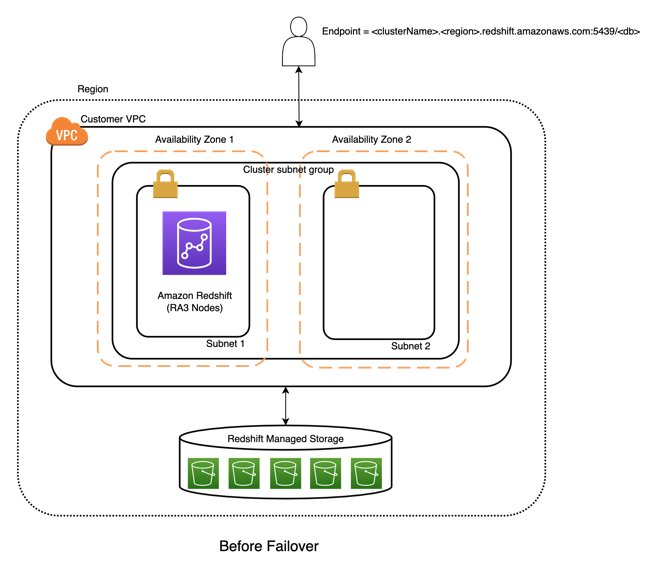
Amazon Redshift provides resiliency in the event of a single point of failure in a cluster, including automatically detecting and recovering from drive and node failures. The Amazon Redshift relocation feature adds an additional level of availability, and this post is focused on explaining this automatic recovery feature.
When the cluster relocation feature is enabled on an RA3 cluster, Amazon Redshift automatically relocates the cluster in situations where issues at the Availability Zone level prevent optimal cluster operation, or in case of large-scale failures impacting cluster resources in a data center within an Availability Zone. Relocation is done by creating the cluster’s compute resources in another Availability Zone. After a cluster is relocated to another Availability Zone, there is no loss of data and no application changes are required because the cluster endpoint doesn’t change. This provides a resilient architecture to maintain application availability. When a failover is initiated, the actual time to recover is dependent on the size of a cluster, with the average time under 15 minutes. Note that the ability to relocate is subject to capacity availability. Cluster relocation is offered at no charge.
The cluster relocation feature also helps you build a demonstratable Availability Zone recovery plan as well as address capacity shortages while expanding resources in a given Availability Zone. You can manually move the cluster to another Availability Zone to test your disaster recovery plan. In cases where a cluster can’t be resized or resumed due to capacity shortages in an Availability Zone, you can relocate the cluster to an Availability Zone with more capacity. If the relocation isn’t successful, the existing cluster is left unchanged. The existing cluster isn’t removed until the new cluster is successfully created as part of this process.
Solution overview
Amazon Redshift customers with operationally sensitive applications require application resiliency in the event of an outage in an Availability Zone. The Amazon Redshift relocation feature provides application resiliency through an easy-to-use architecture with zero loss of data and no application modifications.
In this post, we demonstrate how to enable cluster relocation using either the AWS Management Console or AWS Command Line Interface (AWS CLI). We walk through examples of automatic and manual relocation, also show how to create a custom relocation solution using additional AWS services.
Prerequisites
Make sure you have the following prerequisites:
- An AWS account.
- Amazon Redshift clusters created in a VPC with a minimum of two subnets each in different Availability Zone.
- An Amazon Redshift cluster with multiple Availability Zones configured in the cluster subnet group. You can set one up using the following AWS CloudFormation template.
- The relocation feature is possible only with the RA3 Amazon Redshift node type.
- In the Network and security settings section, choose Disable for the Publicly accessible option.

