Amazon OpenSearch Service is a managed service that makes it easy to deploy, operate, and scale OpenSearch clusters in AWS to perform interactive log analytics, real-time application monitoring, website search, and more. OpenSearch is an open source, distributed search and analytics suite.
When working with OpenSearch Service, shard strategy is key. Shards distribute your workload across the data nodes of your cluster. When creating an index, you tell OpenSearch Service how many primary shards to create and how many replicas to create of each shard. The primary shards are independent partitions of the full dataset. OpenSearch Service automatically distributes your data across the primary shards in an index. Our recommendation is to use two replicas for your index. For example, if you set your index’s shard count to three primary shards and two replicas, you will have a total of nine shards. Properly configured indexes can help boost overall domain performance, whereas a misconfigured index will lead to storage and performance skew.
OpenSearch Service distributes the shards in your indexes to the data nodes in your domain, ensuring that no primary shard and its replicas are placed on the same node. The data for the shards are stored in the node’s storage. If your indexes (and therefore their shards) are very different sizes, the storage used on the data nodes in the domain will be unequal, or skewed. Storage skew leads to uneven memory and CPU utilization, intermittent and uneven latency, and uneven queueing and rejecting of requests. Therefore, it’s important to configure and maintain indexes such that shards can be distributed evenly across the data nodes of your cluster.
In this post, we explore how to deploy Amazon CloudWatch metrics using an AWS CloudFormation template to monitor an OpenSearch Service domain’s storage and shard skew. This solution uses an AWS Lambda function to extract storage and shard distribution metadata from your OpenSearch Service domain, calculates the level of skew, and then pushes this information to CloudWatch metrics so that you can easily monitor, alert, and respond.
Solution overview
The solution and associated resources are available for you to deploy into your own AWS account as a CloudFormation template. The template deploys the following resources:
- An AWS Identity and Access Management (IAM) role for the Lambda function called
OpensearchSkewMetricsLambdaRole. This allows write access to CloudWatch metrics and access to the CloudWatch log group and OpenSearch APIs. - An AWS Lambda function called
Opensearch-SkewMetricsPublisher-py. - An Amazon CloudWatch log group for the Lambda function called
/aws/lambda/Opensearch-skewmetrics-publisher-py. - An Amazon EventBridge rule for the Lambda function called
EventRuleForOSSkew. - The following CloudWatch metrics for the Lambda function:
aws_/<region-name>/<MetricIdentifier>/_storagemetricaws_/<region-name>/<MetricIdentifier>/_shardmetric
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account.
- An OpenSearch Service domain.
- This post requires you to add a Lambda role to the OpenSearch Service domain’s security configuration access policy. If your domain is using fine-grained access control, then you need to follow the steps as described in the section Mapping roles to users to enable access for the newly deployed Lambda execution role to the domain after deploying the CloudFormation template.
Deploy the CloudFormation template
To deploy the CloudFormation template, complete the following steps:
- Log in to your AWS account.
- Select the Region where you’re running your OpenSearch Service domain.
- To launch your CloudFormation stack, choose Launch Stack
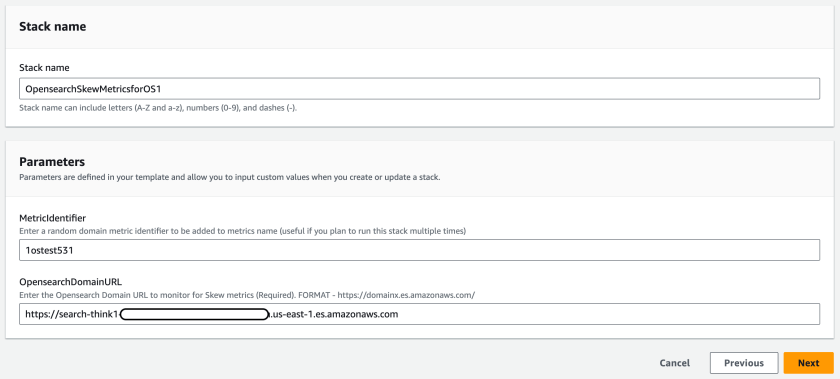
- For Stack name, enter a name for the stack (maximum length 30 characters).
- For MetricIdentifier, enter a unique identifier that will help you identify the custom CloudWatch metrics for your domain.
- For OpensearchDomainURL, enter the domain endpoint that you are monitoring.
- Choose Next.

