
ML Ops is an ML engineering culture and practice that aims at unifying ML system development and ML system operation. An important ML Ops design pattern is the ability to formalize ML workflows. This allows them to be reproduced, tracked and analyzed, shared, and more.
Source: Scalable ML Workflows using PyTorch on Kubeflow Pipelines and Vertex Pipelines
Pipelines frameworks support this pattern, and are the backbone of an ML Ops story. These frameworks help you to automate, monitor, and govern your ML systems by orchestrating your ML workflows.
In this post, we’ll show examples of PyTorch-based ML workflows on two pipelines frameworks: OSS Kubeflow Pipelines, part of the Kubeflow project; and Vertex Pipelines. We are also excited to share some Original Postipelines/tree/master/components/PyTorch/pytorch-kfp-components" target="_blank" rel="noreferrer noopener">new PyTorch components that have been added to the Kubeflow Pipelines repo.
In addition, we’ll show how the Vertex Pipelines examples, which require v2 of the KFP SDK, can now also be run on an OSS Kubeflow Pipelines installation using the KFP v2 ‘compatibility mode’.
PyTorch on Google Cloud Platform
PyTorch continues to evolve rapidly, with more complex ML workflows being deployed at scale. Companies are using PyTorch in innovative ways for AI-powered solutions ranging from autonomous driving to drug discovery, surgical Intelligence, and even agriculture. MLOps and managing the end-to-end lifecycle for these real world solutions, running at large scale, continues to be a challenge.
The recently-launched Vertex AI is a unified ML Ops platform to help data scientists and ML engineers increase their rate of experimentation, deploy models faster, and manage models more effectively. It brings AutoML and AI Platform together, with some new ML Ops-focused products, into a unified API, client library, and user interface.
Google Cloud Platform and Vertex AI are a great fit for PyTorch, with PyTorch support for Vertex AI training and serving, and PyTorch-based Deep Learning VM images and containers, including PyTorch XLA support.
The rest of this post will show examples of PyTorch-based ML workflows on two pipelines frameworks: OSS Kubeflow Pipelines, part of the Kubeflow project; and Vertex Pipelines. All the examples use the open-source Python KFP (Kubeflow Pipelines) SDK, which makes it straightforward to define and use PyTorch components.
Both pipelines frameworks provide sets of prebuilt components for ML-related tasks; support easy component (pipeline step) authoring and provide pipeline control flow like loops and conditionals; automatically log metadata during pipeline execution; support step execution caching; and more.
Both of these frameworks make it straightforward to build and use PyTorch-based pipeline components, and to create and run PyTorch-based workflows.
Kubeflow Pipelines
The Kubeflow open-source project includes Kubeflow Pipelines (KFP), a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers. The open-source Kubeflow Pipelines backend runs on a Kubernetes cluster, such as GKE, Google’s hosted Kubernetes. You can install the KFP backend ‘standalone’ — via CLI or via the GCP Marketplace— if you don’t need the other parts of Kubeflow.
The OSS KFP examples highlighted in this post show several different workflows and include some newly contributed components now in the Kubeflow Pipelines GitHub repo. These examples show how to leverage the underlying Kubernetes cluster for distributed training; use a TensorBoard server for monitoring and profiling; and more.
Vertex Pipelines
Vertex Pipelines is part of Vertex AI, and uses a different backend from open-source KFP. It is automated, scalable, serverless, and cost-effective: you pay only for what you use. Vertex Pipelines is the backbone of the Vertex AI ML Ops story, and makes it easy to build and run ML workflows using any ML framework. Because it is serverless, and has seamless integration with GCP and Vertex AI tools and services, you can focus on building and running your pipelines without dealing with infrastructure or cluster maintenance.
Vertex Pipelines automatically logs metadata to track artifacts, lineage, metrics, and execution across your ML workflows, and provides support for enterprise security controls like Cloud IAM, VPC-SC, and CMEK.
The example Vertex pipelines highlighted in this post share some underlying PyTorch modules with the OSS KFP example, and include use of the prebuilt Google Cloud Pipeline Components, which make it easy to access Vertex AI services. Vertex Pipelines requires v2 of the KFP SDK. It is now possible to use the KFP v2 ‘compatibility mode’ to run KFP V2 examples on an OSS KFP installation, and we’ll show how to do that as well.
