This is a guest post co-authored by Mahesh Vandi Chalil, Chief Technology Officer of BookMyShow.
BookMyShow (BMS), a leading entertainment company in India, provides an online ticketing platform for movies, plays, concerts, and sporting events. Selling up to 200 million tickets on an annual run rate basis (pre-COVID) to customers in India, Sri Lanka, Singapore, Indonesia, and the Middle East, BookMyShow also offers an online media streaming service and end-to-end management for virtual and on-ground entertainment experiences across all genres.
The pandemic gave BMS the opportunity to migrate and modernize our 15-year-old analytics solution to a modern data architecture on AWS. This architecture is modern, secure, governed, and cost-optimized architecture, with the ability to scale to petabytes. BMS migrated and modernized from on-premises and other cloud platforms to AWS in just four months. This project was run in parallel with our application migration project and achieved 90% cost savings in storage and 80% cost savings in analytics spend.
The BMS analytics platform caters to business needs for sales and marketing, finance, and business partners (e.g., cinemas and event owners), and provides application functionality for audience, personalization, pricing, and data science teams. The prior analytics solution had multiple copies of data, for a total of over 40 TB, with approximately 80 TB of data in other cloud storage. Data was stored on‑premises and in the cloud in various data stores. Growing organically, the teams had the freedom to choose their technology stack for individual projects, which led to the proliferation of various tools, technology, and practices. Individual teams for personalization, audience, data engineering, data science, and analytics used a variety of products for ingestion, data processing, and visualization.
This post discusses BMS’s migration and modernization journey, and how BMS, AWS, and AWS Partner Minfy Technologies team worked together to successfully complete the migration in four months and saving costs. The migration tenets using the AWS modern data architecture made the project a huge success.
Challenges in the prior analytics platform
- Varied Technology: Multiple teams used various products, languages, and versions of software.
- Larger Migration Project: Because the analytics modernization was a parallel project with application migration, planning was crucial in order to consider the changes in core applications and project timelines.
- Resources: Experienced resource churn from the application migration project, and had very little documentation of current systems.
- Data : Had multiple copies of data and no single source of truth; each data store provided a view for the business unit.
- Ingestion Pipelines: Complex data pipelines moved data across various data stores at varied frequencies. We had multiple approaches in place to ingest data to Cloudera, via over 100 Kafka consumers from transaction systems and MQTT(Message Queue Telemetry Transport messaging protocol) for clickstreams, stored procedures, and Spark jobs. We had approximately 100 jobs for data ingestion across Spark, Alteryx, Beam, NiFi, and more.
- Hadoop Clusters: Large dedicated hardware on which the Hadoop clusters were configured incurring fixed costs. On-premises Cloudera setup catered to most of the data engineering, audience, and personalization batch processing workloads. Teams had their implementation of HBase and Hive for our audience and personalization applications.
- Data warehouse: The data engineering team used TiDB as their on-premises data warehouse. However, each consumer team had their own perspective of data needed for analysis. As this siloed architecture evolved, it resulted in expensive storage and operational costs to maintain these separate environments.
- Analytics Database: The analytics team used data sourced from other transactional systems and denormalized data. The team had their own extract, transform, and load (ETL) pipeline, using Alteryx with a visualization tool.
Migration tenets followed which led to project success:
- Prioritize by business functionality.
- Apply best practices when building a modern data architecture from Day 1.
- Move only required data, canonicalize the data, and store it in the most optimal format in the target. Remove data redundancy as much possible. Mark scope for optimization for the future when changes are intrusive.
- Build the data architecture while keeping data formats, volumes, governance, and security in mind.
- Simplify ELT and processing jobs by categorizing the jobs as rehosted, rewritten, and retired. Finalize canonical data format, transformation, enrichment, compression, and storage format as Parquet.
- Rehost machine learning (ML) jobs that were critical for business.
- Work backward to achieve our goals, and clear roadblocks and alter decisions to move forward.
- Use serverless options as a first option and pay per use. Assess the cost and effort for rearchitecting to select the right approach. Execute a proof of concept to validate this for each component and service.
Strategies applied to succeed in this migration:
- Team – We created a unified team with people from data engineering, analytics, and data science as part of the analytics migration project. Site reliability engineering (SRE) and application teams were involved when critical decisions were needed regarding data or timeline for alignment. The analytics, data engineering, and data science teams spent considerable time planning, understanding the code, and iteratively looking at the existing data sources, data pipelines, and processing jobs. AWS team with partner team from Minfy Technologies helped BMS arrive at a migration plan after a proof of concept for each of the components in data ingestion, data processing, data warehouse, ML, and analytics dashboards.
