
エクサ(Exa)というスタートアップ企業が、生成検索に新たな旋風を巻き起こそうとしている。大規模言語モデル(LLM)の基盤となる技術を使用することで、グーグルやオープンAI(OpenAI)を含む競合他社の検索エンジンよりも的確な検索結果のリストを返すことができると同社は主張している。その目的は、インターネット上の膨大で混沌としたWebページをルックアップテーブルに変え、クエリ(問い合わせ)が特定の正確な結果を返せるようにすることだ。
エクサはすでに、検索エンジンの上に独自のアプリケーションを構築したい企業に、バックエンドサービスとして検索エンジンを提供している。12月3日、同社はその検索エンジンの最初の消費者向けバージョンである「Webセッツ(Websets)」を発表した。
「Webはデータの集合体ですが、混沌としています」とエクサの共同創業者で最高経営責任者(CEO)のウィル・ブライクは言う。「こっちにはジョー・ローガンの動画があり、あっちにはアトランティック(Atlantic)誌の記事があります。整理されていません。私の夢は、ウェブがデータベースのように感じられるようになることです」。
ウェブセッツは、他の検索エンジンが苦手とする、人や企業のタイプといったものを検索する必要のあるパワーユーザーを対象としている。「未来的なハードウェアを作るスタートアップ企業」と検索すれば、数百の特定の企業のリストが表示される。そのキーワードを含むというだけで、該当するものもあれば、しないものもあるようなウェブページへのリンクではない。グーグルにはそれができない、とブライクCEOは言う。「投資家や人材採用担当者、あるいはウェブから特定のデータセットを求めている人たちにとって、多くの貴重なユースケースがあります」。
MITテクノロジーレビューは2021年に、グーグルの研究者たちが新種の検索エンジンで大規模言語モデルの使用を模索しているというニュースを報じた。それ以来、状況は急速に変化している。このアイデアはすぐに激しい批判を浴びた。しかし、テック企業はほとんど気に留めなかった。それから3年、グーグルやマイクロソフトのような巨大企業が、パープレキシティ(Perplexity)や10月にチャットGPT検索(ChatGPT Search)を発表したオープンAIのような数多くの話題の新参者とともに、このホットな新しいトレンドの一角をめぐってしのぎを削っている。
エクサは(まだ)こうした企業のいずれにも勝とうとはしていない。その代わり、新しいことを提案している。他のほとんどの検索エンジン企業は、既存の検索エンジンに大規模言語モデルを組み込み、そのモデルを使ってユーザーのクエリを分析し、結果を要約する。しかし、検索エンジン自体はほとんど変わっていない。たとえば、パープレキシティは依然としてグーグル検索やビング(Bing)にクエリを送っている。現在の人工知能(AI)検索エンジンは、焼きたてのパンに古くなった具を挟んだサンドイッチのようなものだと考えるといいだろう。
エクサは、よくあるリンクのリストをユーザーに提供するが、大規模言語モデルの基盤となる技術を使って、検索方法そのものを刷新している。基本的なアイデアは次の通りだ。グーグルはウェブをクロールし、キーワードの膨大なインデックスを構築し、ユーザーのクエリにマッチさせる。エクサはウェブをクロールし、ウェブページの内容を「埋め込み表現(embedding)」という形式にエンコードすることで、それを大規模言語モデルで処理できるようにする。
埋め込み表現は、似たような意味を持つ単語が似たような値を持つ数値になるように、単語を数値に変換する。つまり、これによってエクサは、キーワードだけでなく、ウェブページ上のテキストの意味を捉えることができるのだ。
