
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. One of the challenges with security is that enterprises don’t want to have a concentration of superuser privileges amongst a handful of users. Instead, enterprises want to design their overarching security posture based on the specific duties performed via roles and assign these elevated privilege roles to different users. By assigning different privileges to different roles and assigning these roles to different users, enterprises can have more granular control of elevated user access.
In this post, we explore the role-based access control (RBAC) features of Amazon Redshift and how you can use roles to simplify managing privileges required to your end-users. We also cover new system views and functions introduced alongside RBAC.
Overview of RBAC in Amazon Redshift
As a security best practice, it’s recommended to design security by applying the principle of least privileges. In Amazon Redshift, RBAC applies the same principle to users based on their specific work-related role requirements, regardless of the type of database objects involved. This granting of privileges is performed at a role level, without the need to grant permissions for the individual user or user groups. You have four system-defined roles to get started, and can create additional, more granular roles with privileges to run commands that used to require the superuser privilege. With RBAC, you can limit access to certain commands and assign roles to authorized users. And you can assign object-level as well as system-level privileges to roles across Amazon Redshift native objects.
System-defined roles in Amazon Redshift
Amazon Redshift provides four system-defined roles that come with specific privileges. These can’t be altered or customized, but you can create your own roles as required. The system-defined roles use the sys: prefix, and you can’t use this prefix for the roles you create.
The following table summarizes the roles and their privileges.
| Role Name | Description of Privileges |
sys:operator |
Can access catalog or system tables, and analyze, vacuum, or cancel queries. |
sys:dba |
Can create schemas, create tables, drop schemas, drop tables, truncate tables, create or replace stored procedures, drop procedures, create or replace functions, create or replace external functions, create views, and drop views. Additionally, this role inherits all the privileges from the sys:operator role. |
sys:superuser |
Has the same privileges as the Amazon Redshift superuser. |
sys:secadmin |
Can create users, alter users, drop users, create roles, drop roles, and grant roles. This role can have access to user tables only when the privilege is explicitly granted to the role. |
System privileges
Amazon Redshift also adds support for system privileges that can be granted to a role or a user. A system privilege allows admins to grant a limited set of privileges to a user, such as the ability to create and alter users. These system-defined privileges are immutable and can’t be altered, removed, or added to.
Create custom roles for RBAC in Amazon Redshift
To further granularize the system privileges being granted to users to perform specific tasks, you can create custom roles that authorize users to perform those specific tasks within the Amazon Redshift cluster.
RBAC also supports nesting of roles via role hierarchy, and Amazon Redshift propagates privileges with each role authorization. In the following example, granting role R1 to role R2 and then granting role R2 to role R3 authorizes role R3 with all the privileges from the three roles. Therefore, by granting role R3 to a user, the user has all the privileges from roles R1, R2, and R3.
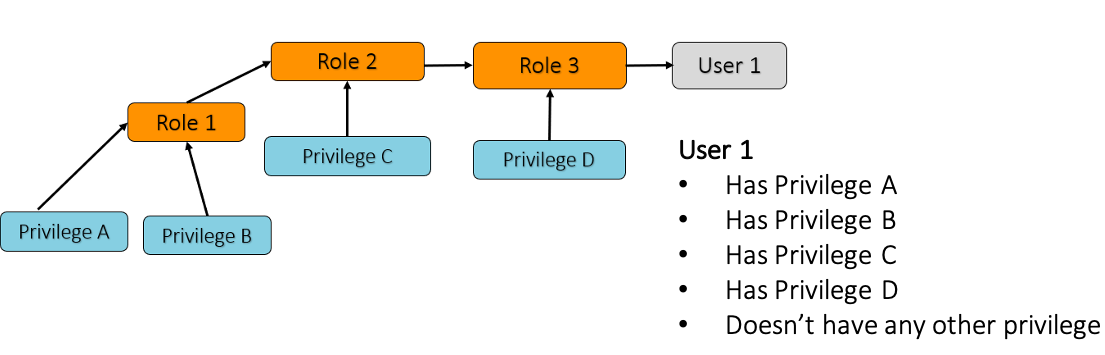
Amazon Redshift doesn’t allow creation of a cyclic role authorization cycle, so role R3 can’t be granted to role R1, as that would be cyclic role authorization.