- Workshops – The AWS team conducted a series of workshops and immersion days, and coached the BMS team on the technology and best practices to deploy the analytics services. The AWS team helped BMS explore the configuration and benefits of the migration approach for each scenario (data migration, data pipeline, data processing, visualization, and machine learning) via proof-of-concepts (POCs). The team captured the changes required in the existing code for migration. BMS team also got acquainted with the following AWS services:
- Proof of concept – The BMS team, with help from the partner and AWS team, implemented multiple proofs of concept to validate the migration approach:
- Performed batch processing of Spark jobs in Amazon EMR, in which we checked the runtime, required code changes, and cost.
- Ran clickstream analysis jobs in Amazon EMR, testing the end-to-end pipeline. Team conducted proofs of concept on AWS IoT Core for MQTT protocol and streaming to Amazon S3.
- Migrated ML models to Amazon SageMaker and orchestrated with Amazon MWAA.
- Created sample QuickSight reports and dashboards, in which features and time to build were assessed.
- Configured for key scenarios for Amazon Redshift, in which time for loading data, query performance, and cost were assessed.
- Effort vs. cost analysis – Team performed the following assessments:
- Compared the ingestion pipelines, the difference in data structure in each store, the basis of the current business need for the data source, the activity for preprocessing the data before migration, data migration to Amazon S3, and change data capture (CDC) from the migrated applications in AWS.
- Assessed the effort to migrate approximately 200 jobs, determined which jobs were redundant or need improvement from a functional perspective, and completed a migration list for the target state. The modernization of the MQTT workflow code to serverless was time-consuming, decided to rehost on Amazon Elastic Compute Cloud (Amazon EC2) and modernization to Amazon Kinesis in to the next phase.
- Reviewed over 400 reports and dashboards, prioritized development in phases, and reassessed business user needs.
AWS cloud services chosen for proposed architecture:
- Data lake – We used Amazon S3 as the data lake to store the single truth of information for all raw and processed data, thereby reducing the copies of data storage and storage costs.
- Ingestion – Because we had multiple sources of truth in the current architecture, we arrived at a common structure before migration to Amazon S3, and existing pipelines were modified to do preprocessing. These one-time preprocessing jobs were run in Cloudera, because the source data was on-premises, and on Amazon EMR for data in the cloud. We designed new data pipelines for ingestion from transactional systems on the AWS cloud using AWS Glue ETL.
- Processing – Processing jobs were segregated based on runtime into two categories: batch and near-real time. Batch processes were further divided into transient Amazon EMR clusters with varying runtimes and Hadoop application requirements like HBase. Near-real-time jobs were provisioned in an Amazon EMR permanent cluster for clickstream analytics, and a data pipeline from transactional systems. We adopted a serverless approach using AWS Glue ETL for new data pipelines from transactional systems on the AWS cloud.
- Data warehouse – We chose Amazon Redshift as our data warehouse, and planned on how the data would be distributed based on query patterns.
- Visualization – We built the reports in Amazon QuickSight in phases and prioritized them based on business demand. We discussed with business users their current needs and identified the immediate reports required. We defined the phases of report and dashboard creation and built the reports in Amazon QuickSight. We plan to use embedded reports for external users in the future.
- Machine learning – Custom ML models were deployed on Amazon SageMaker. Existing Airflow DAGs were migrated to Amazon MWAA.
- Governance, security, and compliance – Governance with Amazon Lake Formation was adopted from Day 1. We configured the AWS Glue Data Catalog to reference data used as sources and targets. We had to comply to Payment Card Industry (PCI) guidelines because payment information was in the data lake, so we ensured the necessary security policies.
Solution overview
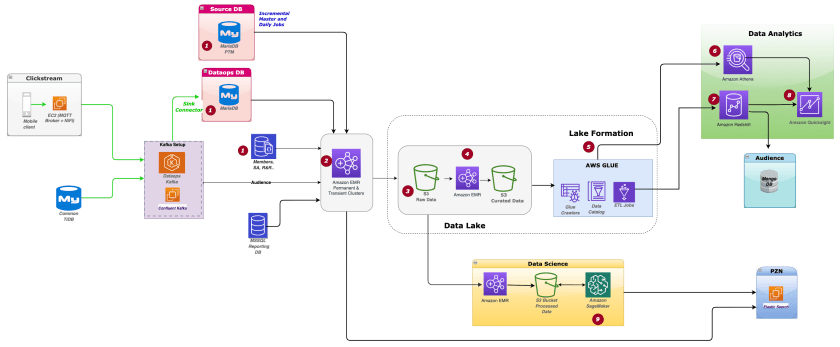
BMS modern data architecture
The following diagram illustrates our modern data architecture.

