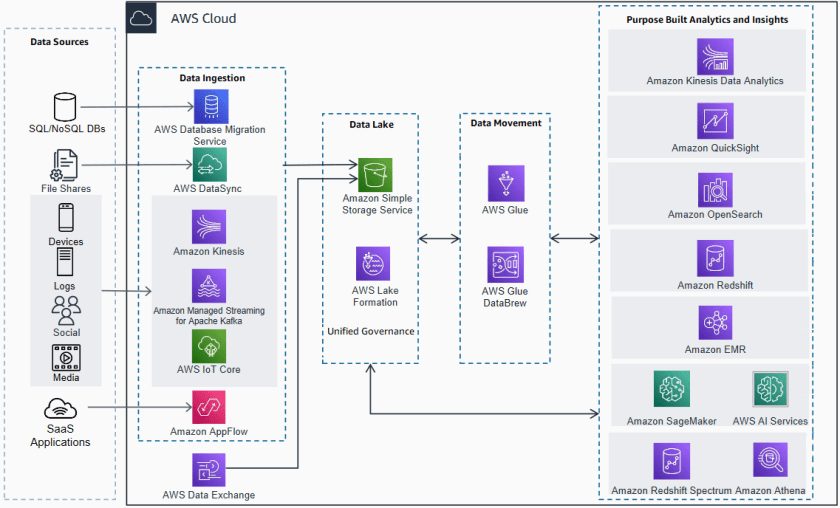
The modern data architecture on AWS focuses on integrating a data lake and purpose-built data services to efficiently build analytics workloads, which provide speed and agility at scale. Using the right service for the right purpose not only provides performance gains, but facilitates the right utilization of resources. Review Modern Data Analytics Reference Architecture on AWS, see Figure 1.
In this series of two blog posts, we will cover guidance from the Sustainability Pillar of the AWS Well-Architected Framework on optimizing your modern data architecture for sustainability. Sustainability in the cloud is an ongoing effort focused primarily on energy reduction and efficiency across all components of a workload. This will achieve the maximum benefit from the resources provisioned and minimize the total resources required.
Modern data architecture includes five pillars or capabilities: 1) data ingestion, 2) data lake, 3) unified data governance, 4) data movement, and 5) purpose-built analytics. In the first part of this blog series, we will focus on the data ingestion and data lake pillars of modern data architecture. We’ll discuss tips and best practices that can help you minimize resources and improve utilization.
Figure 1. Modern Data Analytics Reference Architecture on AWS
1. Data ingestion
The data ingestion process in modern data architecture can be broadly divided into two main categories: batch, and real-time ingestion modes.
To improve the data ingestion process, see the following best practices:
Avoid unnecessary data ingestion
Work backwards from your business needs and establish the right datasets you’ll need. Evaluate if you can avoid ingesting data from source systems by using existing publicly available datasets in AWS Data Exchange or Open Data on AWS. Using these cleaned and curated datasets will help you to avoid duplicating the compute and storage resources needed to ingest this data.
Reduce the size of data before ingestion
When you design your data ingestion pipelines, use strategies such as compression, filtering, and aggregation to reduce the size of ingested data. This will permit smaller data sizes to be transferred over network and stored in the data lake.
To extract and ingest data from data sources such as databases, use change data capture (CDC) or date range strategies instead of full-extract ingestion. Use AWS Database Migration Service (DMS) transformation rules to selectively include and exclude the tables (from schema) and columns (from wide tables, for example) for ingestion.
Consider event-driven serverless data ingestion
Adopt an event-driven serverless architecture for your data ingestion so it only provisions resources when work needs to be done. For example, when you use AWS Glue jobs and AWS Step Functions for data ingestion and pre-processing, you pass the responsibility and work of infrastructure optimization to AWS.
2. Data lake
Amazon Simple Storage Service (S3) is an object storage service which customers use to store any type of data for different use cases as a foundation for a data lake. To optimize data lakes on Amazon S3, follow these best practices:
Understand data characteristics
Understand the characteristics, requirements, and access patterns of your workload data in order to optimally choose the right storage tier. You can classify your data into categories shown in Figure 2, based on their key characteristics.
Figure 2. Data Characteristics
Adopt sustainable storage options
Based on your workload data characteristics, use the appropriate storage tier to reduce the environmental impact of your workload, as shown in Figure 3.
Figure 3. Storage tiering on Amazon S3
Implement data lifecycle policies aligned with your sustainability goals
Based on your data classification information, you can move data to more energy-efficient storage or safely delete it. Manage the lifecycle of all your data automatically using Amazon S3 Lifecycle policies.
Amazon S3 Storage Lens delivers visibility into storage usage, activity trends, and even makes recommendations for improvements. This information can be used to lower the environmental impact of storing information on S3.
Select efficient file formats and compression algorithms
Use efficient file formats such as Parquet, where a columnar format provides opportunities for flexible compression options and encoding schemes. Parquet also enables more efficient aggregation queries, as you can skip over the non-relevant data. Using an efficient way of storage and accessing data is translated into higher performance with fewer resources.
Compress your data to reduce the storage size. Remember, you will need to trade off compression level (storage saved on disk) against the compute effort required to compress and decompress. Choosing the right compression algorithm can be beneficial as well. For instance, ZStandard (zstd) provides a better compression ratio compared with LZ4 or GZip.
Use data partitioning and bucketing
Partitioning and bucketing divides your data and keeps related data together. This can help reduce the amount of data scanned per query, which means less compute resources needed to service the workload.
Track and assess the improvement for environmental sustainability
The best way for customers to evaluate success in optimizing their workloads for sustainability is to use proxy measures and unit of work KPIs. For storage, this is GB per transaction, and for compute, it would be vCPU minutes per transaction. To use proxy measures to optimize workloads for energy efficiency, read Sustainability Well-Architected Lab on Turning the Cost and Usage Report into Efficiency Reports.
In Table 1, we have listed certain metrics to use as a proxy metric to measure specific improvements. These fall under each pillar of modern data architecture covered in this post. This is not an exhaustive list, you could use numerous other metrics to spot inefficiencies. Remember, just tracking one metric may not explain the impact on sustainability. Use an analytical exercise of combining the metric with data, type of attributes, type of workload, and other characteristics.
| Pillar | Metrics |
|---|---|
| Data ingestion |
|
| Data lake |
|
Table 1. Metrics for the Modern data architecture pillars
Conclusion
In this post, we have provided guidance and best practices to help reduce the environmental impact of the data ingestion and data lake pillars of modern data architecture.
In the next post, we will cover best practices for sustainability for the unified governance, data movement, and purpose-built analytics and insights pillars.
Further reading:
- To learn more, check out the Sustainability Pillar of the AWS Well-Architected Framework and other blog posts on architecting for sustainability.
- For more architecture content, refer to AWS Architecture Center for reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.