
Spaceborne data collection is increasingly common. For the application of artificial intelligence, stored archives of data are necessary for machine learning. The need to build a cloud-based solution for geospatial analysis has become more important to enable enterprises and governments to drive better-informed business and tactical decisions.
This architecture is designed to show an end-to-end implementation that involves extracting, loading, transforming, and analyzing spaceborne data by using geospatial libraries and AI models with Azure Synapse Analytics. This article also shows how to integrate geospatial-specific Azure Cognitive Services models, AI models from partners, bring-your-own-data, and AI models that use Azure Synapse Analytics.
The intended audience for this document is users with intermediate skill levels in the geospatial space.
An implementation of this architecture is available on GitHub.
Apache®, Apache Ignite, Ignite, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Potential use cases
This solution is ideal for the aerospace industry. It addresses these scenarios:
- Raster data ingestion and processing
- Object detection via pre-trained AI models
- Classification of land masses via AI models
- Monitoring changes in the environment via AI models
- Derived datasets from preprocessed imagery sets
- Vector visualization / small-area consumption
- Vector data filtering and cross-data joins
Architecture
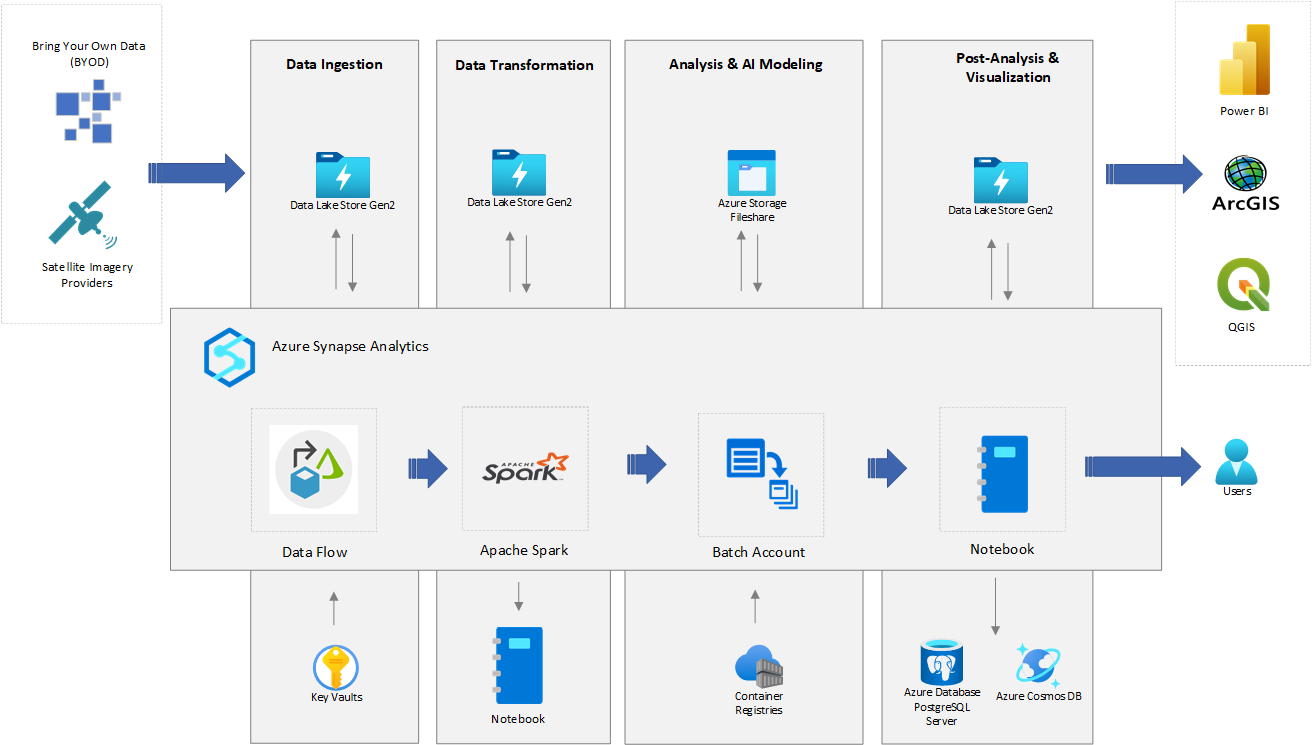
Download a Visio file of this architecture.
