecture for this type of workload is recommended.
- VM Configuration: Design your architecture to run on a wide array of SKUs. If you can be flexible on VM SKU, the better are chances are to allocate Azure Spot VM and scale sets instances. Some SKU(s) like B-series or Promo versions of any size aren’t supported.
- Location: Design your architecture to be region agnostic, or at least not significantly region-limited. If your workload can run from any region in a large pool of regions, it improves the chances that you’ll find a region with spare capacity with fewer chances of being deallocated. Take into account that
Microsoft Azure
China 21Vianet isn’t supported.
- Time of the day, weekends, seasons, and other time-based considerations are important factors when making a final decision between Azure Spot over regular VMs and scale sets. Time-based constraints in your workload, like it must be up during business hours, are indicative of a workload that might not be a good fit for spot. Build time-based flexibility into your workload.
- Current VM Price vs Max Price (you set): if you’re willing to pay up to the Pay as you go rate, it’s possible to prevent being evicted based on pricing reasons by setting the Max Price to
-1, which is known as Eviction Type Capacity Only. If pricing is a constraint for your business organization goals, Eviction Type Max Price or Capacity Only is recommended instead, and in this case you can adjust the right Max Price at any moment by taking into account that changing this value requires to deallocate the VM or scale set first to take effect. If you choose the latter, it’s a good idea to analyze the price history, and Eviction Rate for the regions you’re targeting.
Note
If you have chosen a Max Price and Capacity eviction type, it is good practice to regularly use the Azure Retail Prices API to check whether the Max Price you set is doing well against Current Price. Consider scheduling this query and respond with Max Price changes as well as gracefully deallocating the Virtual Machine as needed.
- Capacity – If the Azure infrastructure evicted and took back capacity, this configuration looks for spare capacity. If space capacity is located, the configuration will attempt to redeploy your deallocated instances on top of them. This configuration provides your Azure Spot virtual machines with better chances of surviving next time an eviction event kicks in.
- Policy – The Policy configuration is an important consideration during eviction events. We recommend to choose the Deallocate policy if you are planning to start the same machine, provided your workload can wait for Azure to release capacity within the same location and SKU. Alternatively, we recommend the Delete policy to reduce costs, since you would be re-deploying your entire Spot infrastructure on demand, ideally changing location and/or SKU for more flexibility.
This decision will impact your ops process around the workload. The more flexible you can be about workload portability, such as creating new deployments in available regions or SKUs while prior workload instances are interrupted, the more likely it will be you’ll find a place to run. This is more important on processes that have some time-boundness to them. If you can wait until capacity becomes available, you’ll have less of a monitoring/ops process to try to “rehome” your workloads. The amount you invest in workload portability to chase available compute should be perorational to the importance that workload proceeds as if it wasn’t interrupted.
- Delete
- You free up the Cores from your Subscription
- You’re no longer charged for the disk as they get deleted along with the Azure Spot VM
- Shared subscriptions or multiple workloads using Azure Spot VM instances can benefit from this policy
- Workloads that have a designed process to be moved between SKU and/or Region are ideal for this policy.
- Deallocate
- Change VM state to the stopped-deallocated state
- Allows you to redeploy it later
- You’re still being charge for the underlying disks
- It consumes Cores quota from your Subscription
- Workloads that are not under any time constraints or subscription quota pressure can benefit from this policy as it potentially makes resuming your workload more straightforward.
- Delete
- Simulation – It’s possible to simulate an eviction event when Azure needs the capacity back. We recommend you become familiar with this concept so that you can simulate interruptions from dev/test environments to guarantee your workload is fully interruptible before deploying to production.
Events
Azure Scheduled Events is a metadata service in Azure that signal about forthcoming events associated to the Virtual Machine resource type. The general recommendation when using Virtual Machines is to routinely query this endpoint to discover when maintenance will occur, so you’re given the opportunity to prepare for disruption. One of the platform event types being scheduled that you’ll want to notice is Preempt as this signals the imminent eviction of your spot instance. This event is scheduled with a maximum amount of time of 30 seconds in the future. Given that, you must assume that you’re going to have less than that amount of time to limit the impact to your running workload. The recommended practice here is to check this endpoint based on the periodicity your workload mandates (such as every 10 seconds) to attempt having a graceful interruption.