PyTorch on Kubeflow Pipelines: PyTorch KFP Components SDK
In collaboration across Google and Facebook, we are announcing a number of technical contributions to enable large- scale ML workflows on Kubeflow Pipelines with PyTorch. This includes the PyTorch Kubeflow Pipelines components SDK with features for:
- Data loading and preprocessing
- Model Training using PyTorch Lightning as training loop
- Model profiling and visualizations using the new PyTorch Tensorboard Profiler
- Model deployment & Serving using TorchServe + KFServing with canary rollouts, autoscaling, and Prometheus monitoring
- Model Interpretability using Captum
- Distributed training using the PyTorch job operator for KFP
- Hyperparameter tuning using Ax/BoTorch
- ML Metadata for Artifact Lineage Tracking
- Cloud agnostic artifacts storage component using Minio
Computer Vision and NLP workflows are available for:
- Open Source Kubeflow Pipelines deployed on any cloud or on-prem
- Google Cloud Vertex AI Pipelines for Serverless pipelines solution
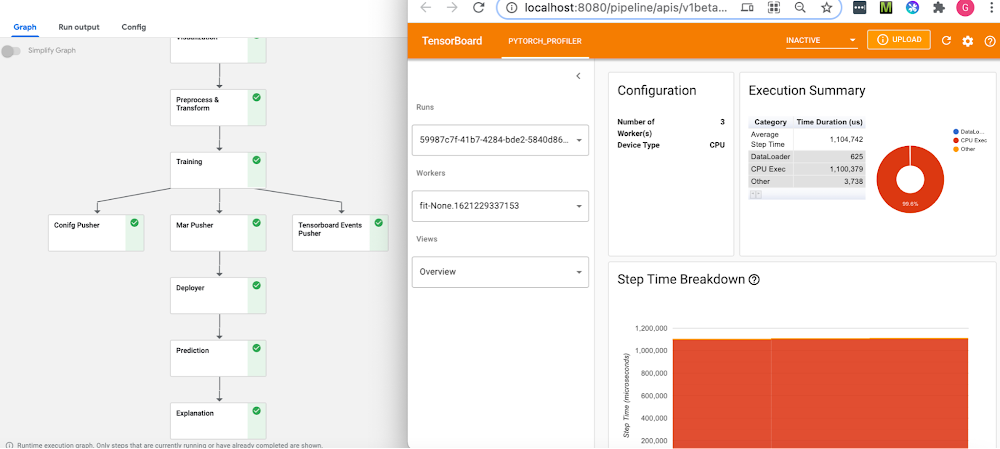
Start by setting up a KFP cluster with all the prerequisites, and then follow one of the examples under the pytorch-samples here. Sample notebooks and full pipelines examples are available for the following:
- Computer Vision CIFAR10 pipeline, basic notebook, and notebook with Captum Insights
- NLP BERT pipeline, and notebook with Captum for model interpretability.
- Distributed training sample using the PyTorch job operator
- Hyperparameter optimization sample using Ax/Botorch
Note: All the samples are expected to run both on-prem and on any cloud, using CPU or GPUs for training and inference. Minio is used as the cloud-agnostic storage solution. A custom TensorBoard image is used for viewing the PyTorch Profiler.
PyTorch on Kubeflow Pipelines : BERT NLP example
Let’s do a walkthrough of the BERT example notebook.
Training the PyTorch NLP model
One starts by defining the KFP pipeline with all the tasks to execute. The tasks are defined using the component yamls with configurable parameters. All templates are available here. The training component takes as input a PyTorch Lightning script, along with the input data and parameters and returns the model checkpoint, tensorboard profiler traces and the metadata for metrics like confusion matrix and artifacts tracking.
If you are using GPUs for training, set the gpus to value > 0 and use ‘ddp’ as the default accelerator type. You will also need to specify the gpu limit and node selector constraint for the cluster:
For generating traces for the PyTorch Tensorboard profiler, “profiler=pytorch” is set in script_args. The confusion matrix gets logged as part of the ML metadata in the KFP artifacts store, along with all the inputs and outputs and the detailed logs for pipeline run. You can view these from the pipeline graph and the lineage explorer (as shown in Figure 2 below). Caching is enabled by default, so if you run the same pipeline again with the same inputs, the results will be picked up from the KFP cache.