Dataflow
The following sections describe the stages in the architecture.
Data ingestion
Spaceborne data is pulled from data sources like Airbus, NAIP/USDA (via the Planetary Computer API), and Maxar. Data is ingested into Azure Data Lake Storage.
Azure Synapse Analytics provides various pipelines and activities, like Web activity, Data Flow activity, and Custom activities, to connect to these sources and copy the data into Data Lake Storage.
Azure Synapse Custom activities run your customized code logic on an Azure Batch pool of virtual machines or in Docker-compatible containers.
Data transformation
The data is processed and transformed into a format that analysts and AI models can consume. Geospatial libraries, including GDAL, OGR, Rasterio, and GeoPandas, are available to perform the transformation.
Azure Synapse Spark pools provide the ability to configure and use these libraries to perform the data transformations. You can also use Azure Synapse Custom activities, which use Azure Batch pools.
An Azure Synapse notebook is a web interface that you can use to create files that contain live code, visualizations, and narrative text. Notebooks are a good place to validate ideas, define transformations, and do quick experiments to get insights from your data and build a pipeline. In the sample code, the GDAL library is used in a Spark pool to perform data transformations. For more information, see the sample code section of this article.
The sample solution implements this pipeline from this data transformation step. The sample is written with the assumption that data is copied in Data Lake Storage by the data ingestion methods described earlier. It demonstrates implementation of this pipeline for raster data processing.
Analysis and execution of AI models
The Azure Synapse notebook environment analyzes and runs AI models.
AI models developed with services like the Cognitive Services Custom Vision model, trained in their own environment, and packaged as Docker containers are available in the Azure Synapse environment.
In the Azure Synapse environment, you can also run AI models that are available from partners for various capabilities like object detection, change detection, and land classification. These models are trained in their own environment and packaged as Docker containers.
Azure Synapse can run such AI models via a Custom activity that runs code in Batch pools as executables or Docker containers. The sample solution demonstrates how to run a Custom Vision AI model as part of an Azure Synapse pipeline for object detection over a specific geospatial area.
Post-analysis and visualization
- For further analysis and visualization, output from analysis and execution of the AI models can be stored in Data Lake Storage, data-aware databases like Azure Database for PostgreSQL, or Azure Cosmos DB. The sample solution shows how to transform AI model output and store it as GeoJSON data in Data Lake Storage and Azure Database for PostgreSQL. You can retrieve and query the output from there.
- For visualization:
- You can use licensed tools like ArcGIS Desktop or open-source tools like QGIS.
- You can use Power BI to access GeoJSON from various data sources and visualize the geographic information system (GIS) data.
- You can use client-side geospatial JavaScript-based libraries to visualize the data in web applications.
Components
Data sources
- Imagery providers.
- Bring your own data. Copy your own data to Data Lake Storage.
Data ingestion
- Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Azure Synapse contains the same Data Integration engine and experiences as Azure Data Factory, so you can create at-scale ETL pipelines without leaving Azure Synapse.
- Azure Data Lake Storage is dedicated to big data analytics, and is built on Azure Blob Storage.
- Azure Batch enables you to run and scale a large number of batch computing jobs on Azure. Batch tasks can run directly on virtual machines (nodes) in a Batch pool, but you can also set up a Batch pool to run tasks in Docker-compatible containers on the nodes.
- An Azure Synapse Custom activity runs customized code logic on an Azure Batch pool of virtual machines or in Docker containers.
- Azure Key Vault stores and controls access to secrets like tokens, passwords, and API keys. Key Vault also creates and controls encryption keys and manages security certificates.
Data transformation
The following geospatial libraries and packages are used together for transformations. These libraries and packages are installed in a serverless Spark pool, which is then attached to an Azure Synapse notebook. For information on installing the libraries, see Install geospatial packages in an Azure Synapse Spark pool, later in this article.
- Geospatial libraries
- GDAL is a library of tools for manipulating spaceborne data. GDAL works on raster and vector data types. It’s a good tool to know if you’re working with spaceborne data.
- Rasterio is a module for raster processing. You can use it to read and write several different raster formats in Python. Rasterio is based on GDAL. When the module is imported, Python automatically registers all known GDAL drivers for reading supported formats.