The workload
One common workload type for Azure Spot VMs is queue processing applications. The reference implementation guide contains a simple, asynchronous queue-processing worker (C#, .NET) implemented in combination with Azure Queue Storage. This implementation demonstrates how to query the Azure Scheduled Events REST endpoint, as mentioned above.
Planning for workload interruption
Application states
When architecting reliable and interruptible workloads, you’ll want to focus on four main stages during the workload’s lifecycle. These stages will translate into changes of states within your application.
- Start: After the application warmup state is completed, you could consider internally transitioning into the processing state. One important thing to consider is if there was a forced shutdown previously, then there might be some incomplete processing and we recommend that you implement idempotency as applicable. Additionally, it’s good practice to save the context by creating checkpoints regularly. Doing so will create a more efficient recovery strategy, which is to recover from the latest well-known checkpoint instead of starting all over on processing.
- Shutdown: Your application is in the processing state and at the same time an eviction event is triggered by the Azure infrastructure. Compute capacity must be collected from Azure Spot instances, and as a result, an eviction notice will take place in your VM instance, which your application was actively monitoring for. At this time, your application will change its state to evicted and implement the logic you’ve programmed that responds to the eviction notice. It will gracefully shut down in under 30 seconds (best to target 10 or less seconds) by releasing resources such as draining connections and event log flushing, or it will prepare to be forcedly deallocated or deleted based on your Eviction Policy. In the latter configuration, as a general rule, you can’t persist any progress or data on the file system, because disks are being removed along with the Azure VM.
- Recover: In this stage, your workload is redeployed or recreated depending on your Eviction Policy. During recovery, these possible states are detected based on your scenario. You can implement the logic to deal with a prior forced shutdown, so your application is able to recover from a previous backup or checkpoint if necessary.
- Resume: The application is about to continue processing after a best effort to recover the context prior to eviction. It’s a good idea to transition into a warmup state to ensure the workload is healthy and ready to start.
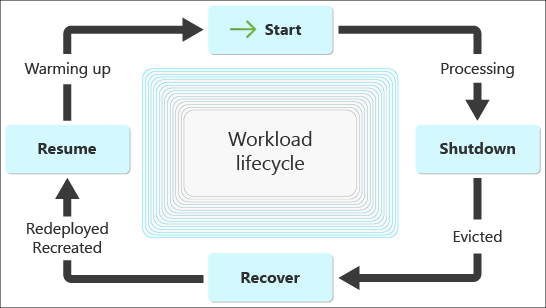
Note
The aforementioned states are just a reduced list of possible conditions for a reliable interruptible workload. You might find other states that are convenient for modeling the lifecycle of your own workloads.
System states
The implementation uses a Distributed Producer Consumer system type, where the interruptible workload represents a batch processing application acting as the consumer. Since you’d mainly consider Azure Spot VMs for cost optimization, we recommend looking into the issues that can arise with this kind of solution and architect mitigations to avoid wasting excess compute cycles. One class of examples would be concurrency problems.
- Deadlock
- Starvation, by evaluating which scheduling system you’re using and avoiding a solution would lead to starvation. For example, a fixed-priority preemptive scheduling system isn’t advised for max priority queues that are never expected to be emptied.
In general, we recommend that you always take edge cases and common pitfalls associated to the system types you’re building into account. Design their architectures to maximize the system type’s expected behavior will benefit while running on top of Azure Spot VMs.
Note
The reference implementation follows the simple concurrency strategy: do nothing. Since you’re going to deploy a single interruptible workload instance (consumer) and produce a moderate and discrete number of messages, there would be no expectations of a deadlock or starvation as a system state. One recommendation to prevent your system from running into such states is to consider handling them if detected at the time of workload orchestration.