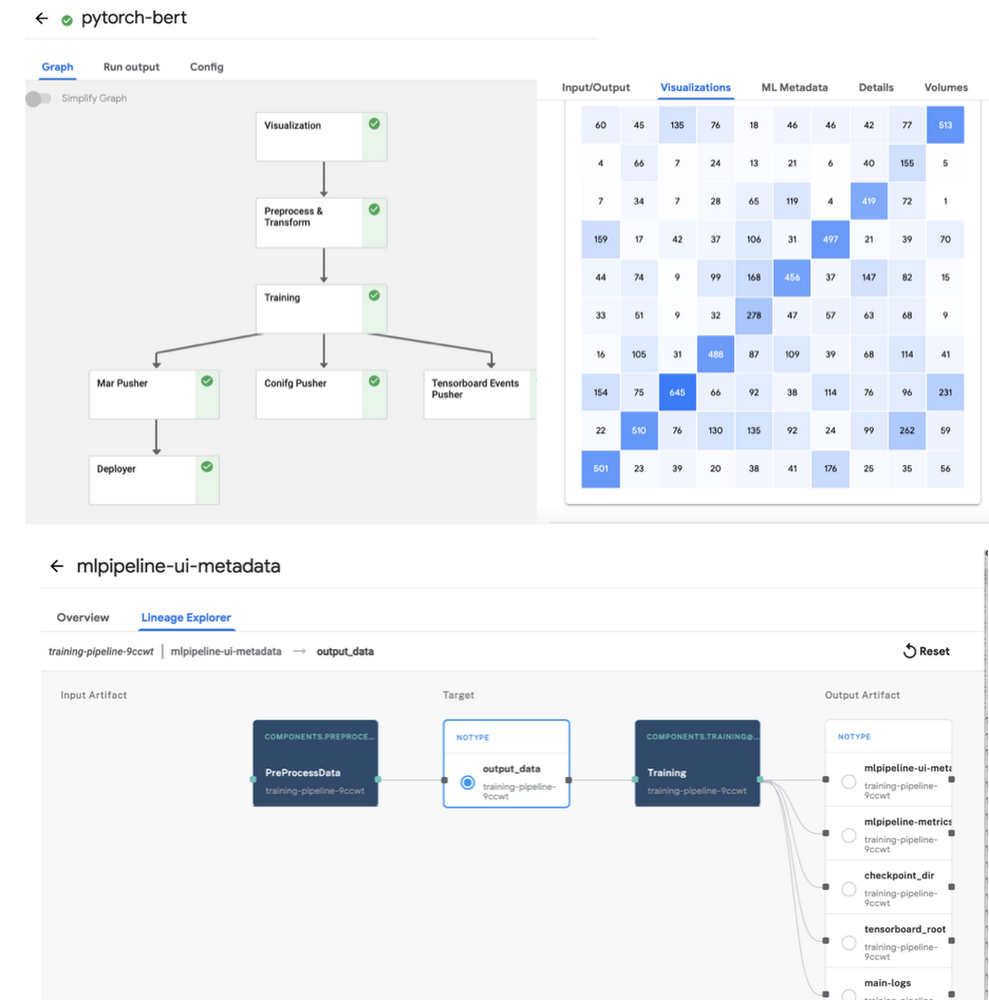
The template_mapping.json config file is used for generating the component yaml files from the templates and setting the script names and docker container with all the code. You can create a similar Docker container for your own pipeline.
Debugging using PyTorch Tensorboard Profiler
The PyTorch Tensorboard Profiler provides insights into the performance bottlenecks like inefficiency for loading data, underutilization of the GPUs, SM efficiency, and CPU-GPU thrashing, and is very helpful for debugging performance issues. Check out the Profiler 1.9 blog for the latest updates.
