This is a guest post co-written by Sergei Dubinin, Oleksandr Ierenkov, Illia Popov and Joel Thompson, from Bridgewater.
Bridgewater’s core mission is to understand how the world works by analyzing the drivers of markets and turning that understanding into high-quality portfolios and investment advice for our clients. Within Bridgewater Technology, we strive to make our researchers as productive as possible at what they do best: building the fundamental understanding of global markets. This means eliminating the need to deal with underlying IT infrastructure, and focusing on building and improving their investment ideas.
In this post, we examine our proprietary service in four dimensions. We talk about our business challenges, how we met our high security bar, how we can scale to meet the demands of the business, and how we do all of this in a cost-effective manner.
Challenge
Our researchers’ demand for compute required to develop and test their investment logic is constantly growing. This consistent and aggressive growth in compute capacity was a driving force behind our initial decision to move to the public cloud.
Utilizing the scale of the AWS Cloud has allowed us to generate investment signals and views of the world that would have been impossible to do on premises. When we first moved this analytical workload to AWS, we built on Amazon Elastic Compute Cloud (Amazon EC2) along with other services such as Elastic Load Balancing, AWS Auto Scaling, and Amazon Simple Storage Service (Amazon S3) to provide core functionality. A short time later, we moved to the AWS Nitro System, completing jobs 20% faster—allowing our research teams to iterate more quickly on their investment ideas.
The next step in our evolution started 2 years ago when we adopted Apache Spark as the underlying compute engine for our investment logic execution service. This helped streamline our analytics pipeline, removing duplication and decoupling many of the plugins we were developing for our researchers. Rather than run Apache Spark ourselves, we chose Amazon EMR as a hosted Spark platform. However, we soon discovered that Amazon EMR on EC2 wasn’t a good fit for the way we wanted to use it. For example, we can’t predict when a researcher will submit a job, so to avoid having our researchers wait for a brand new EMR cluster to be created and bootstrapped, we used long-lived EMR clusters, which forced many different jobs to run on the same cluster. However, because a single EMR cluster can only exist in a single Availability Zone, our cluster was limited to only being able to launch instances in that Availability Zone. At the significant scale that we were operating at, individual Availability Zones started running out of our desired instance capacity to meet our needs. Although we could launch many different clusters across different Availability Zones, that would leave us handling job scheduling at a high level, which was the whole point of using Amazon EMR and Spark. Furthermore, to be as cost-efficient as possible, we wanted to continuously scale the number of nodes in the cluster based on demand, and as a result, we would churn through thousands of nodes a day. This constant churning of nodes caused job failures and additional operational overhead for our teams.
We brought these concerns to AWS, who took the lead in pushing these issues to resolution. AWS partnered closely with us to understand our use cases and the impact of job failures, and tirelessly worked with us to solve these challenges. Working with the Amazon EMR team, we narrowed down the problem to our aggressive scaling patterns, which the service could not handle at that time. Over the course of just a few months, the Amazon EMR team made several service improvements in the scaling mechanism to meet our needs and the needs of many other AWS customers.
While working closely with the Amazon EMR team on these issues, the AWS team informed us of the development of Amazon EMR on EKS, a managed service that would enable us to run Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS). Amazon EKS is a strategic platform for us across various business units at Bridgewater, and after doing a proof of concept of our workload using EMR on EKS, it became clear that this was a better fit for our use case and more aligned with our strategic direction. After migrating to EMR on EKS, we can now take advantage of capacity in multiple Availability Zones and improve our resiliency to EMR cluster issues or broader service events, while still meeting our high security bar.