Enable cluster relocation
The first step is to enable cluster relocation, either via the console or AWS CLI. For more information, see Managing cluster relocation in Amazon Redshift. When using cluster relocation, be aware of the limitations.
Enable cluster relocation using the console
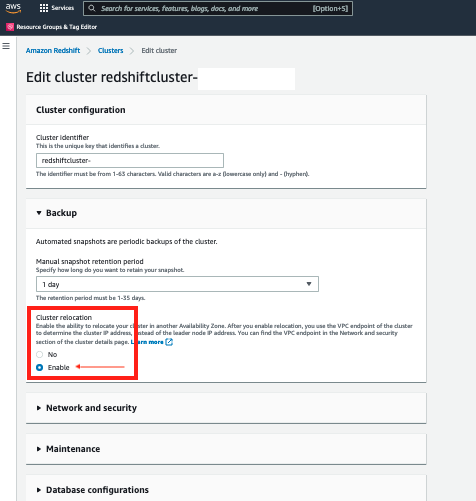
To enable cluster relocation on the console, complete the following steps:
- On the Amazon Redshift console, choose Clusters.
- Edit your cluster.
- Under Backup, for Cluster relocation, select Enable.
Enable cluster relocation using the AWS CLI
The relocation feature requires port 5439. If your current cluster is using a different port, you must modify it to use 5439 before modifying it to enable relocation. The following command modifies the port in case your cluster doesn’t use 5439:
aws redshift modify-cluster --cluster-identifier mycluster --port 5439The following command enables the availability-zone-relocation parameter on the Amazon Redshift cluster:
aws redshift modify-cluster --cluster-identifier mycluster --availability-zone-relocationThe following command disables the availability-zone-relocation parameter on the Amazon Redshift cluster:
aws redshift modify-cluster --cluster-identifier mycluster --no-availability-zone-relocationAutomatic Availability Zone relocation
When using relocation in Amazon Redshift, you enable Amazon Redshift to move a cluster to another Availability Zone without any loss of data or changes to your applications. With relocation, you can resume operations when there is an interruption of service on your cluster with minimal impact. The new cluster will have the same endpoint so that applications can continue operations without modification.
This feature doesn’t require any action from the user besides the one-time configuration to enable the relocation feature. When the recovery feature is activated, the destination Availability Zone used is defined in the cluster subnet group.
Manual Availability Zone relocation
You can trigger the relocation manually, relocating a cluster to another Availability Zone. Complete the following steps:
- On the Amazon Redshift console, choose Clusters in the navigation pane.The clusters for your account in the current Region are listed. A subset of properties of each cluster is displayed in columns in the list.
- Choose the cluster you want to relocate.
- On the Actions menu, choose Relocate.If the Relocate option is greyed out, that indicates the cluster isn’t configured to use the Availability Zone relocation feature, or the cluster doesn’t meet the requirements for the relocation feature. For more details, refer to

After relocation is initiated, Amazon Redshift starts the relocation and displays the cluster status as Relocating. When the relocation complete, the cluster status changes to Available.

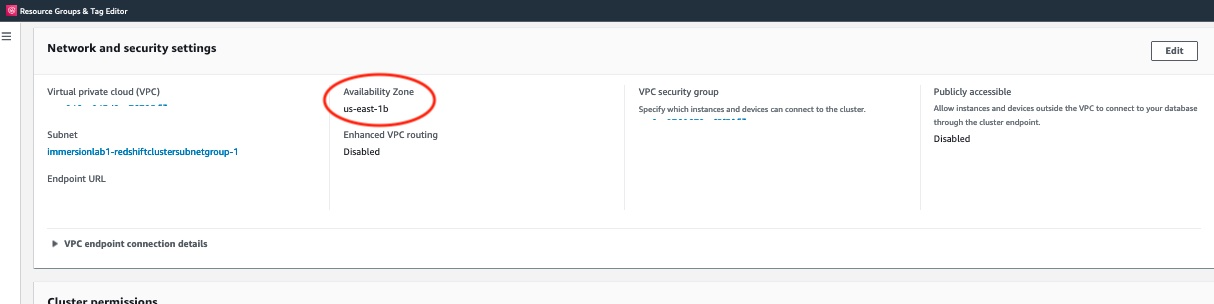
The following screenshot confirms the cluster has relocated to the correct Availability Zone.
Custom Availability Zone relocation solution
In this section, we simulate an automatic cluster failover to another Availability Zone with a reboot. Our event-based relocation solution involves setting up an alarm with an Amazon Simple Notification Service (Amazon SNS) topic, and creating an AWS Lambda function to trigger the relocation.
Create an alarm
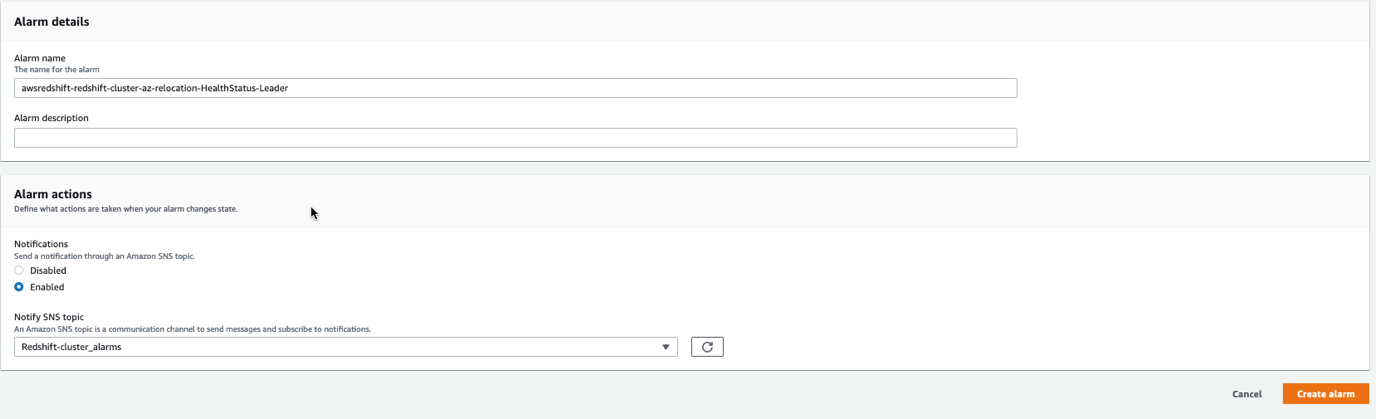
To set up the alarm, complete the following steps:
- On the Amazon Redshift console, choose Clusters in the navigation pane.
- Choose your cluster.
- On the Cluster performance tab, expand the Alarms section and choose Create alarm.
- Configure the alarm for the HealthStatus metric and provide an alarm name and description.