- Select I acknowledge that AWS CloudFormation might create IAM resources, then choose Create stack.
- Wait for the stack creation to complete.
- On the Lambda console, choose Functions in the navigation pane.
- Choose the Lambda function called
Opensearch-SkewMetricsPublisher-py-<stackname>. - In the Code section, choose Test.
- Keep the default values for the test event and run a quick test.
Make sure to grant the Lambda execution role permission to the OpenSearch Service domain’s resource-based policy, if you are using one. If fine-grained access control is enabled on the domain, then follow the steps in Mapping roles to users (as mentioned in the prerequisites) to allow the Lambda function to read from the domain in read-only access.
The Lambda function that sends OpenSearch domain metrics to CloudWatch is set to a default frequency of 1 day. You can change this configuration to monitor the domain at the required granularity by updating the event schedule for the rule deployed by the CloudFormation stack on the EventBridge console. Note that if the frequency is set to 1 minute, this will trigger the Lambda function every minute and will increase the Lambda cost.
This solution uses the cat/allocation API, which provides the number of data nodes in the domain along with each data node’s number of shards and storage usage attributes. For further details on domain storage and shard skew, refer to Node shard and storage skew. The Lambda function processes and sorts each data node’s storage and shard skew from the average value. Any data node’s skew above 10% from the average is generally considered to be significantly skewed. This will start to impact CPU, network, and disk bandwidth usage because the nodes with the highest storage utilization tend to be the resource-strained nodes, whereas nodes with less than 10% usage represent underutilized capacity.
Refer to Demystifying Elasticsearch shard allocation for details related to shard size and shard count strategy. In general, we recommend keeping shard sizes between 10–30 GB for workloads where search latency is a key performance objective and 30–50 GB for write-heavy workloads. For shard count, we recommend maintaining index shard counts that are divisible by the data node count. For additional details, refer to Sizing Amazon OpenSearch Service domains and Shard strategy.
View skew metrics in CloudWatch
After you run this solution in your account, it will create two CloudWatch metrics for monitoring. To access these CloudWatch metrics, use the following steps:
- On the CloudWatch console, under Metrics in the navigation pane, choose All metrics.
- Choose Browse and select Custom namespaces. You should see two custom metrics ending with
_storageworkspaceand_shardworkspace, respectively. - Choose either of the custom metrics and then select NodeID.
- On the list of node IDs, select all the nodes displayed in the list, and the graph will be plotted automatically.
You can hover the mouse over the plotted lines to see the node skew information.
The following screenshots show examples of how the CloudWatch metrics will appear on the console.
The storage skew metrics will be similar to the following screenshot. Storage skew metrics shows the domain storage skew. If you hover over the graph, it shows the node list with available nodes in the domain. This list is sorted by the storage size (largest to smallest). The Lambda function will periodically post the latest storage skew results.

The shard skew metrics will be similar to the following screenshot. Shard skew metrics show the domain shard skew. If you hover over the graph, it shows the node list with available nodes in the domain. This list is sorted by the shard size (largest to smallest). The Lambda function will periodically post the latest storage skew results.

Storage skew occurs when one or more nodes within the domain has significantly more storage than other nodes. The CloudWatch metric will show higher deviation of storage usage for these nodes vs. other nodes. Similarly, shard skew occurs when one or more nodes has significantly more shards than others nodes. The CloudWatch metric will show higher deviation for these nodes vs. other nodes in the domain. When the domain storage or shard skew is detected, you can raise a support case to work with the AWS team for remediation actions. See How do I rebalance the uneven shard distribution in my Amazon OpenSearch Service cluster for information on how to take remediation actions to configure your domain shard strategy for optimal performance.
Costs
The cost associated with using this solution would be minimal, around few cents per month since it generates CloudWatch metrics. The solution also runs Lambda code, and in this case the Lambda functions make API calls. For pricing details, refer to Amazon CloudWatch Pricing and AWS Lambda Pricing.
Clean up
If you decide that you no longer want to keep the Lambda function and associated resources, you can navigate to the AWS CloudFormation console, choose the stack, and choose Delete.
If you want to add the CloudWatch skew monitor metrics mechanism back in at any point, you can create the stack again from the CloudFormation template.
Conclusion
You can use this solution to get a better understanding of your OpenSearch Service domain’s storage and shard skew to improve its performance and possibly lower the cost of operating your domain. See Use Elasticsearch’s _rollover API For efficient storage distribution for more details related to shard allocation and efficient storage distribution strategy.
About the authors
Nikhil Agarwal is Sr. Technical Manager with Amazon Web Services. He is passionate about helping customers achieve operational excellence in their cloud journey and working activity on technical solutions. He is also AI/ML enthusiastic and deep dives into customer’s ML-specific use cases. Outside of work, he enjoys traveling with family and exploring different gadgets.
Karthik Chemudupati is a Principal Technical Account Manager (TAM) with AWS, focused on helping customers achieve cost optimization and operational excellence. He has more than 19 years of IT experience in software engineering, cloud operations and automations. Karthik joined AWS in 2016 as a TAM and worked with more than dozen Enterprise Customers across US-West. Outside of work, he enjoys spending time with his family.
Gene Alpert is a Senior Analytics Specialist with AWS Enterprise Support. He has been focused on our Amazon OpenSearch Service customers and ecosystem for the past three years. Gene joined AWS in 2017. Outside of work he enjoys mountain biking, traveling, and playing Population:One in VR.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.