
on EKS is a deployment option that enables you to run Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) easily. It allows you to innovate faster with the latest Apache Spark on Kubernetes architecture while benefiting from the performance-optimized Spark runtime powered by Amazon EMR. This deployment option elects Amazon EKS as its underlying compute to orchestrate containerized Spark applications with better price performance.
continually innovates to provide choice and better price-performance for our customers, and the third-generation Graviton processor is the next step in the journey. Amazon EMR on EKS now supports Amazon Elastic Compute Cloud (Amazon EC2) C7g—the latest AWS Graviton3 instance family. On a single EKS cluster, we measured EMR runtime for Apache Spark performance by comparing C7g with C6g families across selected instance sizes of 4XL, 8XL and 12XL. We are excited to observe a maximum 19% performance gain over the 6th generation C6g Graviton2 instances, which leads to a 15% cost reduction.
In this post, we discuss the performance test results that we observed while running the same EMR Spark runtime on different Graviton-based EC2 instance types.
For some use cases, such as the benchmark test, running a data pipeline that requires a mix of CPU types for the granular-level cost efficiency, or migrating an existing application from Intel to Graviton-based instances, we usually spin up different clusters that host separate types of processors, such as x86_64 vs. arm64. However, Amazon EMR on EKS has made it easier. In this post, we also provide guidance on running Spark with multiple CPU architectures in a common EKS cluster, so that we can save significant time and effort on setting up a separate cluster to isolate the workloads.
Infrastructure innovation
AWS Graviton3 is the latest generation of AWS-designed Arm-based processors, and C7g is the first Graviton3 instance in AWS. The C family is designed for compute-intensive workloads, including batch processing, distributed analytics, data transformations, log analysis, and more. Additionally, C7g instances are the first in the cloud to feature DDR5 memory, which provides 50% higher memory bandwidth compared to DDR4 memory, to enable high-speed access to data in memory. All these innovations are well-suited for big data workloads, especially the in-memory processing framework Apache Spark.
The following table summarizes the technical specifications for the tested instance types:
| Instance Name | vCPUs | Memory (GiB) | EBS-Optimized Bandwidth (Gbps) | Network Bandwidth (Gbps) | On-Demand Hourly Rate |
| c6g.4xlarge | 16 | 32 | 4.75 | Up to 10 | $0.544 |
| c7g.4xlarge | 16 | 32 | Up to 10 | Up to 15 | $0.58 |
| c6g.8xlarge | 32 | 64 | 9 | 12 | $1.088 |
| c7g.8xlarge | 32 | 64 | 10 | 15 | $1.16 |
| c6g.12xlarge | 48 | 96 | 13.5 | 20 | $1.632 |
| c7g.12xlarge | 48 | 96 | 15 | 22.5 | $1.74 |
These instances are all built on AWS Nitro System, a collection of AWS-designed hardware and software innovations. The Nitro System offloads the CPU virtualization, storage, and networking functions to dedicated hardware and software, delivering performance that is nearly indistinguishable from bare metal. Especially, C7g instances have included support for Elastic Fabric Adapter (EFA), which becomes the standard on this instance family. It allows our applications to communicate directly with network interface cards providing lower and more consistent latency. Additionally, these are all Amazon EBS-optimized instances, and C7g provides higher dedicated bandwidth for EBS volumes, which can result in better I/O performance contributing to quicker read/write operations in Spark.
Performance test results
To quantify performance, we ran TPC-DS benchmark queries for Spark with a 3TB scale. These queries are derived from TPC-DS standard SQL scripts, and the test results are not comparable to other published TPC-DS benchmark outcomes. Apart from the benchmark standards, a single Amazon EMR 6.6 Spark runtime (compatible with Apache Spark version 3.2.0) was used as the data processing engine across six different managed node groups on an EKS cluster: C6g_4, C7g_4,C6g_8, C7g_8, C6g_12, C7g_12. These groups are named after instance type to distinguish the underlying compute resources. Each group can automatically scale between 1 and 30 nodes within its corresponding instance type. Architecting the EKS cluster in such a way, we can run and compare our experiments in parallel, each of which is hosted in a single node group, i.e., an isolated compute environment on a common EKS cluster. It also makes it possible to run an application with multiple CPU architectures on the single cluster. Check out the sample EKS cluster configuration and benchmark job examples for more details.