Security
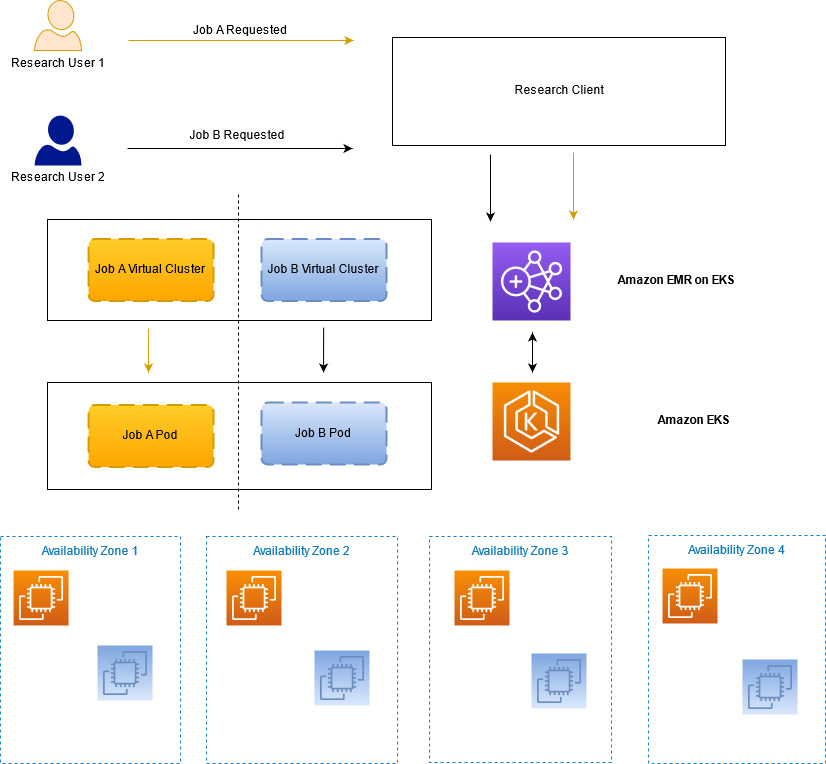
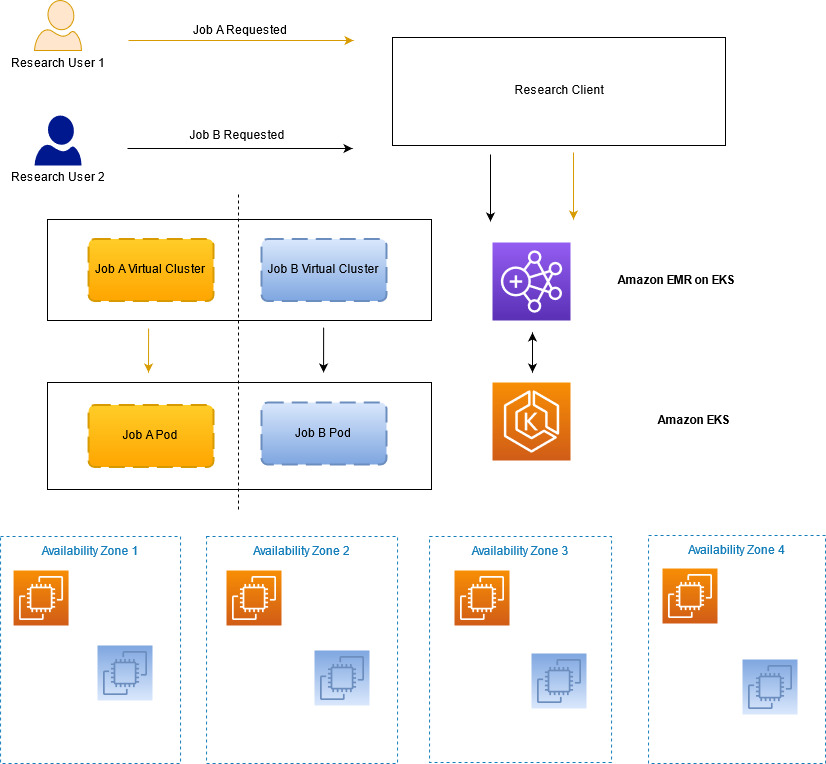
Another important aspect of our service is ensuring it maintains the appropriate security posture. Among other concerns, Bridgewater strictly compartmentalizes access to different investment ideas, and we must defend against the possibility of a malicious insider attempting to steal our intellectual property or otherwise harm Bridgewater. To balance the trade-offs between speed and security, we designed security controls to defend against potentially malicious jobs, while enabling our researchers to quickly iterate on their code. This is made more complicated by the design of Spark’s Kubernetes backend. The Spark driver, which in our case is running arbitrary and untrusted code, has to be given Kubernetes role-based access control (RBAC) permissions to create Kubernetes Pods. The ability to create Pods is very powerful and can lead to privilege escalation.