- GeoPandas is an open-source project that can make it easier to work with spaceborne data in Python. GeoPandas extends the data types used by Pandas to allow spatial operations on geometric types.
- Shapely is a Python package for set-theoretic analysis and manipulation of planar features. It uses (via Python’s ctypes module) functions from the widely deployed GEOS library.
- pyproj performs cartographic transformations. It converts from longitude and latitude to native map projection x, y coordinates, and vice versa, by using PROJ.
- Azure Batch enables you to run and scale a large number of batch computing jobs on Azure.
- Azure Synapse notebooks is a web interface for creating files that contain live code, visualizations, and narrative text. You can add existing Azure Synapse notebooks to an Azure Synapse pipeline by using the Notebook activity.
- Apache Spark pool provides the ability to configure and use libraries to perform data transformations. You can add existing Spark jobs to an Azure Synapse pipeline by using the Spark Job Definition activity.
Analysis and AI modeling
- Azure Synapse provides machine learning capabilities.
- Azure Batch enables you to run and scale a large number of batch computing jobs on Azure. In this solution, the Azure Synapse Custom activity is used to run Docker-based AI models on Azure Batch pools.
- Azure Cognitive Services provides the ability to embed vision into your apps. You can use Custom Vision, a component of Cognitive Services, to customize and embed state-of-the-art computer vision image analysis for specific domains.
- You can also use bring-your-own AI models and Microsoft partner AI models like blackshark.ai.
Post-analysis and visualization
- Azure Database for PostgreSQL is a fully managed relational database service designed for hyperscale workloads. It supports spaceborne data via the PostGIS extension.
- Azure Cosmos DB supports indexing and querying of geospatial point data that’s represented in GeoJSON.
- Power BI is an interactive data visualization tool for building reports and dashboards. You can get insights on spaceborne data from Esri ArcGIS Maps.
- QGIS is a free open-source GIS for creating, editing, visualizing, analyzing, and publishing geospatial information.
- ArcGIS Desktop is licensed product provided by Esri. You can use it to create, analyze, manage, and share geographic information.
Alternatives
If you want to run containerized AI models that you can call from Azure Synapse, you can use Azure Kubernetes Service, Azure Container Instances, or Azure Container Apps.
Azure Databricks provides an alternative for hosting an analytics pipeline.
Spark in Azure HDInsight provides an alternative for using geospatial libraries in the Apache Spark environment.
Here are some alternative libraries and frameworks that you can use for geospatial processing:
- Apache Sedona, formerly named GeoSpark, is a cluster computing system for processing large-scale spatial data. Sedona extends Spark and Spark SQL with out-of-the-box Spatial Resilient Distributed Datasets and SpatialSQL that efficiently load, process, and analyze large-scale spatial data across machines.
- Dask for Python is a parallel computing library that scales the existing Python ecosystem.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Operational excellence
If you collaborate by using Git for source control, you can use Synapse Studio to associate your workspace with a Git repository, Azure DevOps, or GitHub. For more information, see Source control in Synapse Studio.
- In an Azure Synapse workspace, CI/CD moves all entities from one environment (development, test, production) to another environment.
- You can use Azure DevOps release pipelines and GitHub Actions to automate the deployment of an Azure Synapse workspace to multiple environments.
Performance
- Azure Synapse supports Apache Spark 3.1.2, which is more performant than its predecessors.
- For information about Spark pool scaling and node sizes, see Spark pools in Azure Synapse Analytics.
- With Azure Batch, you can scale out intrinsically parallel for transformations submitted in an Azure Synapse Custom activity. Azure Batch supports specialized GPU-optimized VM sizes that you can use to run AI models.
Reliability
For SLA information, see Azure Synapse SLA.
Security
See these articles for security best practices:
Cost optimization
These resources provide information about pricing and cost optimization:
Note
For pricing and license terms for partner AI models, see the partner’s documentation.
Deploy this scenario
A Bicep deployment of the sample solution is available. To get started with this deployment, see these instructions.