We measure the Graviton performance and cost improvements using two calculations: total query runtime and geometric mean of the total runtime. The following table shows the results for equivalent sized C6g and C7g instances and the same Spark configurations.
| Benchmark Attributes | 12 XL | 8 XL | 4 XL |
| Task parallelism (spark.executor.core*spark.executor.instances) | 188 cores (4*47) | 188 cores (4*47) | 188 cores (4*47) |
| spark.executor.memory | 6 GB | 6 GB | 6 GB |
| Number of EC2 instances | 5 | 7 | 16 |
| EBS volume | 4 * 128 GB io1 disk | 4 * 128 GB io1 disk | 4 * 128 GB io1 disk |
| Provisioned IOPS per volume | 6400 | 6400 | 6400 |
| Total query runtime on C6g (sec) | 2099 | 2098 | 2042 |
| Total query runtime on C7g (sec) | 1728 | 1738 | 1660 |
| Total run time improvement with C7g | 18% | 17% | 19% |
| Geometric mean query time on C6g (sec) | 9.74 | 9.88 | 9.77 |
| Geometric mean query time on C7g (sec) | 8.40 | 8.32 | 8.08 |
| Geometric mean improvement with C7g | 13.8% | 15.8% | 17.3% |
| EMR on EKS memory usage cost on C6g (per run) | $0.28 | $0.28 | $0.28 |
| EMR on EKS vCPU usage cost on C6g (per run) | $1.26 | $1.25 | $1.24 |
| Total cost per benchmark run on C6g (EC2 + EKS cluster + EMR price) | $6.36 | $6.02 | $6.52 |
| EMR on EKS memory usage cost on C7g (per run) | $0.23 | $0.23 | $0.22 |
| EMR on EKS vCPU usage cost on C7g (per run) | $1.04 | $1.03 | $0.99 |
| Total cost per benchmark run on C7g (EC2 + EKS cluster + EMR price) | $5.49 | $5.23 | $5.54 |
| Estimated cost reduction with C7g | 13.7% | 13.2% | 15% |
The total number of cores and memory are identical across all benchmarked instances, and four provisioned IOPS SSD disks were attached to each EBS-optimized instance for the optimal disk I/O performance. To allow for comparison, these configurations were intentionally chosen to match with settings in other EMR on EKS benchmarks. Check out the previous benchmark blog post Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads for C5 instances based on x86_64 Intel CPU.
The table indicates C7g instances have consistent performance improvement compared to equivalent C6g Graviton2 instances. Our test results showed 17–19% improvement in total query runtime for selected instance sizes, and 13.8–17.3% improvement in geometric mean. On cost, we observed 13.2–15% cost reduction on C7g performance tests compared to C6g while running the 104 TPC-DS benchmark queries.
Data shuffle in a Spark workload
Generally, big data frameworks schedule computation tasks for different nodes in parallel to achieve optimal performance. To proceed with its computation, a node must have the results of computations from upstream. This requires moving intermediate data from multiple servers to the nodes where data is required, which is termed as shuffling data. In many Spark workloads, data shuffle is an inevitable operation, so it plays an important role in performance assessments. This operation may involve a high rate of disk I/O, network data transmission, and could burn a significant amount of CPU cycles.
If your workload is I/O bound or bottlenecked by current data shuffle performance, one recommendation is to benchmark on improved hardware. Overall, C7g offers better EBS and network bandwidth compared to equivalent C6g instance types, which may help you optimize performance. Therefore, in the same benchmark test, we captured the following extra information, which is broken down into per-instance-type network/IO improvements.
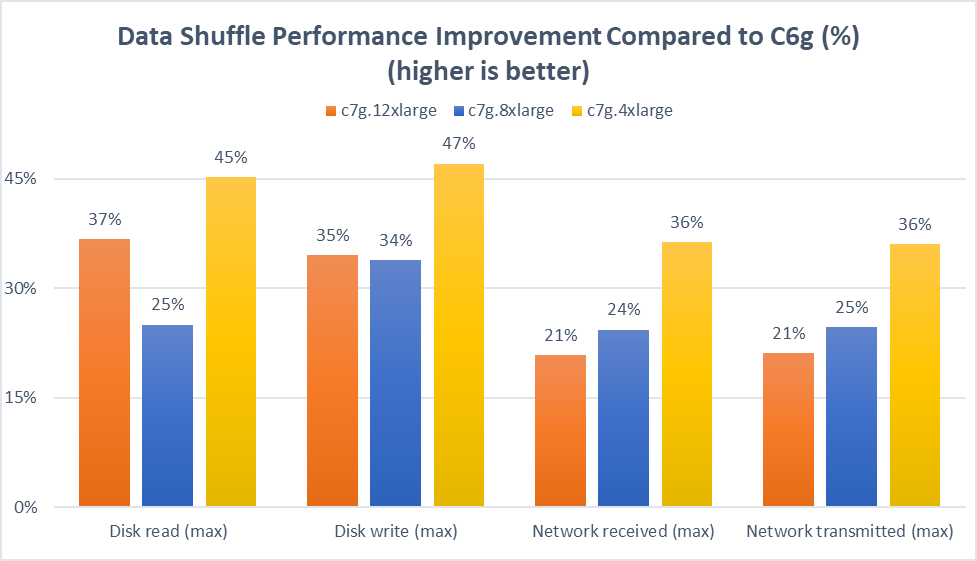
Based on the TPC-DS query test result, this graph illustrates the percentage increases of data shuffle operations in four categories: maximum disk read and write, and maximum network received and transmitted. In comparison to c6g instances, the disk read performance improved between 25–45%, whereas the disk write performance increase was 34–47%. On the network throughput comparison, we observed an increase of 21–36%.