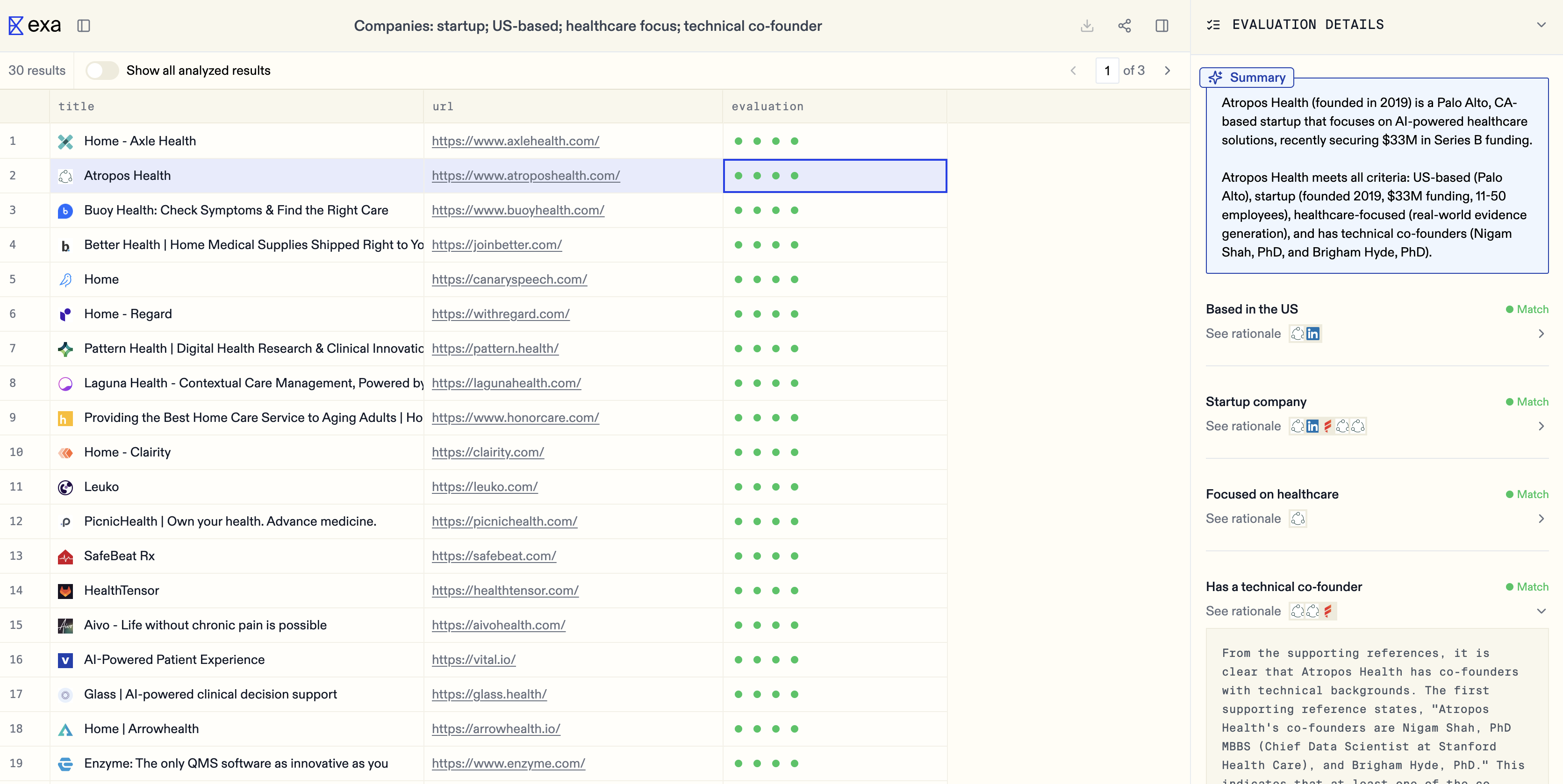
「企業; スタートアップ; 米国拠点; 保健医療にフォーカス; 技術担当共同創業者」の検索結果を示すウェブセッツのスクリーンショット。
大規模言語モデルは、埋め込み表現を使って文中の次の単語を予測する。エクサの検索エンジンは次のリンクを予測する。「未来的なハードウェアを作るスタートアップ企業」と入力すると、モデルはそのフレーズに続く可能性のある(実際の)リンクを導き出す。
しかし、エクサのアプローチにはマイナス面もある。キーワードをインデックス化するのではなく、ページをエンコードするのには時間もコストもかかる。エクサは約10億のウェブページをエンコードしたとブライクCEOは言う。約1兆のインデックスを持つグーグルに比べれば、それはごくわずかだ。しかし、同CEOはこの点を問題視しておらず、「役に立つのに、ウェブ全体を埋め込む必要はありません」と言う。(興味深い事実:「エクサ(exa)」は 10の18乗、つまり「1」の後に 18個の「0」があることを意味し、「グーゴル(googol)」は10の100乗、つまり「1」の後に100個の「0」があることを意味する。)
ウェブセッツは検索結果を返すのが非常に遅い。検索に数分かかることもある。しかし、それだけの価値があるとブライクCEOは主張する。「私たちの顧客の多くは、何千、何万という検索結果を求めるようになりました。そのような顧客は、コーヒーを飲みに行って、戻ってきたときに巨大なリストを受け取ることができれば、それで構わないと考えていました」。
「何を探しているのかよくわからないときに、エクサが一番役に立つと思います」と、エクサの検索エンジンを使ったことのあるスタンフォード大学のコンピューター科学専攻の学生、アンドリュー・ガオは言う。「たとえば、『金融分野のLLMに関する興味深いブログ記事』というクエリでは、パープレキシティよりもエクサの方がうまく検索できます」。しかし、両者が得意とすることは異なるとガオは指摘する。「私は両方を目的に応じて使い分けています」。
「埋め込み表現は、実世界の人、場所、物のような実体を表す素晴らしい方法だと思います」と、ナレッジグラフを使って別の種類の検索エンジンを構築している企業、ディフボット(Diffbot)のCEOであるマイク・タンは話す。しかし、文章全体やテキストページ全体を埋め込もうとすると、多くの情報を失うことになるとタンは指摘する。「戦争と平和を1つの埋め込み表現として表すと、そのストーリーの中で起こった具体的な出来事のほとんどすべてが失われ、そのジャンルと時代についての一般的な感覚だけが残ることになります」。
ブライクCEOは、エクサが未完成であることを認めている。また、他の限界についても指摘している。たとえば、テイラー・スウィフトのボーイフレンドの名前や、ウィル・ブライクとは誰なのか、といった単一の情報を調べたい場合、エクサはライバルの検索エンジンにはかなわない。「私の名字がポーランド人の名字なので、ポーランド人っぽい名前の人物が検索結果にたくさん出てきます。埋め込み表現は正確なキーワードとのマッチングを苦手としています」と同CEOは言う。
今のところ、エクサは必要に応じてキーワードを混ぜることでこの問題を回避している。しかし、ブライクCEOは強気だ。「弱点を補う必要がなくなるまで埋め込み表現の手法を改善していくつもりです」。
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.