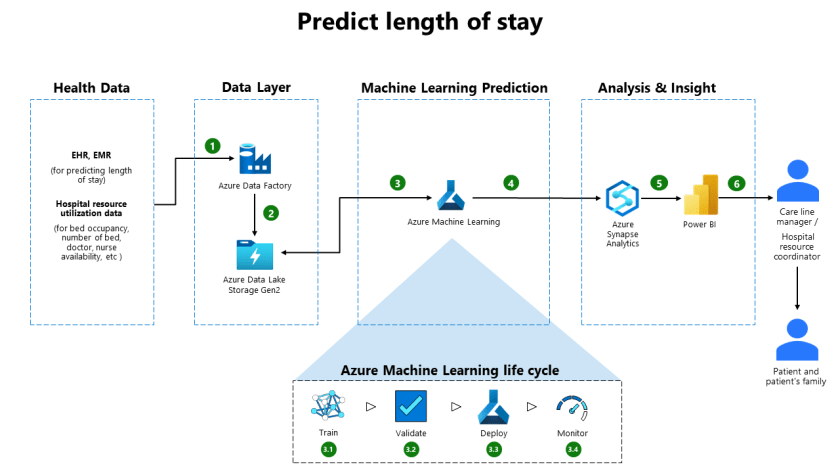
For the people running a healthcare facility, length of stay (LOS)—the number of days from patient admission to discharge—matters. However, that number can vary across facilities and across disease conditions and specialties, even within the same healthcare system, making it hard to track patient flow and plan accordingly.
This Azure solution helps hospital administrators use the power of machine learning to predict the length of stay for in-hospital admissions, to improve capacity planning and resource utilization. A chief medical information officer might use a predictive model to determine which facilities are overtaxed and which resources to bolster within those facilities. A care line manager might use a model to determine whether there are adequate staff resources to handle the release of a patient.
Architecture

Download a PowerPoint file of this architecture.
Dataflow
The following dataflow corresponds to the above diagram:
- Anonymized health data from electronic health records (EHR) and electronic medical records (EMR) is extracted using Azure Data Factory with the appropriate runtime (for example: Azure, Self-hosted). In this scenario, we assume anonymized data is accessible for batch extraction using one of the Azure Data Factory connectors, such as ODBC, Oracle, SQL. Other data sources such as FHIR data, may require the inclusion of an intermediary ingestion service like Azure Functions.
- Azure Data Factory data flows through the Data Factory into Azure Data Lake Storage (gen 2). No data is stored in Azure Data Factory during this process, and failures like dropped connections can be handled/retried during this step.
- Azure Machine Learning is used to apply machine learning algorithms/pipelines to the data ingested in step 2. The algorithms can be applied on an event-basis, scheduled, or manually depending on the requirements. Specifically, this includes:
3.1 Train – The ingested data is used to train a machine learning model using a combination of algorithms such as Linear regression and Gradient Boosted Decision Tree. These algorithms are provided via various frameworks (for example, scikit-learn) typically in a pipeline, and may include pre/post-processing pipeline steps. As an example, patient health factors such as admission-type coming from the existing pre-processed (for example, drop null rows) EMR/EHR data could be used to train a regression model like Linear Regression. The model would then be capable of predicting a new patient length of stay.
3.2 Validate – The model performance is compared to existing models/test data, and also against any downstream consumption targets such as Application Programming Interfaces (APIs).
3.3 Deploy – The model is packaged using a container for use in different target environments.
3.4 Monitor – The model predictions are collected and monitored to ensure performance doesn’t degrade over time. Alerts can be sent to trigger manual or automated retraining/updates to the model as needed using this monitoring data. Note that additional services like Azure Monitor may be needed, depending on the type of monitoring data extracted.
- Azure Machine Learning output flows to Azure Synapse Analytics. The model output (predicted patient length of stay) is combined with the existing patient data in a scalable, serving layer like dedicated SQL pool for downstream consumption. Additional analytics such as average length of stay per hospital can be done via Synapse Analytics at this point.
- Azure Synapse Analytics provides data to Power BI. Specifically, Power BI connects to the serving layer in step (4) to extract the data and apply additional semantic modeling needed.
- Power BI is used for analysis by the care line manager and hospital resource coordinator.
Components
- Azure Data Factory (ADF) provides fully managed, serverless data integration and orchestration service capable of visually integrating data sources with more than 90+ built-in, maintenance-free connectors at no added cost. In this scenario ADF is used to ingest data and orchestrate the data flows.
- Azure Data Lake (ADLS) provides a scalable secure data lake for high-performance analytics. In this scenario ADLS is used as a scalable, cost-effective data storage layer.
- Azure Machine Learning (AML) services accelerate the end-to-end LOS prediction machine learning lifecycle by:
- Empowering data scientists and developers with a wide range of productive experiences to build, train, and deploy machine learning models and foster team collaboration.
- Accelerating time to market with industry-leading MLOps—machine learning operations, or DevOps for machine learning.
- Innovating on a secure, trusted platform, designed for responsible machine learning.
