
Introduction
Cerebras (CBRS) has been all over the news recently after the biggest IPO of 2026 with its valuation rising to $70B. Its stock initially surged 70% after the IPO meaning that they left tens of billions on the table and on Friday it tumbled to a price of $280 from its peak of $302. It is being portrayed as an Nvidia (NVDA) competitor making chips “58 times larger than any chip previously built” and claiming to have solved some issues that smaller GPUs have.
The five founding members sold SeaMicro to AMD and three years later founded Cerebras with the idea that a wafer-sized semiconductor brings many benefits. Cerebras started selling to educational institutions and life-sciences companies that were building supercomputers for drug discovery and research like AstraZeneca and the National Energy Technology Laboratory. After a few years of selling to customers in research labs and the government, Cerebras landed a big deal with the Abu Dhabi AI conglomerate G42 and in 2024 it accounted for 85% of its revenue. It then ventured into offering fast AI inference as a service and powered Meta’s Llama API, Perplexity and Mistral among others. Although Cerebras initially started as a chip provider for AI training, OpenAI (OPENAI) is betting on Cerebras’ inference potential by committing to buy $20B worth of computing capacity over the next three years. I say computing capacity and not chips because it is buying inference-as-a-service, just as Cerebras already provides to Llama, Mistral, Perplexity and AlphaSense. In March, Amazon struck a deal with Cerebras to make its chip, the WSE-3, available to cloud customers through Amazon Bedrock. It is basically letting AWS customers access Cerebras’ hardware without dealing with Cerebras ’directly. These deals are important but why are these companies betting billions of dollars on its computing capacity when Nvidia and AMD dominate the market?
What distinguishes Cerebras’ chips?
Instead of multiple GPUs coming out of the same wafer for them to be put in the same NVLink to work together, Cerebras’ WSE-3 chip is the size of the entire wafer. It is 58X bigger than an Nvidia GPU, has 4 trillion transistors, 900,000 AI cores and 44GB of on-chip SRAM. The CS-3 system is the system that houses the chip itself with cooling, power delivery, networking and I/O. Instead of using HBM like every other AI chip, the WSE-3 uses on-chip SRAM. This is very important because DRAM (HBM) has been a bottleneck for the past year as it is an essential component for a GPU to work during AI training and during inference. This distinction is important to make because each has its own issues, bottlenecks and uses of memory.
AI training involves using massive amounts of data to be processed by a model over and over with the use of GPUs. During training, the HBM feeds data to the GPU’s compute cores at high speeds. And together with NVIDIA’s full hardware ecosystem it is able to train AI. Although debatable, I don’t think there is a massive bottleneck here that the WSE-3 can solve and it still has major limitations that make it impossible for Cerebras to pose a real threat to Nvidia and the HBM companies. First of all, CUDA has been the standard programming model for AI for over a decade and every training framework assumes Nvidia hardware and ecosystem. Moreover, Nvidia’s GPUs are highly scalable, able to connect 100,000 GPUs, whereas Cerebras can only gang up together up to 16 WSE chips. It is becoming the norm for each GPU to have 8 stacks of HBM3e chips which is 288GB for a single GPU compared to WSE-3’s 44GB of SRAM.
The same things cannot be said for the inference part of an LLM. Inference is the actual interaction between the trained model and the user. Every time a user asks a question, the model needs to process the entire input all at once which is the prefill part of inference. This step does not require particularly fast memory as it is a lot like training in terms of computational use. The second step, the decoding part, is where the WSE-3 has the potential to shine. When a model understands a prompt, it generates a response one token (word) at a time. The model generates tokens serially — word 1, then word 2, then word 3 — with each depending on the previous one. This process is extremely memory bandwidth intensive and a massive bottleneck that causes tokens to be output more slowly. The problem is that the HBM sits outside the GPU and it is connected through a silicon interposer that makes data take a round trip that lasts tens of nanoseconds. This, combined with the fact that a model too big for one HBM gets split across multiple GPUs, increases latency and decreases bandwidth even more. The WSE-3 solves this problem as the SRAM is inside the chip which makes this whole interaction much more efficient. An Nvidia B200 HBM3e bandwidth is 8TB/s while A WSE-3 on-chip SRAM bandwidth is 21,000 TB/s; that’s a 2,600X difference. While software advances and optimization have made Nvidia’s performance actually reduce this massive difference in bandwidth, the same software improvement will happen to the WSE-3. Fundamentally, this is a physical advantage that cannot be just beaten by Nvidia’s GPU. We have seen evidence of this as 3 of the 10 fastest models use Cerebras computation.