You can use the Amazon Redshift commands for privileges to create role, grant role, revoke role, and the admin options for the grant and revoke. Only superusers or regular users who have been granted create role privileges can use those commands.
RBAC example use cases
For this post, we use the industry standard TPC-H dataset to demonstrate our example use cases.
We have three different teams in the organization: Sales, Marketing, and Admin. For this example, we have two schemas, sales and marketing, in the Amazon Redshift database. Each schema has the following tables: nation, orders, part, partsupp, supplier, region, customer, and lineitem.
We have two different database roles, read-only and read/write, for both the Sales team and Marketing team individually. Each role can only perform operations to the objects belonging to the schema to which the role is assigned. For example, a role assigned to the sales schema can only perform operations based on assigned privileges to the sales schema, and can’t perform any operation on the marketing schema.
The read-only role has read-only access to the objects in the respective schema when the privilege is granted to the objects.
The read/write role has read and write (insert, update) access to the objects in the respective schema when the privileges are granted to the objects.
The Sales team has read-only ( role name sales_ro) and read/write ( role name sales_rw) privileges.
The Marketing team has similar roles: read-only ( role name marketing_ro) and read/write ( role name marketing_rw).
The Admin team has one role (db_admin), which has privileges to drop or create database roles, truncate tables, and analyze the entire database. The admin role can perform at the database level across both sales and marketing schemas.
Set up for the example use cases
To set up for the example use cases, create a database admin role and attach it to a database administrator. A superuser must perform all these steps.
All the queries for this post are run in the Amazon Redshift native Query Editor v2, but can be run just the same in any query editor, such as SQLWorkbench/J.
- Create the admin role (
db_admin):create role db_admin; - Create a database user named
dbadmin:create user dbadmin password 'Test12345'; - Assign a system-defined role named
sys:dbato thedb_adminrole:grant role sys:dba to role db_admin;
This role has the privileges to create schemas, create tables, drop schemas, drop tables, truncate tables, create or replace stored procedures, drop procedures, create or replace functions, create or replace external functions, create views, drop views, access catalog or system tables, analyze, vacuum, and cancel queries.
- Assign a system-defined role named
sys:secadminto thedb_adminrole:grant role sys:secadmin to role db_admin;
This role has the privileges to create users, alter users, drop users, create roles, drop roles, and grant roles.
- Assign the user
dbadminto thedb_adminrole:grant role db_admin to dbadmin;
From this point forward, we use the dbadmin user credential for performing any of the following steps when no specific user is mentioned.
- Create the
salesandmarketingdatabase schema:create schema sales; create schema marketing; - Create all the eight tables (
nation,orders,part,partsupp,supplier,region,customer,lineitem) in thesalesandmarketingschemas.
You can use the DDL available on the GitHub repo to create and populate the tables.
After the tables are created and populated, let’s move to the example use cases.
Example 1: Data read-only task
Sales analysts may want to get the list of suppliers with minimal cost. For this, the sales analyst only needs read-only access to the tables in the sales schema.
- Let’s create the read-only role (
sales_ro) in the sales schema:create role sales_ro; - Create a database user named
salesanalyst:create user salesanalyst password 'Test12345'; - Grant the
salesschema usage and select access to objects of thesalesschema to the read-only role:grant usage on schema sales to role sales_ro; grant select on all tables in schema sales to role sales_ro; - Now assign the user to the read-only sales role:
grant role sales_ro to salesanalyst;
Now the salesanalyst database user can access the sales schema in the Amazon Redshift database using the salesanalyst credentials.

The salesanalyst user can generate a report of least-expensive suppliers using the following query:
set search_path to sales;
SELECT TOP 100
S_ACCTBAL,
S_NAME,
N_NAME,
P_PARTKEY,
P_MFGR,
S_ADDRESS,
S_PHONE,
S_COMMENT
FROM PART,
SUPPLIER,
PARTSUPP,
NATION,
REGION
WHERE P_PARTKEY = PS_PARTKEY AND
S_SUPPKEY = PS_SUPPKEY AND
P_SIZE = 34 AND
P_TYPE LIKE '%COPPER' AND
S_NATIONKEY = N_NATIONKEY AND
N_REGIONKEY = R_REGIONKEY AND
R_NAME = 'MIDDLE EAST' AND
PS_SUPPLYCOST = ( SELECT MIN(PS_SUPPLYCOST)
FROM PARTSUPP,
SUPPLIER,
NATION,
REGION
WHERE P_PARTKEY = PS_PARTKEY AND
S_SUPPKEY = PS_SUPPKEY AND
S_NATIONKEY = N_NATIONKEY AND
N_REGIONKEY = R_REGIONKEY AND
R_NAME = 'MIDDLE EAST'
)
ORDER BY S_ACCTBAL DESC,
N_NAME,
S_NAME,
P_PARTKEY
;
The salesanalyst user can successfully read data from the region table of the sales schema.