Orchestration
Orchestration in this context is about workload recovery after eviction. Your choice of delete or deallocate will influence how you architect your solution to “resume operations” after your instance(s) have been evicted. If your workload was designed around delete you’ll need a process to monitor for evictions external to the application and initiative remediation by deploying to alternative regions or SKUs. If your workload was designed around deallocate then you’ll need a mechanism to be made aware of when your compute instance can come back online.
Either way, the end goal is the same. The interruptible workload begins executing on an Azure Spot VM at startup time.
It will be helpful to kick off the application after eviction or the first time the Azure Spot VM gets deployed. This way, the application will be able to continue processing messages without human intervention from the queue once started. Once the application is running, it will transition through the Recover, Resume, and Start application stages.
By design, the orchestration could have more or less responsibilities like running after the machine has started up, downloading the workload package from an Azure Storage Account, decompressing files, executing the process, coordinating how many instances are going to be running in parallel, system recovery, and more.
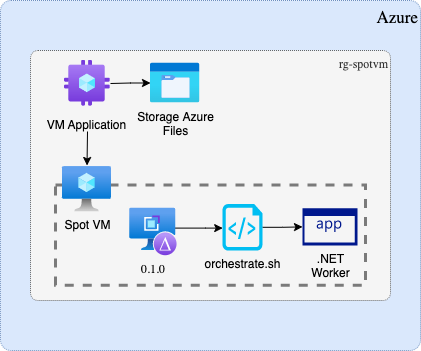
Consider using VM Applications to package and distribute your interruptible workloads as part of your orchestration process. This mechanism allows for VMs to be defined, declaratively, with the specific workload in mind. Using VM Applications can simplify your pipelines and provide a helpful separation of concerns between the management of Spot VM instances and the instantiation of the workload on those instances. The implementation in GitHub demonstrates this.
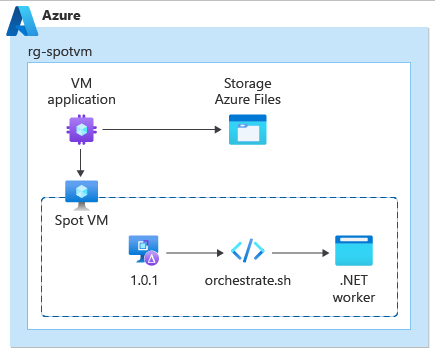
Another important orchestration related aspect to understand is how to scale your workload within a single VM instance, so it’s using its resources efficiently. Many workloads will span multiple VMs, but this guidance is still applicable to each VM within that system.
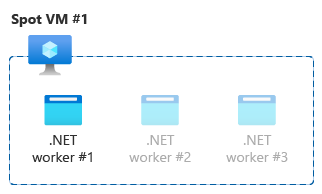
- Scale up strategy
If your workload is built with no artificial constraints and it will grow to consume available resources in your VM instance without exhausting them. You’ll want to ensure that it’s running a singleton of the workload and let it organically request resources as designed. If you design your application to consume all available resources, this will give you compute SKU flexibility to include smaller or larger SKUs in your application. You may find running mixed SKUs in your solution common.
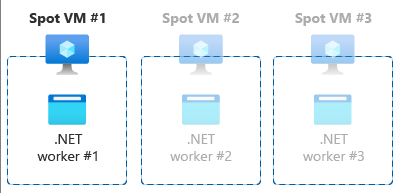
- Scale out strategy
Alternatively, if the workload resources specs are limited by design and it can’t grow to consume VM resources, ensure your VM is the right size to orchestrate multiple whole instances of your workload. Doing so will ensure there’s no wasted over-provisioning of compute resources in your Spot VM. This will impact your workload orchestration strategy.
Deploy this solution
 An implementation of this guidance is available on GitHub: Interruptible workloads on Azure Spot VM/VMSS instances. You can use that implementation to explore the topics addressed above in this article.
An implementation of this guidance is available on GitHub: Interruptible workloads on Azure Spot VM/VMSS instances. You can use that implementation to explore the topics addressed above in this article.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.