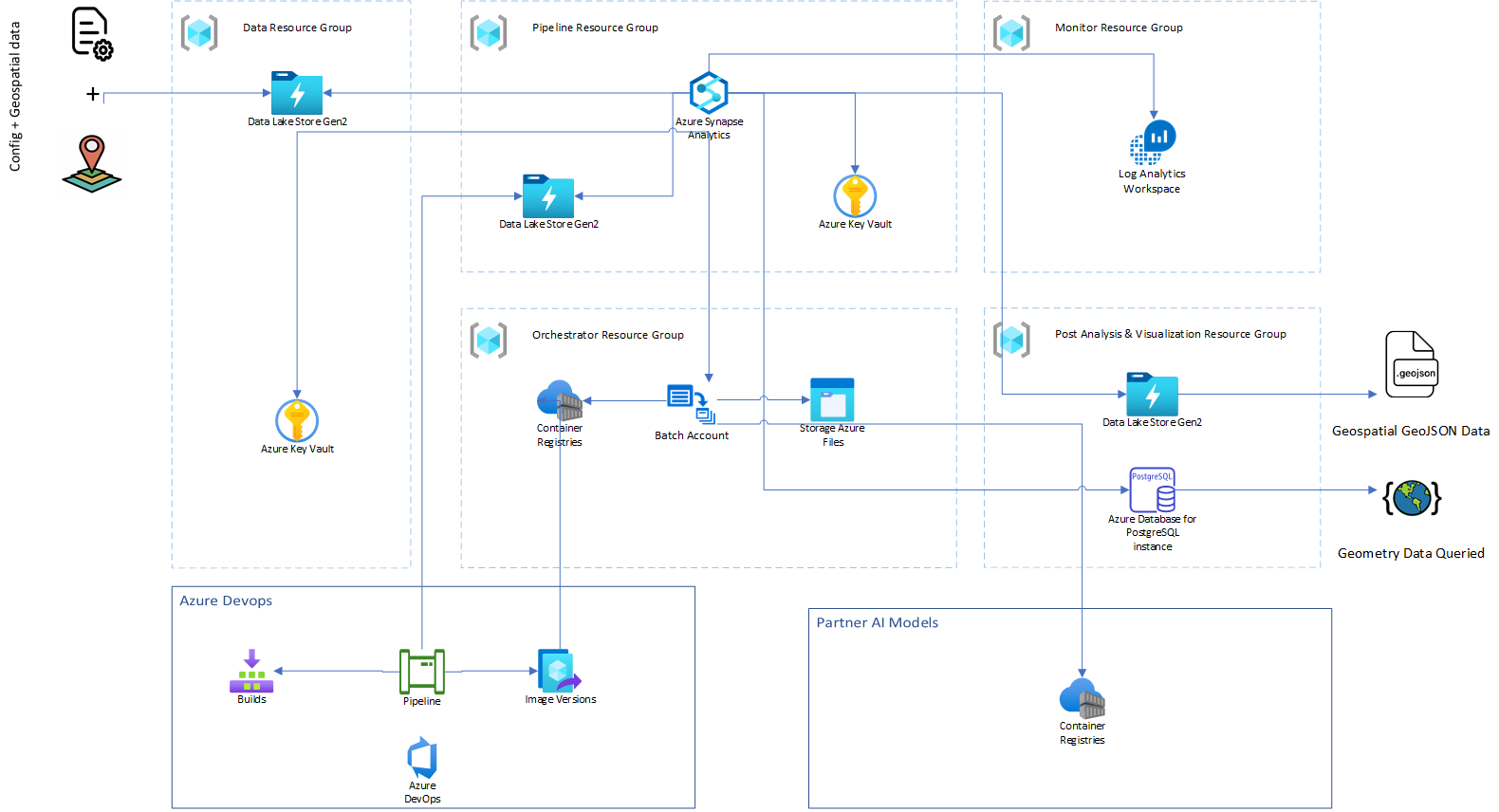
Download a Visio file of this architecture.
Limitations
This architecture demonstrates an end-to-end geoprocessing and analytics solution that uses Azure Synapse. This sample implementation is targeted for a small to medium area of interest and limited concurrent geoprocessing of raster data.
Sample code
The following instructions describe how to read, write, and apply transformations to raster data that’s stored in Azure Data Lake Storage by using a Synapse notebook. The intention is more to demonstrate the use of libraries in Synapse notebooks than to demonstrate the transformation.