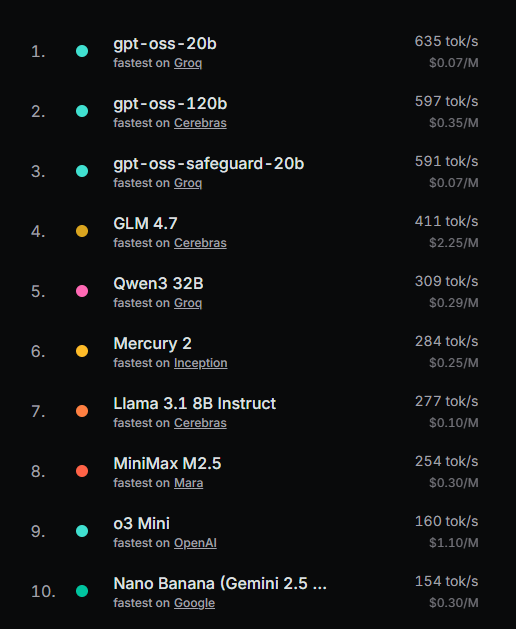
openrouter.ai
This speed advantage is what I believe investors would be betting on when buying the stock. The issue that I see is that when it comes to LLMs, people are not going to pay a premium for a model to take 0.5 seconds instead of 3 to respond. The real opportunity and reason why OpenAI signed a $20 billion deal is the massive AI agent boom. AI agents perform multistep tasks where each step involves one or more inference calls to the model. The total AI tokens consumed per week has increased from 103 billion in August of 2024 to 4 trillion in August of 2025.
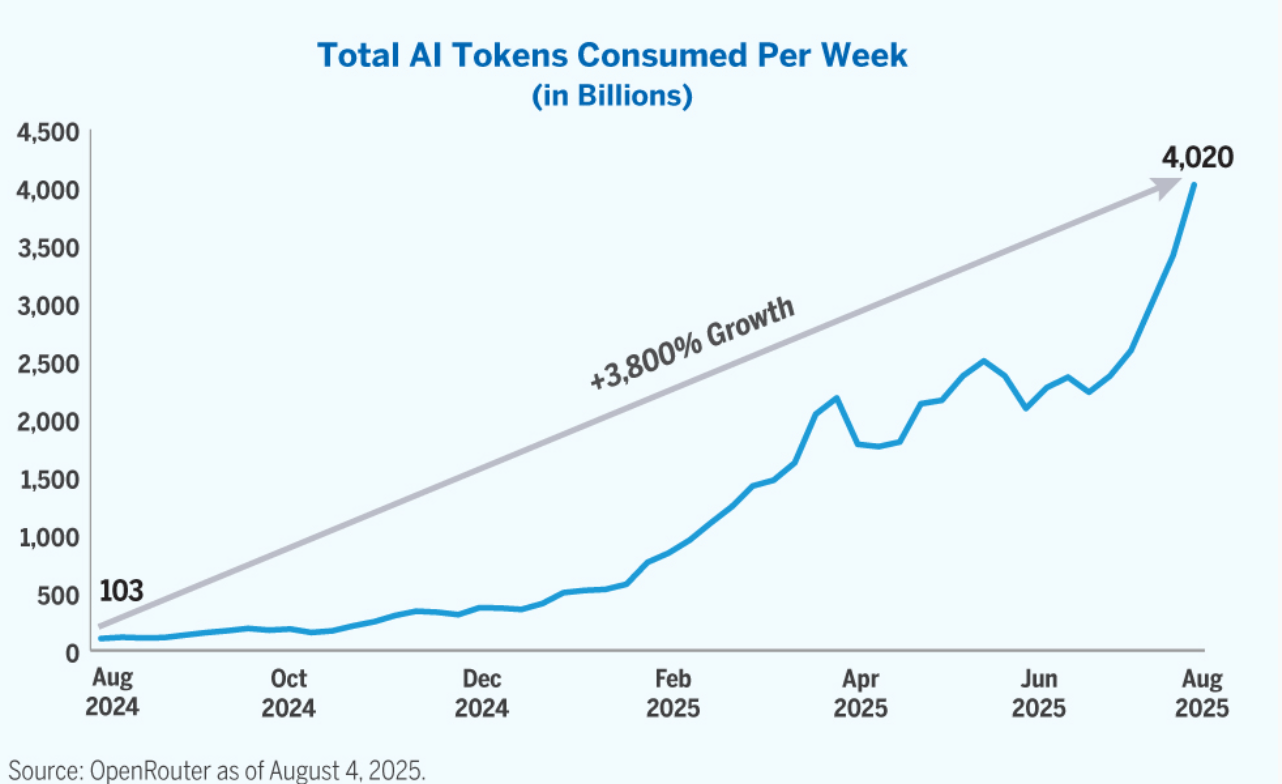
Alger.com
Models are becoming more capable and more complex agents will use more tokens faster. This is an example of Jevons paradox where the token prices have plummeted, but the use of them has risen way more as use cases for agents in every industry have increased. Each generation of the HBM has become faster with the HBM2e delivering 2TB/s, HBM3 3.35 TB/s, the HBM3e 4.8 TB/s and the HBM4 expected to reach 6-8TB/s, this is a 30-50% improvement each generation but the number of tokens used increases in a much higher order of magnitude. In the future, an agent that takes 2 hours to complete a complex task on GPU infrastructure may take a few minutes on Cerebras. Agents that are time sensitive and need to act fast such as those involved in hospitals, AVs, trading etc. will require Cerebras’s infrastructure with no way around it. Nvidia, however, is also conscious about this whole speed constraint and recently acquired Groq for $20 B.
Nvidia‘s response and threat to Cerebras
Although 3 of the 10 fastest models use Cerebras’ infrastructure, other 3 of the fastest models use Groq’s infrastructure. Groq’s LPU also uses SRAM and has the advantage of making inferences fast. I believe Nvidia’s acquisition of Groq is to create a faster chip with SRAM to compete in the fast inference