Our first layer of isolation is to run each job in its own Kubernetes namespace (and, therefore, in its own EMR on EKS virtual cluster). A namespace and virtual cluster are created when the job is ready to be submitted, and they’re deleted when that job is finished. This prevents one job from interfering directly with another job, but there are still other vectors to defend against. For example, Spark drivers should not be creating Pods with containers that run as root or source their images from unapproved repositories. We first investigated PodSecurityPolicies for this purpose. However, they couldn’t solve all of our use cases (such as restricting where container images can be pulled from), and they are currently being deprecated and will eventually be removed. Instead, we turned to Open Policy Agent (OPA) Gatekeeper, which provides a flexible approach for writing policies in code that can do more complex authorization decisions and allows us to implement our desired suite of controls. We also worked with the AWS Service Team to add further defense in depth, such as ensuring that all Pods created by EMR on EKS dropped all Linux capabilities, which we could then enforce with Gatekeeper.
The following diagram illustrates how we can maintain the required job separation within our research service.
Scaling
One of the largest motivations of our evolution to Spark on Amazon EMR and then on EMR on EKS was improving the efficiency of our resource utilization by aggressively scaling based on demand. Our fundamental cause-and-effect understanding of markets and economies is powered by our systematic, high-performance compute Spark grid. We run simulations at a constantly increasing scale and need an architecture that can scale up and meet our foreseeable business needs for the next several years.
Our platform runs two types of jobs: ad hoc interactive and scheduled batch. Each type of job brings its own scaling complexities, and both benefited from the evolution to EMR on EKS. Ad hoc jobs can be submitted at any time throughout business hours, and the simulation determines how much compute capacity is needed. For example, a particular job may need one EC2 instance or 100 EC2 instances. This can translate to hundreds of EC2 instances needing to be spun up or down within a few minutes. The scheduled batch jobs run periodically throughout the day with predetermined simulations and similarly translates to hundreds of EC2 instances spinning up or down. In total, scaling up and down by many hundreds of EC2 instances in a few minutes is common, and we needed a solution that could meet those business requirements.
For this specific problem, we needed a solution that was able to handle aggressive scaling events on the order of hundreds of EC2 instances per minute. Additionally, when operating at this scale, it’s important to both diversify instance types and spread jobs across Availability Zones. EMR on EKS empowers us to run fully-managed Spark jobs on an EKS cluster that spans multiple Availability Zones and provides the option to choose a heterogeneous set of instance types for Amazon EKS. Spanning a single EKS cluster across Availability Zones enables us to utilize compute capacity across the entire Region, thereby increasing instance diversity and availability for this workload. Because Spark jobs are running within containers on Amazon EKS, we can easily swap out instance types within the EKS cluster or run different instance types within the same cluster. As a result of these capabilities, we’re able to regularly scale our production service to approximately 1,600 EC2 instances totaling 25,000 cores at peak, running 3,000 jobs per day.
Finally, in late 2021, we conducted some scaling tests to see what the realistic limits of our service are. We are happy to share that we were able to scale our service to three times our normal daily size in terms of compute and simulations run. This exercise has validated that we will be able to meet the increase in business demand without committing additional engineering resources to do so.
Cost management
In addition to significantly increasing our ability to scale, we also were able to design the solution to be extremely cost effective. Prior to EMR on EKS, we had two options for Spark jobs: either self-managed on Amazon EC2 or using Amazon EMR on EC2. Self-managing on Amazon EC2 meant that we needed to manage the complexities of scheduling jobs on nodes, manage the Spark clusters themselves, and develop a separate application to provision and stop EC2 instances as Spark jobs ran to scale the workloads. Amazon EMR on EC2 provides a managed service to run Spark workloads on Amazon EC2. However, for customers like us who need to operate in multiple Availability Zones and already have a technology footprint on Kubernetes, EMR on EKS made more sense.