Prerequisites
Instructions
- Print information from the raster data:
from osgeo import gdal gdal.UseExceptions() access_key = TokenLibrary.getSecret('<key-vault-name>','<secret-name>') gdal.SetConfigOption('AZURE_STORAGE_ACCOUNT', '<storage_account_name>') gdal.SetConfigOption('AZURE_STORAGE_ACCESS_KEY', access_key) dataset_info = gdal.Info('/vsiadls/aoa/input/sample_image.tiff') #/vsiadls/<container_name>/path/to/image print(dataset_info)Note
/vsiadls/is a file system handler that enables on-the-fly random reading of primarily non-public files that are available in Azure Data Lake Storage file systems. Prior download of the entire file isn’t required./vsiadls/is similar to/vsiaz/. It uses the same configuration options for authentication. Unlike/vsiaz/,/vsiadls/provides real directory management and Unix-style ACL support. For some features, hierarchical support needs to be turned on in Azure storage. For more information, see the/vsiadls/documentation.Driver: GTiff/GeoTIFF Files: /vsiadls/naip/input/sample_image.tiff Size is 6634, 7565 Coordinate System is: PROJCRS["NAD83 / UTM zone 16N", BASEGEOGCRS["NAD83", DATUM["North American Datum 1983", ELLIPSOID["GRS 1980",6378137,298.257222101, LENGTHUNIT["metre",1]]], PRIMEM["Greenwich",0, ANGLEUNIT["degree",0.0174532925199433]], ID["EPSG",4269]], CONVERSION["UTM zone 16N", METHOD["Transverse Mercator", ID["EPSG",9807]], PARAMETER["Latitude of natural origin",0, ANGLEUNIT["degree",0.0174532925199433], ID["EPSG",8801]], PARAMETER["Longitude of natural origin",-87, ANGLEUNIT["degree",0.0174532925199433], ID["EPSG",8802]], PARAMETER["Scale factor at natural origin",0.9996, SCALEUNIT["unity",1], ID["EPSG",8805]], PARAMETER["False easting",500000, LENGTHUNIT["metre",1], ID["EPSG",8806]], PARAMETER["False northing",0, LENGTHUNIT["metre",1], ID["EPSG",8807]]], CS[Cartesian,2], AXIS["(E)",east, ORDER[1], LENGTHUNIT["metre",1]], AXIS["(N)",north, ORDER[2], LENGTHUNIT["metre",1]], USAGE[ SCOPE["Engineering survey, topographic mapping."], AREA["North America - between 90°W and 84°W - onshore and offshore. Canada - Manitoba; Nunavut; Ontario. United States (USA) - Alabama; Arkansas; Florida; Georgia; Indiana; Illinois; Kentucky; Louisiana; Michigan; Minnesota; Mississippi; Missouri; North Carolina; Ohio; Tennessee; Wisconsin."], BBOX[23.97,-90,84,-84]], ID["EPSG",26916]] Data axis to CRS axis mapping: 1,2 Origin = (427820.000000000000000,3395510.000000000000000) Pixel Size = (1.000000000000000,-1.000000000000000) Metadata: AREA_OR_POINT=Area Image Structure Metadata: COMPRESSION=DEFLATE INTERLEAVE=PIXEL LAYOUT=COG PREDICTOR=2 Corner Coordinates: Upper Left ( 427820.000, 3395510.000) ( 87d45'13.12"W, 30d41'24.67"N) Lower Left ( 427820.000, 3387945.000) ( 87d45'11.21"W, 30d37'18.94"N) Upper Right ( 434454.000, 3395510.000) ( 87d41' 3.77"W, 30d41'26.05"N) Lower Right ( 434454.000, 3387945.000) ( 87d41' 2.04"W, 30d37'20.32"N) Center ( 431137.000, 3391727.500) ( 87d43' 7.54"W, 30d39'22.51"N) Band 1 Block=512x512 Type=Byte, ColorInterp=Red Overviews: 3317x3782, 1658x1891, 829x945, 414x472 Band 2 Block=512x512 Type=Byte, ColorInterp=Green Overviews: 3317x3782, 1658x1891, 829x945, 414x472 Band 3 Block=512x512 Type=Byte, ColorInterp=Blue Overviews: 3317x3782, 1658x1891, 829x945, 414x472 Band 4 Block=512x512 Type=Byte, ColorInterp=Undefined Overviews: 3317x3782, 1658x1891, 829x945, 414x472 - Convert GeoTiff to PNG by using GDAL:
from osgeo import gdal gdal.UseExceptions() access_key = TokenLibrary.getSecret('<key-vault-name>','<secret-name>') gdal.SetConfigOption('AZURE_STORAGE_ACCOUNT', '<storage_account_name>') gdal.SetConfigOption('AZURE_STORAGE_ACCESS_KEY', access_key) tiff_in = "/vsiadls/aoa/input/sample_image.tiff" #/vsiadls/<container_name>/path/to/image png_out = "/vsiadls/aoa/input/sample_image.png" #/vsiadls/<container_name>/path/to/image options = gdal.TranslateOptions(format='PNG') gdal.Translate(png_out, tiff_in, options=options) - Store GeoTiff images in Azure Data Lake Storage.