- In the Alarm actions section, for Notifications¸ select Enabled.
- For Notify SNS topic, choose an existing SNS topic or create a new one.This topic receives a notification if the leader node isn’t healthy or is unavailable.
- Choose Create alarm.
Create a Lambda function
To set up a Lambda function to trigger Availability Zone relocation in case of cluster failure, complete the following steps:
- On the Lambda console, in the navigation pane, choose Functions.
- Open the Lambda function created by the CloudFormation stack.
- Edit the function code and modify the following snippet, updating the cluster ID and the destination Availability Zone:
run_command('/opt/aws redshift modify-cluster --cluster-identifier redshift-cluster-az-relocation --availability-zone us-east-1d')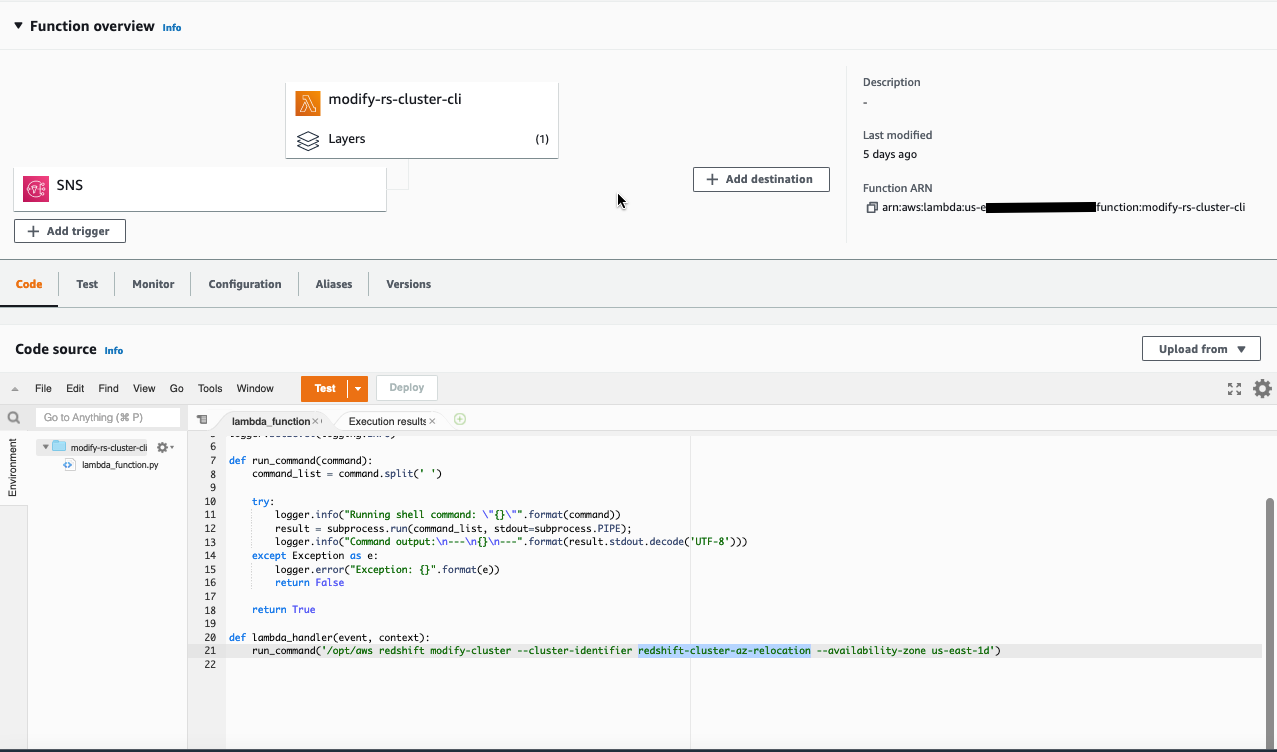
- Choose Add trigger.
- Under Trigger configuration, choose SNS.
- For SNS topic, choose the topic you specified for your alarm.
- Choose Add.