In the KFP pipeline, the Tensorboard Visualization component handles all the magic of making the traces available to the PyTorch Tensorboard profiler; therefore it is created before starting the training run. The profiler traces are saved in the tensorboard/logs bucket under the pipeline run ID and are available for viewing after the training step completes. You can access TensorBoard from the Visualization component of the pipeline after clicking the “Start Tensorboard” button. Full traces are available from the PyTorch Profiler view in the Tensboard as shown below:
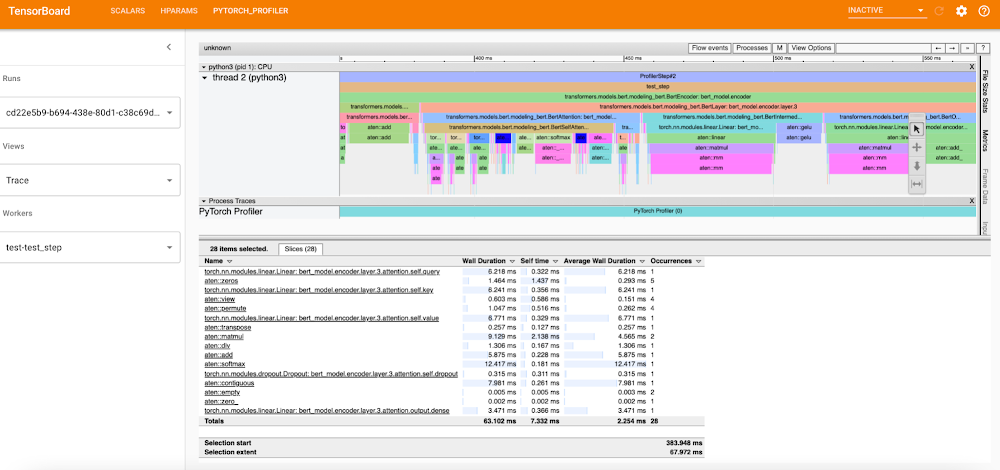
A custom docker container is used for the PyTorch profiler plugin, and you can specify the image name by setting the TENSORBOARD_IMAGE parameter.
Model Serving using KFServing with TorchServe
PyTorch model serving for running the predictions is done via the KFServing + TorchServe integration. It supports prediction and explanation APIs, canary rollouts with autoscaling, and monitoring using Prometheus and Grafana.
For the NLP BERT model, the bert_handler.py defines the TorchServe custom handler with logic for loading the model, running predictions, and doing the pre-processing and post processing. The training component generates the model files as a model-archiver package, and this gets deployed onto TorchServe. The minio op is used for making the model-archiver and the TorchServe config properties available to the deployment op. For deploying the model, you simply need to set the KFServing Inference yaml with the relevant values, e.g. for the GPU inference you will pass the model storage location, and the number of GPUs:
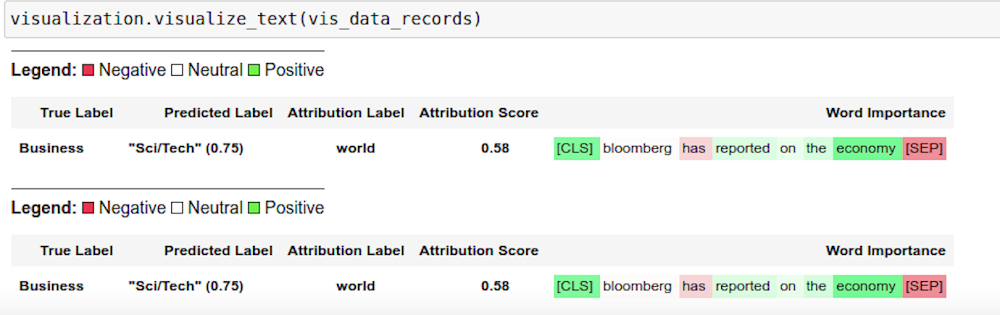
Using Captum for Model Interpretability
Captum.ai is the Model Interpretability library for PyTorch. In the NLP example we use the explanation API of KFserving and TorchServe to get the model insights for interpretability. The explain handler defines the IntegratedGradient computation logic which gets called via the explain endpoint and returns a json response with the interpretability output. The results are rendered in the notebook using Captum Insights.
This renders the color-coded visualization for the word importance.
Distributed training using PyTorch job operator
The Kubeflow PyTorch job operator is used for distributed training and it takes as inputs the job spec for the master and worker nodes along with the option to customize other parameters via the pytorch-launcher component.