space. On March 16 Nvidia revealed the NVIDIA Groq 3 LPX “designed for the low-latency and large-context demands of agentic systems”. “The LPX rack with 256 LPU processors features 128GB of on-chip SRAM and 640 TB/s of scale-up bandwidth.” The 640 TB/s of bandwidth is impressive but still nothing compared to WSE-3’s 21,000 TB/s (33X) more. This difference is again due to one simple reason: physics. There are still 256 LPU chips connected that still make data latency and bandwidth inefficient. The only way to achieve the bandwidth and latency of the WSE-3 is to build a wafer-sized chip which involves reinventing the architecture, engineering, philosophy and strategy of Nvidia’s chip designing process.
Conclusion
Cerebras has a physical advantage over other GPUs when it comes to inference. Inference has a large bottleneck that tends to become a real issue when tokens used by AI agents significantly outstrip the computational capacity of the current and future HBM generations. Cerebras is the only company to produce wafer-sized chips which involved a complex architecture and engineering. The same reason why AMD cannot make Nvidia’s GPUs is also the reason why I think it will take a long time for companies to replicate a wafer-sized chip. I believe that as AI agents become adopted, it is inevitable for fast AI agents in uses like robots, AVs, and trading to depend on Cerebras’ computation. Although Nvidia is also venturing into this space through its chip with Groq and the expertise it acquired, the only competitive solution I see is making bigger chips for zero latency and high bandwidth. I see risks with this such as its reliance on OpenAI and the fact that this is a new IPO and a new venture with no evidence of execution. I will remain alert to any demand developments from OpenAI and especially AWS and how the whole Agentic AI industry is developing. I rate it a Buy.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.