Because of how data is stored in the cloud and the fact that the file handlers
/vsiaz/and/vsiadls/support only sequential writes, we use the file mount feature available in the mssparkutils package. After the output is written to a mount location, copy it to Azure Data Lake Storage as shown in this sample transformation:import shutil import sys from osgeo import gdal from notebookutils import mssparkutils mssparkutils.fs.mount( "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net", "/<mount_path>", {"linkedService":"<linked_service_name>"} ) access_key = TokenLibrary.getSecret('<key-vault-name>','<secret-name>') gdal.SetConfigOption('AZURE_STORAGE_ACCOUNT', '<storage_account_name>') gdal.SetConfigOption('AZURE_STORAGE_ACCESS_KEY', access_key) options = gdal.WarpOptions(options=['tr'], xRes=1000, yRes=1000) gdal.Warp('dst_img.tiff', '/vsiadls/<container_name>/path/to/src_img.tiff', options=options) jobId = mssparkutils.env.getJobId() shutil.copy("dst_img.tiff", f"/synfs/{jobId}/<mount_path>/path/to/dst_img.tiff")In Azure Synapse, you can add Azure Data Lake Storage as one of the linked services. For instructions, see Linked services.
Sample solution
An implementation of this architecture is available on GitHub.
This diagram shows the steps in the sample solution:
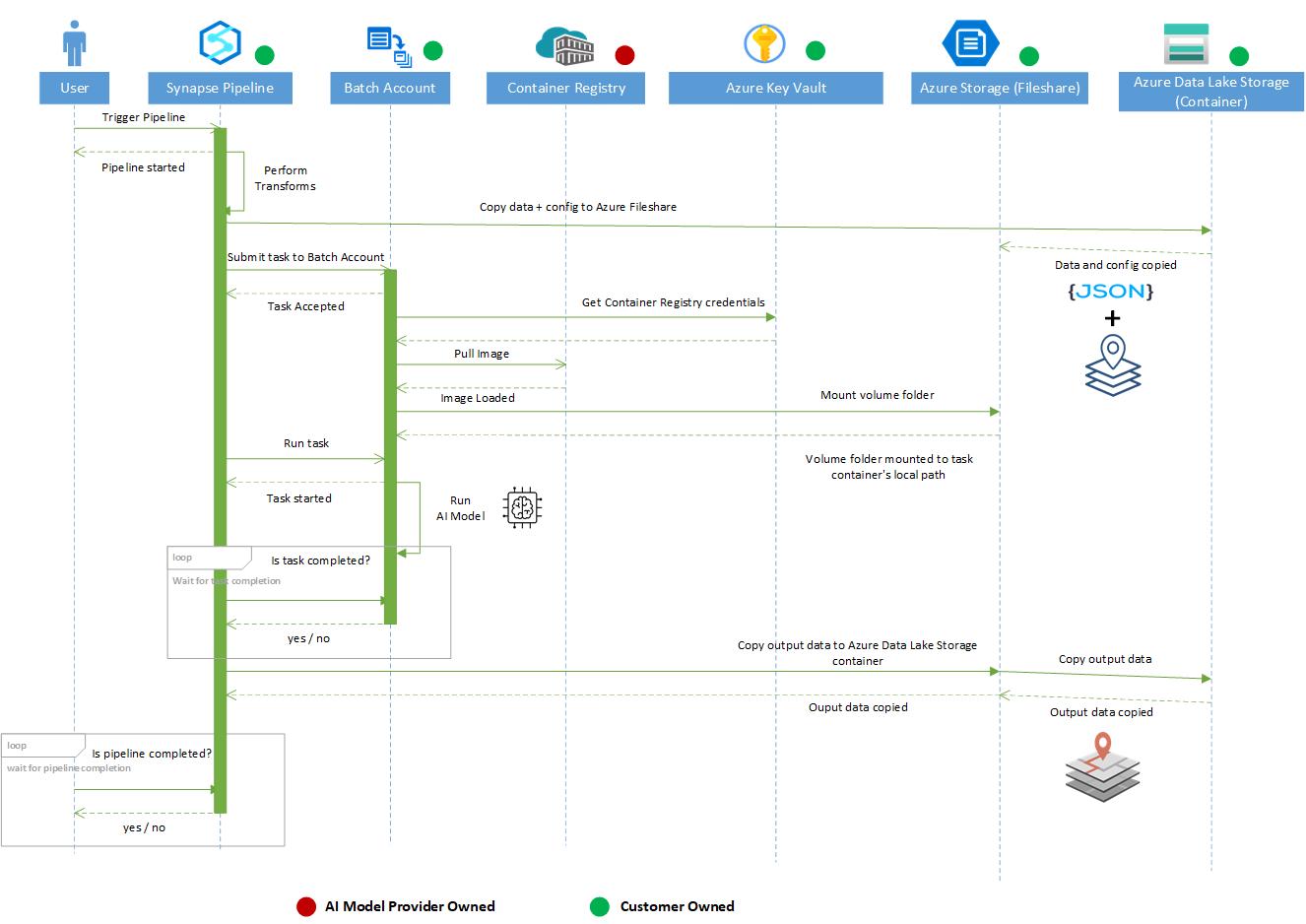
Download a Visio file of this architecture.
Note
The data is pulled from spaceborne data sources and copied to Azure Data Lake Storage. The data ingestion isn’t part of the reference implementation.
- An Azure Synapse pipeline reads the spaceborne data from Azure Data Lake Storage.
- The data is processed with the GDAL library in an Azure Synapse notebook.
- The processed data is stored in Azure Data Lake Storage.
- The processed data is read from Azure Data Lake Storage and passed to object detection Custom Vision AI models by an Azure Synapse Custom activity.
The Custom activity uses Azure Batch pools to run the object detection model.
- The object detection model outputs a list of detected objects and bounding boxes.
- The detected objects are converted to GeoJSON and stored in Azure Data Lake Storage.
- The GeoJSON data is read from Azure Data Lake Storage and stored in a PostgreSQL database.