PyTorch on Kubeflow Pipelines : CIFAR10 HPO example
Hyperparameter optimization using Ax/BoTorch
Ax is the adaptive experimentation platform for PyTorch, and BoTorch is the Bayesian Optimization library. They are used together for Hyperparameter optimization.
The CIFAR10-HPO notebook describes the usage for this. We start off by generating the experiment trials with the parameters that we want to optimize using the ax_generate_trials component.
Next, the trials are run in parallel using the ax_train_component.
And finally, the ax_complete_trials componentis used for processing the results for the best parameters from the Hyperparameter search.
The best parameters can be viewed under Input/Output section of ax_complete trials (as shown in the figure below):

PyTorch on Vertex Pipelines: CIFAR10 image classification example
The Vertex Pipelines examples in this post also use the KFP SDK, and include use of the Google Cloud Pipeline Components, which support easy access to Vertex AI services. Vertex Pipelines requires v2 of the KFP SDK. So, these examples diverge from the OSS KFP v1-based examples above, though the components share some of the same data processing and training base classes. It is now possible to use the KFP v2 ‘compatibility mode’ to run KFP V2 examples on an OSS KFP installation, and we’ll show how to do that as well.
An example PyTorch Vertex Pipelines notebook shows two variants of a pipeline that: do data preprocessing, train a PyTorch CIFAR10 resnet model, convert the model to archive format, build a torchserve serving container, upload the model container configured for Vertex AI custom prediction, and deploy the model serving container to an endpoint so that it can serve prediction requests on Vertex AI. In the example, the torchserve serving container is configured to use the kfserving service envelope, which is compatible with the Vertex AI prediction service.
Training the PyTorch image classification model
The difference between the two pipeline variants in the notebook is in the training step. One variant does on-step-node single-GPU training— that is, it runs the training job directly on the Vertex pipeline step node. We can specify how the pipeline step instance is configured, to give the node instance the necessary resources. This fragment from the KFP pipeline definition shows that configuration, which specifies to use one Nvidia V100 for the training step in the pipeline:
The other example variant in the notebook shows multi-GPU, single-node training via Vertex AI’s support for custom training, using the Vertex AI SDK.
From the ‘custom training’ pipeline step, a custom job is defined, passing the URI of the container image for the PyTorch training code:
Then the custom training job is run, specifying machine and accelerator types, and number of accelerators:
PyTorch prebuilt training containers are available as well, though for this example we used PyTorch v1.8, which at time of writing is not yet available in the prebuilt set.
Defining KFP Pipelines
Some steps in the example KFP v2 pipelines are built from Python function-based custom components— these make it easy to develop pipelines interactively, and are defined right in the example notebook— and other steps are defined using a set of prebuilt components that make it easy to interact with Vertex AI and other services— the steps that upload the model, create an endpoint, and deploy the model to the endpoint.
The custom components include pipeline steps to create a model archive from the trained PyTorch model and the model file, and to build a torchserve container image using the model archive file and the serving config.properties. The torchserve build step uses Cloud Build to create the container image.
These pipeline component definitions can be compiled to .yaml files, as shown in the example notebook. The .yaml component definitions are portable: they can be placed under version control and shared, and used to create pipeline steps for use in other pipeline definitions.
The KFP pipeline definition looks like the following, with some detail removed. (See the notebook for the full definition). Some pipeline steps consume as inputs the outputs of other steps. The prebuilt google_cloud_pipeline_components make it straightforward to access Vertex AI services. Note that the ModelDeployOp step is configured to serve the trained model on a GPU instance.