Moving to EMR on EKS enables us to scale dynamically as jobs are submitted, generating huge cost savings. Simulation capacity is right-sized within the range of a few minutes; something that is not possible with another solution. Additionally, our investment in Amazon EC2 Compute Savings Plans provides us with the savings and flexibility to meet our needs; we just need to specify how many compute hours we’re committed to in a particular Region and AWS handles the rest. You can read more about the cost benefits of EMR on EKS in Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads.
The future
Although we’re currently meeting our key users’ needs, we have prioritized several improvements to our service for the future. First, we plan on replacing the Kubernetes Cluster Autoscaler with Karpenter. Given our aggressive and frequent compute scaling, we have found that some jobs can be unexpectedly stopped using the Cluster Autoscaler. We experience this about six times a day. We expect Karpenter will greatly diminish the occurrence of this failure mode. To learn more about Karpenter, check out Introducing Karpenter – An Open-Source High-Performance Kubernetes Cluster Autoscaler.
Second, we’re moving several complementary services that are currently running on EC2 to EKS. This will increase our ability to deploy meaningful improvements for our business and increase resiliency to service events.
Finally, we are making longer term efforts to improve our resiliency to regional service events. We are exploring broadening our operations to other AWS Regions, which would allow us to increase our service availability as well as maintain our burst capacity.
Conclusion
Working closely with AWS teams, we were able to develop a scalable, secure, and cost-optimized service on AWS that allows our researchers to generate larger and more complex investment ideas without worrying about IT infrastructure. Our service runs our Spark-based simulations across multiple Availability Zones at near-full utilization without having to worry about building or maintaining a scheduling platform. Finally, we are able to meet and surpass our security benchmarks by creating job separation using native AWS constructs at scale. This has given us tremendous confidence that our mission-critical data is safe in the AWS Cloud.
Through this close partnership with AWS, Bridgewater is poised to anticipate and meet the rigorous demands of our researchers for years to come; something that was not possible in our old data centers or with our prior architecture. Our President and CTO, Igor Tsyganskiy, recently spoke with AWS at length on this partnership. For the video of this discussion, check out Merging Business and Tech – Bridgewater’s Guide to Drive Agility.
Acknowledgements
- Igor Tsyganskiy, President and Chief Technology Officer, Bridgewater
- Aaron Linsky, Sr. Product Manager, Bridgewater
- Gopinathan Kannan, Sr. Mgr. Engineering, Amazon Web Services
- Vaibhav Sabharwal, Sr. Customer Solutions Manager, Amazon Web Services
- Joseph Marques, Senior Principal Engineer, Amazon Web Services
- David Brown, VP EC2, Amazon Web Services
About the authors
Sergei Dubinin is an Engineering Manager with Bridgewater. He is passionate about building big data processing systems that are suitable for a secure, stable, and performant use in production.
Oleksandr Ierenkov is a Solution Architect for EPAM Systems. He has focused on helping Bridgewater migrate in-house distributed systems to microservices on Kubernetes and various AWS-managed services with a focus on operational efficiency. Oleksandr is basically the same name as Alexander, only Ukrainian.
Anthony Pasquariello is a Senior Solutions Architect at AWS based in New York City. He specializes in modernization and security for our advanced enterprise customers. Anthony enjoys writing and speaking about all things cloud. He’s pursuing an MBA, and received his MS and BS in Electrical & Computer Engineering.
Illia Popov is a Tech Lead for EPAM Systems. Illia has been working with Bridgewater since 2018 and was active in planning and implementing the migration to EMR on EKS. He is excited to continue delivering value to Bridgewater by adapting managed services in close cooperation with AWS.
Peter Sideris is a Sr. Technical Account Manager at AWS. He works with some of our largest and most complex customers to ensure their success in the AWS Cloud. Peter enjoys his family, marine reef keeping, and volunteers his time to the Boy Scouts of America in several capacities.
Joel Thompson is an Architect at Bridgewater Associates, where he has worked in a variety of technology roles over the past 13 years, including building some of the earliest foundations of AWS adoption at Bridgewater. He is passionate about solving complicated problems to securely deliver value to the business. Outside of work, Joel is an avid skier, helped co-found the fwd:cloudsec cloud security conference, and enjoys traveling to spend time with friends and family.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.