- The data is read from the PostgreSQL database. It can be visualized further in tools like ArcGIS Pro, QGIS, and Power BI.
Install geospatial packages in an Azure Synapse Spark pool
You need to install the packages in an Azure Synapse Spark pool by using the package management feature. For more information, see Azure Synapse package management.
To support geospatial workloads on Azure Synapse, you need libraries like GDAL, Rasterio, and GeoPandas. You can install these libraries on a serverless Apache Spark pool by using a YAML file. Anaconda libraries are pre-installed on the Spark pool.
Prerequisites
Instructions
- The following libraries and packages are available in the environment.yml file. You can use this file to install the libraries in the Spark pools.
name: aoi-env channels: - conda-forge - defaults dependencies: - azure-storage-file-datalake - gdal=3.3.0 - libgdal - pip>=20.1.1 - pyproj - shapely - pip: - rasterio - geopandasNote
GDAL uses virtual file system
/vsiadls/for Azure Data Lake Storage. This functionality is available starting in GDAL v3.3.0. Be sure to use version 3.3.0 or later. - Go to https://web.azuresynapse.net and sign in to your workspace.
- Select Manage in the navigation pane and then select Apache Spark pools.
- Select Packages by selecting the ellipsis button (…) on the Spark pool. Upload the environment.yml file from local and apply the package settings.
- The notification section of the portal notifies you when the installation is complete. You can also track installation progress by taking these steps:
- Go to the Spark applications list on the Monitor tab.
- Select the SystemReservedJob-LibraryManagement link that corresponds to your pool update.
- View the driver logs.
- Run the following code to verify that the correct versions of the libraries installed. The pre-installed libraries that Conda installs will also be listed.
import pkg_resources for d in pkg_resources.working_set: print(d)
For more information, see Manage packages.
Contributors
This article is being updated and maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
Additional contributors:
Next steps
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.