Run an Amazon EMR on EKS job with multiple CPU architectures
If you’re evaluating migrating to Graviton instances for Amazon EMR on EKS workloads, we recommend testing the Spark workloads based on your real-world use cases. If you need to run workloads across multiple processor architectures, for example test the performance for Intel and Arm CPUs, follow the walkthrough in this section to get started with some concrete ideas.
Build a single multi-arch Docker image
To build a single multi-arch Docker image (x86_64 and arm64), complete the following steps:
- Get the Docker Buildx CLI extension.Docker Buildx is a CLI plugin that extends the Docker command to support the multi-architecture feature. Upgrade to the latest Docker desktop or manually download the CLI binary. For more details, check out Working with Buildx.
- Validate the version after the installation:
docker buildx version - Create a new builder that gives access to the new multi-architecture features (you only have to perform this task once):
docker buildx create --name mybuilder --use - Log in to your own Amazon ECR registry:
AWS_REGION=us-east-1 ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) ECR_URL=$ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com aws ecr get-login-password --region $AWS_REGION | docker login --username AWS --password-stdin $ECR_URL - Get the EMR Spark base image from AWS:
SRC_ECR_URL=755674844232.dkr.ecr.us-east-1.amazonaws.com docker pull $SRC_ECR_URL/spark/emr-6.6.0:latest aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin $SRC_ECR_URL - Build and push a custom Docker image.
In this case, we build a single Spark benchmark utility docker image on top of Amazon EMR 6.6. It supports both Intel and Arm processor architectures:
- linux/amd64 – x86_64 (also known as AMD64 or Intel 64)
- linux/arm64 – Arm
docker buildx build \
--platform linux/amd64,linux/arm64 \
-t $ECR_URL/eks-spark-benchmark:emr6.6 \
-f docker/benchmark-util/Dockerfile \
--build-arg SPARK_BASE_IMAGE=$SRC_ECR_URL/spark/emr-6.6.0:latest \
--push .Submit Amazon EMR on EKS jobs with and without Graviton
For our first example, we submit a benchmark job to the Graviton3 node group that spins up c7g.4xlarge instances.
The following is not a complete script. Check out the full version of the example on GitHub.
aws emr-containers start-job-run \
--virtual-cluster-id $VIRTUAL_CLUSTER_ID \
--name emr66-c7-4xl \
--execution-role-arn $EMR_ROLE_ARN \
--release-label emr-6.6.0-latest \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "local:///usr/lib/spark/examples/jars/eks-spark-benchmark-assembly-1.0.jar",
"entryPointArguments":[.......],
"sparkSubmitParameters": "........"}}' \
--configuration-overrides '{
"applicationConfiguration": [{
"classification": "spark-defaults",
"properties": {
"spark.kubernetes.container.image": "'$ECR_URL'/eks-spark-benchmark:emr6.6",
"spark.kubernetes.node.selector.eks.amazonaws.com/nodegroup": “C7g_4”
}}]}'In the following example, we run the same job on non-Graviton C5 instances with Intel 64 CPU. The full version of the script is available on GitHub.
aws emr-containers start-job-run \
--virtual-cluster-id $VIRTUAL_CLUSTER_ID \
--name emr66-c5-4xl \
--execution-role-arn $EMR_ROLE_ARN \
--release-label emr-6.6.0-latest \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "local:///usr/lib/spark/examples/jars/eks-spark-benchmark-assembly-1.0.jar",
"entryPointArguments":[.......],
"sparkSubmitParameters": "........"}}' \
--configuration-overrides '{
"applicationConfiguration": [{
"classification": "spark-defaults",
"properties": {
"spark.kubernetes.container.image": "'$ECR_URL'/eks-spark-benchmark:emr6.6",
"spark.kubernetes.node.selector.eks.amazonaws.com/nodegroup”: “C5_4”
}}]}'Summary
In May 2022, the Graviton3 instance family was made available to Amazon EMR on EKS. After running the performance-optimized EMR Spark runtime on the selected latest Arm-based Graviton3 instances, we observed up to 19% performance increase and up to 15% cost savings compared to C6g Graviton2 instances. Because Amazon EMR on EKS offers 100% API compatibility with open-source Apache Spark, you can quickly step into the evaluation process with no application changes.
If you’re wondering how much performance gain you can achieve with your use case, try out the benchmark solution or the EMR on EKS Workshop. You can also contact your AWS Solutions Architects, who can be of assistance alongside your innovation journey.
About the author
Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.