Test the Availability Zone relocation feature
Now we can test our custom Availability Zone relocation solution.
- On the Amazon Redshift console, choose Clusters in the navigation pane.
- Choose the cluster that you want to relocate.
- On the cluster detail page, note the cluster identifier.
- Use AWS CloudShell to run the following AWS CLI command to find the current Availability Zone of the Amazon Redshift cluster:
aws redshift describe-clusters --cluster-identifier redshift-cluster-az-relocation - From the JSON output, look for the attribute
AvailabilityZone. - On the cluster detail page, on the Actions menu, choose Reboot.
- Choose Reboot cluster.
This triggers the alarm, and changes the alarm state to ALARM.

Amazon SNS receives a message and triggers the Lambda function to perform the cluster relocation to the Availability Zone configured in the code. The cluster relocation takes several minutes.
- In CloudShell, run the following AWS CLI command to find the modified Availability Zone of the cluster:
aws redshift describe-clusters --cluster-identifier redshift-cluster-az-relocation

Benefits
The cluster relocation feature provides the following benefits:
- You can recover your cluster to another Availability Zone where failover can be done in minutes to ensure business continuity and high availability (HA). In addition, Availability Zones are physically separated resources that allow you to create a configuration for HA.
- Amazon Redshift cluster recovery is a one-step process that may also be automated, as opposed to the manual process required to restore a cluster from a snapshot.
- Because Amazon Redshift managed storage already includes the ability to replicate to two other Availability Zones using Amazon Simple Storage Service (Amazon S3), the cost of the additional copies is covered. There are no additional charges to use this feature.
- The cluster relocation capability allows you to support business-critical use cases on your data warehouse requiring HA capabilities. This reduces the chance of an outage impacting your business operations.
- You can benefit from automatic recovery to a failover Availability Zone when there are issues in optimal performance.
- Relocation is provided free of charge and is subject to capacity availability.
Conclusion
In this post, we walked you through how the automated Availability Zone recovery feature in Amazon Redshift helps you build a resilient modern data architecture. The post also described how to perform a manual relocation through the AWS management console. Lastly, we discussed how to implement an event-based relocation using Amazon SNS and Lambda. These various techniques can help you plan your failover strategies based on your business needs.
About the authors
 Kevin Burandt is a Senior Manager, Solutions Architecture at AWS. He is passionate about building and leading technical teams that help customers and partners use technology to achieve business outcomes and deliver value to their customers. Outside of work, he enjoys home renovation projects and working on classic cars.
Kevin Burandt is a Senior Manager, Solutions Architecture at AWS. He is passionate about building and leading technical teams that help customers and partners use technology to achieve business outcomes and deliver value to their customers. Outside of work, he enjoys home renovation projects and working on classic cars.
 Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.
Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.
 Ramkumar Nottath is a Sr. Solutions Architect at AWS focusing on Analytics services. He enjoys working with various customers to help them build scalable, reliable big data and analytics solutions. His interests extend to various technologies such as analytics, data warehousing, streaming, and machine learning. He loves spending time with his family and friends.
Ramkumar Nottath is a Sr. Solutions Architect at AWS focusing on Analytics services. He enjoys working with various customers to help them build scalable, reliable big data and analytics solutions. His interests extend to various technologies such as analytics, data warehousing, streaming, and machine learning. He loves spending time with his family and friends.
 Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 13 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 13 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.