The architecture includes the following components:
- Source systems – These include the following:
- Data from transactional systems stored in MariaDB (booking and transactions).
- User interaction clickstream data via Kafka consumers to DataOps MariaDB.
- Members and seat allocation information from MongoDB.
- SQL Server for specific offers and payment information.
- Data pipeline – Spark jobs on an Amazon EMR permanent cluster process the clickstream data from Kafka clusters.
- Data lake – Data from source systems was stored in their respective Amazon S3 buckets, with prefixes for optimized data querying. For Amazon S3, we followed a hierarchy to store raw, summarized, and team or service-related data in different parent folders as per the source and type of data. Lifecycle polices were added to logs and temp folders of different services as per teams’ requirements.
- Data processing – Transient Amazon EMR clusters are used for processing data into a curated format for the audience, personalization, and analytics teams. Small file merger jobs merge the clickstream data to a larger file size, which saved costs for one-time queries.
- Governance – AWS Lake Formation enables the usage of AWS Glue crawlers to capture the schema of data stored in the data lake and version changes in the schema. The Data Catalog and security policy in AWS Lake Formation enable access to data for roles and users in Amazon Redshift, Amazon Athena, Amazon QuickSight, and data science jobs. AWS Glue ETL jobs load the processed data to Amazon Redshift at scheduled intervals.
- Queries – The analytics team used Amazon Athena to perform one-time queries raised from business teams on the data lake. Because report development is in phases, Amazon Athena was used for exporting data.
- Data warehouse – Amazon Redshift was used as the data warehouse, where the reports for the sales teams, management, and third parties (i.e., theaters and events) are processed and stored for quick retrieval. Views to analyze the total sales, movie sale trends, member behavior, and payment modes are configured here. We use materialized views for denormalized tables, different schemas for metadata, and transactional and behavior data.
- Reports – We used Amazon QuickSight reports for various business, marketing, and product use cases.
- Machine learning – Some of the models deployed on Amazon SageMaker are as follows:
- Content popularity – Decides the recommended content for users.
- Live event popularity – Calculates the popularity of live entertainment events in different regions.
- Trending searches – Identifies trending searches across regions.
Walkthrough
Migration execution steps
We standardized tools, services, and processes for data engineering, analytics, and data science:
- Data lake
- Identified the source data to be migrated from Archival DB, BigQuery, TiDB, and the analytics database.
- Built a canonical data model that catered to multiple business teams and reduced the copies of data, and therefore storage and operational costs. Modified existing jobs to facilitate migration to a canonical format.
- Identified the source systems, capacity required, anticipated growth, owners, and access requirements.
- Ran the bulk data migration to Amazon S3 from various sources.
- Ingestion
- Transaction systems – Retained the existing Kafka queues and consumers.
- Clickstream data – Successfully conducted a proof of concept to use AWS IoT Core for MQTT protocol. But because we needed to make changes in the application to publish to AWS IoT Core, we decided to implement it as part of mobile application modernization at a later time. We decided to rehost the MQTT server on Amazon EC2.
- Processing
- Listed the data pipelines relevant to business and migrated them with minimal modification.
- Categorized workloads into critical jobs, redundant jobs, or jobs that can be optimized:
- Spark jobs were migrated to Amazon EMR.
- HBase jobs were migrated to Amazon EMR with HBase.
- Metadata stored in Hive-based jobs were modified to use the AWS Glue Data Catalog.
- NiFi jobs were simplified and rewritten in Spark run in Amazon EMR.
- Amazon EMR clusters were configured one persistent cluster for streaming the clickstream and personalization workloads. We used multiple transient clusters for running all other Spark ETL or processing jobs. We used Spot Instances for task nodes to save costs. We optimized data storage with specific jobs to merge small files and compressed file format conversions.
- AWS Glue crawlers identified new data in Amazon S3. AWS Glue ETL jobs transformed and uploaded processed data to the Amazon Redshift data warehouse.
- Datawarehouse
- Defined the data warehouse schema by categorizing the critical reports required by the business, keeping in mind the workload and reports required in future.
- Defined the staging area for incremental data loaded into Amazon Redshift, materialized views, and tuning the queries based on usage. The transaction and primary metadata are stored in Amazon Redshift to cater to all data analysis and reporting requirements. We created materialized views and denormalized tables in Amazon Redshift to use as data sources for Amazon QuickSight dashboards and segmentation jobs, respectively.
- Optimally used the Amazon Redshift cluster by loading last two years data in Amazon Redshift, and used Amazon Redshift Spectrum to query historical data through external tables. This helped balance the usage and cost of the Amazon Redshift cluster.