Here’s the pipeline graph for one of the Vertex Pipelines examples:
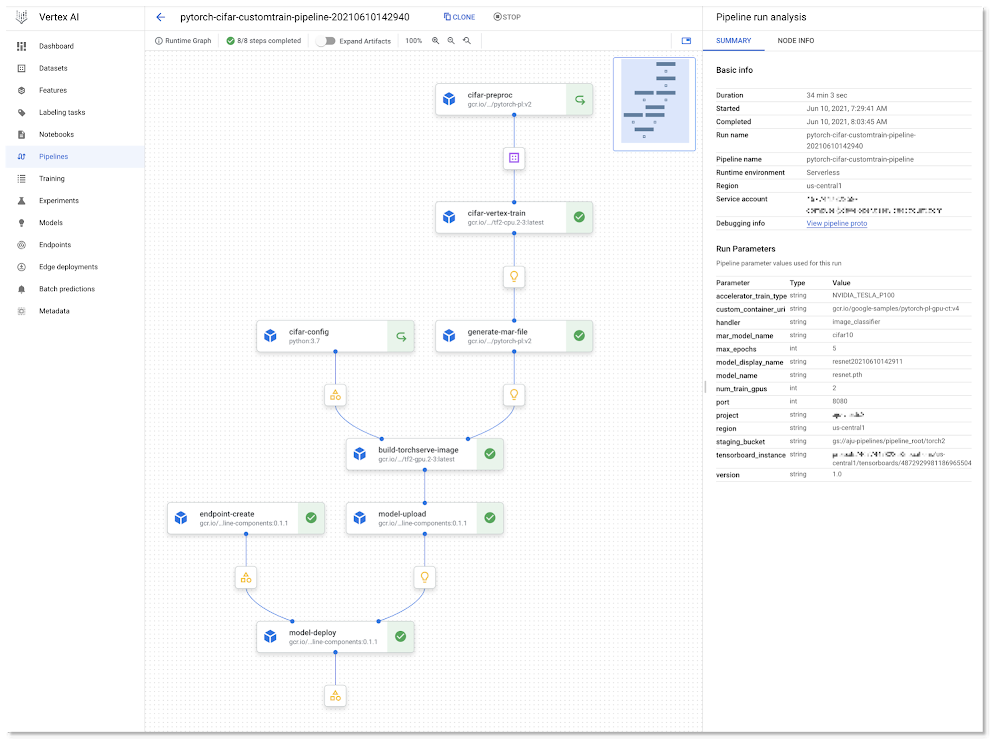
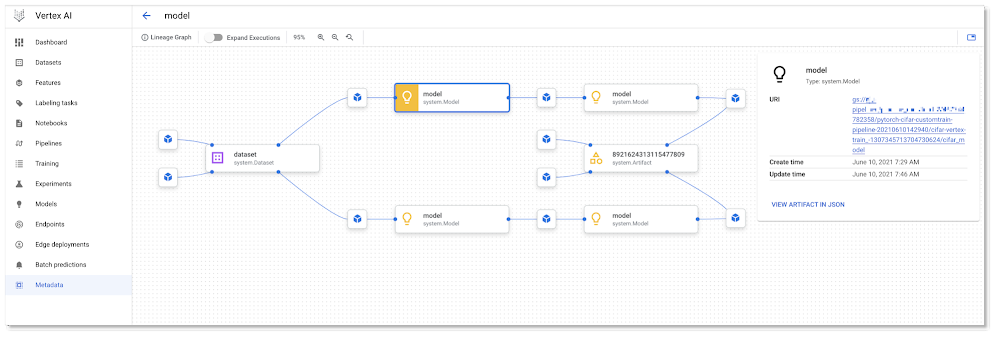
As a pipeline runs, metadata about the run, including its Artifacts, executions, and events, is automatically logged to the Vertex ML Metadata server. The Pipelines Lineage Tracker, part of the UI, uses the logged metadata to render an Artifact-centric view of pipeline runs, showing how Artifacts are connected by step executions. In this view, it’s easy to track where multiple pipeline runs have used the same artifact. (Where a pipeline is able to leverage caching, you will often notice that multiple pipeline runs are able to use the same cached step outputs.)