In this scenario, AML is the service used to produce the model used to predict patient length of stay, and to manage the end-to-end model lifecycle.
- Azure Synapse Analytics: a limitless analytics service that brings together data integration, enterprise data warehousing and big data analytics. In this scenario, Synapse is used to incorporate the model predictions into the existing data model and also to provide a high-speed serving layer for downstream consumption.
- Power BI provides self-service analytics at enterprise scale, allowing you to:
- Create a data-driven culture with business intelligence for all.
- Keep your data secure with industry-leading data security capabilities including sensitivity labeling, end-to-end encryption, and real-time access monitoring.
In this scenario, Power BI is used to create end-user dashboards and apply any semantic modeling needed in those dashboards.
Alternatives
- Spark services such as Azure Synapse Analytics Spark and Azure Databricks can be used as an alternative to perform the machine learning, depending on the data scale and skill set of the data science team.
- MLFlow can be used to manage the end-to-end lifecycle as an alternative to Azure Machine Learning depending on the customer skillset/environment.
- Azure Synapse Analytics pipelines can be used as an alternative to Azure Data Factory in most cases, depending largely on the specific customer environment.
Scenario details
This solution enables a predictive model for LOS for in-hospital admissions. LOS is defined in number of days from the initial admit date to the date that the patient is discharged from any given hospital facility. There can be significant variation of LOS across various facilities, disease conditions, and specialties, even within the same healthcare system.
Studies such as Is patient length of stay related to quality of care? have shown that a longer risk-adjusted LOS is correlated with lower received quality of care. Advanced LOS prediction at the time of admission can enhance patient quality of care, by giving providers an expected LOS which they can use as a metric to compare against current patient LOS. This can help to ensure patients with longer than expected LOS receive appropriate attention. LOS prediction also helps with accurate planning for discharges resulting in lowering of various other quality measures such as readmissions.
Potential use cases
There are two different business users in hospital management who can expect to benefit from more reliable predictions of the length of stay, as well as the patients’ families:
- The chief medical information officer (CMIO), who straddles the divide between informatics/technology and healthcare professionals in a healthcare organization. Their duties typically include using analytics to determine if resources are being allocated appropriately in a hospital network. The CMIO needs to be able to determine which facilities are being overtaxed, and specifically what resources at those facilities may need to be bolstered to realign such resources with demand.
- The care line manager, who is directly involved with the care of patients. This role requires monitoring the status of individual patients and ensuring that staff is available to meet the specific care requirements of their patients. The care line manager can make accurate medical decisions and align the right resources well in advance. For example, the ability to predict LOS:
- as an initial assessment of patients’ risk is critical for better resource planning and allocation, especially when the resources are limited, as in ICUs.
- enables care line managers to determine if staff resources will be adequate to handle the release of a patient.
- Predicting the LOS in ICU is also beneficial for patients and their families, as well as insurance companies. An expected date for discharge from the hospital helps patients and their families understand and estimate medical costs. This also gives families an idea about a patient’s speed of recovery, and helps them plan for discharge and manage their budgets.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Cost optimization
Cost optimization is about looking at ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Overview of the cost optimization pillar.
The most expensive component of this solution is the compute and there are several ways to scale the compute cost-effectively with data volume. One example would be to use a Spark service like Azure Synapse Analytics Spark or Azure Databricks for the data engineering work, as opposed to a single node solution. Spark scales horizontally and is more cost-effective compared to large, vertically scaled single node solutions.
The pricing for all Azure components as configured in this architecture can be found in this Azure Pricing Calculator saved estimate. This estimate is configured to show the estimated upfront and monthly costs, for a basic implementation that runs 9am-5pm Monday through Friday.
Operational excellence
Operational excellence covers the operations processes that deploy an application and keep it running in production. For more information, see Overview of the operational excellence pillar.
A solid Machine Learning operations (MLOps) practice and implementation plays a critical role in the productionalization this type of a solution. For more information, see Machine learning operations (MLOps).
Performance efficiency
Performance efficiency is the ability of your workload to scale to meet the demands placed on it by users in an efficient manner. For more information, see Performance efficiency pillar overview.
In this scenario, data pre-processing is performed in Azure Machine Learning. While this design will work for small to medium data volumes, large data volumes or scenarios with near real-time SLAs may struggle from a performance standpoint. One way to address this type of concern is to use a Spark service like Azure Synapse Analytics Spark or Azure Databricks for data engineering or data science workloads. Spark scales horizontally and is distributed by design, allowing it to process large datasets very effectively.
Security
Security provides assurances against deliberate attacks and the abuse of your valuable data and systems. For more information, see Overview of the security pillar.
Important
This architecture will work with both anonymized and non-anonymized health data. However, for the sake of a secure implementation, we recommend that health data is sourced in anonyized form from EHR and EMR sources.
For more information on security and governance features available for Azure Machine Learning, see Enterprise security and governance for Azure Machine Learning
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
Technologies and resources that are related to implementing this architecture:
See additional Azure Architecture Center content that’s related to this architecture:
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.