- Visualization
- Amazon QuickSight dashboards were created for the sales and marketing team in Phase 1:
- Sales summary report – An executive summary dashboard to get an overview of sales across the country by region, city, movie, theatre, genre, and more.
- Live entertainment – A dedicated report for live entertainment vertical events.
- Coupons – A report for coupons purchased and redeemed.
- BookASmile – A dashboard to analyze the data for BookASmile, a charity initiative.
- Amazon QuickSight dashboards were created for the sales and marketing team in Phase 1:
- Machine learning
- Listed the ML workloads to be migrated based on current business needs.
- Priority ML processing jobs were deployed on Amazon EMR. Models were modified to use Amazon S3 as source and target, and new APIs were exposed to use the functionality. ML models were deployed on Amazon SageMaker for movies, live event clickstream analysis, and personalization.
- Existing artifacts in Airflow orchestration were migrated to Amazon MWAA.
- Security
- AWS Lake Formation was the foundation of the data lake, with the AWS Glue Data Catalog as the foundation for the central catalog for the data stored in Amazon S3. This provided access to the data by various functionalities, including the audience, personalization, analytics, and data science teams.
- Personally identifiable information (PII) and payment data was stored in the data lake and data warehouse, so we had to comply to PCI guidelines. Encryption of data at rest and in transit was considered and configured in each service level (Amazon S3, AWS Glue Data Catalog, Amazon EMR, AWS Glue, Amazon Redshift, and QuickSight). Clear roles, responsibilities, and access permissions for different user groups and privileges were listed and configured in AWS Identity and Access Management (IAM) and individual services.
- Existing single sign-on (SSO) integration with Microsoft Active Directory was used for Amazon QuickSight user access.
- Automation
- We used AWS CloudFormation for the creation and modification of all the core and analytics services.
- AWS Step Functions was used to orchestrate Spark jobs on Amazon EMR.
- Scheduled jobs were configured in AWS Glue for uploading data in Amazon Redshift based on business needs.
- Monitoring of the analytics services was done using Amazon CloudWatch metrics, and right-sizing of instances and configuration was achieved. Spark job performance on Amazon EMR was analyzed using the native Spark logs and Spark user interface (UI).
- Lifecycle policies were applied to the data lake to optimize the data storage costs over time.
Benefits of a modern data architecture
A modern data architecture offered us the following benefits:
- Scalability – We moved from a fixed infrastructure to the minimal infrastructure required, with configuration to scale on demand. Services like Amazon EMR and Amazon Redshift enable us to do this with just a few clicks.
- Agility – We use purpose-built managed services instead of reinventing the wheel. Automation and monitoring were key considerations, which enable us to make changes quickly.
- Serverless – Adoption of serverless services like Amazon S3, AWS Glue, Amazon Athena, AWS Step Functions, and AWS Lambda support us when our business has sudden spikes with new movies or events launched.
- Cost savings – Our storage size was reduced by 90%. Our overall spend on analytics and ML was reduced by 80%.
Conclusion
In this post, we showed you how a modern data architecture on AWS helped BMS to easily share data across organizational boundaries. This allowed BMS to make decisions with speed and agility at scale; ensure compliance via unified data access, security, and governance; and to scale systems at a low cost without compromising performance. Working with the AWS and Minfy Technologies teams helped BMS choose the correct technology services and complete the migration in four months. BMS achieved the scalability and cost-optimization goals with this updated architecture, which has set the stage for innovation using graph databases and enhanced our ML projects to improve customer experience.
About the Authors
Mahesh Vandi Chalil is Chief Technology Officer at BookMyShow, India’s leading entertainment destination. Mahesh has over two decades of global experience, passionate about building scalable products that delight customers while keeping innovation as the top goal motivating his team to constantly aspire for these. Mahesh invests his energies in creating and nurturing the next generation of technology leaders and entrepreneurs, both within the organization and outside of it. A proud husband and father of two daughters and plays cricket during his leisure time.
Priya Jathar is a Solutions Architect working in Digital Native Business segment at AWS. She has more two decades of IT experience, with expertise in Application Development, Database, and Analytics. She is a builder who enjoys innovating with new technologies to achieve business goals. Currently helping customers Migrate, Modernise, and Innovate in Cloud. In her free time she likes to paint, and hone her gardening and cooking skills.
Vatsal Shah is a Senior Solutions Architect at AWS based out of Mumbai, India. He has more than nine years of industry experience, including leadership roles in product engineering, SRE, and cloud architecture. He currently focuses on enabling large startups to streamline their cloud operations and help them scale on the cloud. He also specializes in AI and Machine Learning use cases.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.