Using KFP ‘v2 compatibility mode’ to run the pipelines on an OSS KFP installation
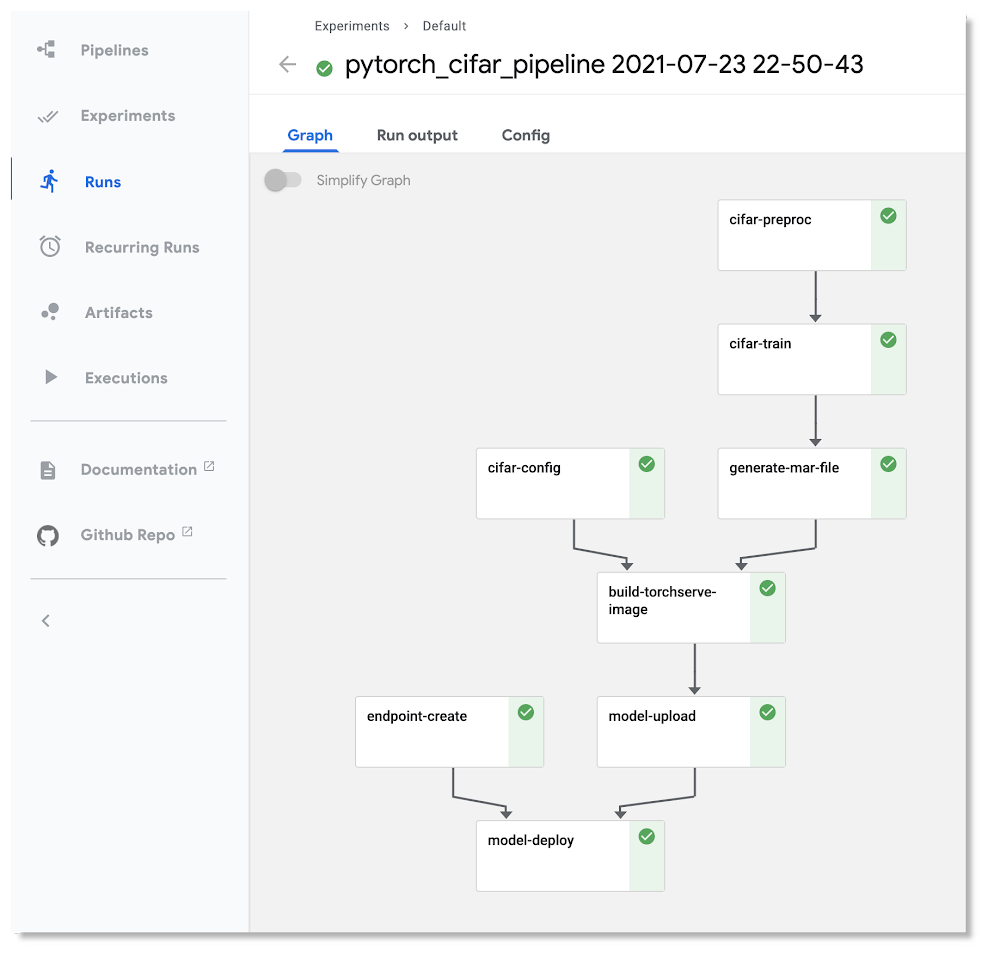
It is now possible to run the same KFP v2 pipelines in the Vertex example above on an OSS KFP installation. Kubeflow Pipelines SDK v2 compatibility mode lets you use the new pipeline semantics in v2 and gain the benefits of logging your metadata to ML Metadata. Compatibility mode means that you can develop a pipeline on one platform, and run it on the other.
Here is the pipeline graph for the same pipeline shown above running on Vertex Pipelines, but running on an OSS KFP installation. If you compare it to the Vertex Pipelines graph in the figure above, you can see that they have the same structure.
The example’s README gives more information about how to do the installation, and the example PyTorch Vertex Pipelines notebook includes sections that show how to launch an OSS KFP pipeline run once you’ve done the setup.
Next steps
This post showed some examples of how to build scalable ML workflows using PyTorch, running on both OSS Kubeflow Pipelines and Vertex Pipelines. Kubeflow and Vertex AI make it easy to use PyTorch on GCP, and we have announced some new PyTorch KFP components that make creating PyTorch-based ML workflows even easier. We also showed how the Vertex Pipelines examples, which require v2 of the KFP SDK, can now also be run on an OSS Kubeflow Pipelines installation using the KFP v2 ‘compatibility mode’.Please check out the samples here and here, and let us know what you think! You can provide feedback on the PyTorch Forums or file issues on the Kubeflow Pipelines Github repository.
Acknowledgements
The authors would like to thank the contributions from the following people for making this work possible: Pavel Dournov, Henry Tappen, Yuan Gong, Jagadeesh Jaganathan, Srinath Suresh, Alexey Volkov, Karl Weinmeister, Vaibhav Singh, and the Vertex Pipelines team.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.