select * from sales.region;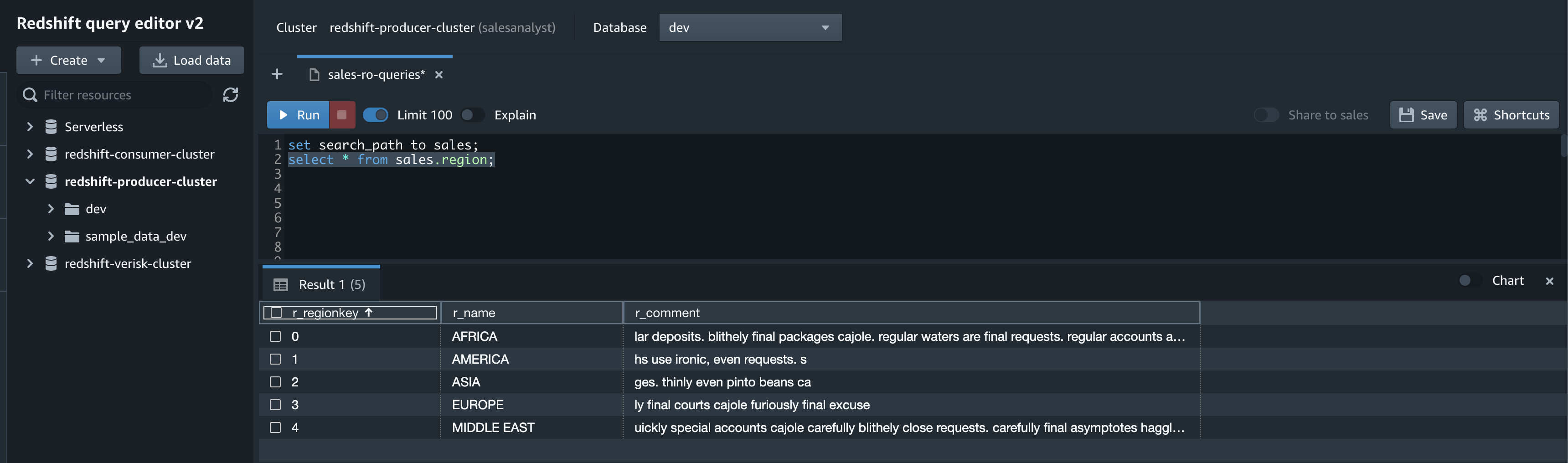
In the following example, the salesanalyst user wants to update the comment for Region key 0 and Region name AFRICA in the region table. But the command fails with a permission denied error because they only have select permission on the region table in the sales schema.
update sales.region
set r_comment = 'Comment from Africa'
where r_regionkey = 0;
The salesanalyst user also wants to access objects from the marketing schema, but the command fails with a permission denied error.
select * from marketing.region;
Example 2: Data read/write task
In this example, the sales engineer who is responsible for building the extract, transform, and load (ETL) pipeline for data processing in the sales schema is given read and write access to perform their tasks. For these steps, we use the dbadmin user unless otherwise mentioned.
- Let’s create the read/write role (
sales_rw) in thesalesschema:create role sales_rw; - Create a database user named
salesengineer:create user salesengineer password 'Test12345'; - Grant the
salesschema usage and select access to objects of thesalesschema to the read/write role by assigning the read-only role to it:grant role sales_ro to role sales_rw; - Now assign the user
salesengineerto the read/write sales role:grant role sales_rw to salesengineer;
Now the salesengineer database user can access the sales schema in the Amazon Redshift database using the salesengineer credentials.

The salesengineer user can successfully read data from the region table of the sales schema.
select * from sales.region;
However, they can’t read tables from the marketing schema because the salesengineer user doesn’t have permission.
select * from marketing.region;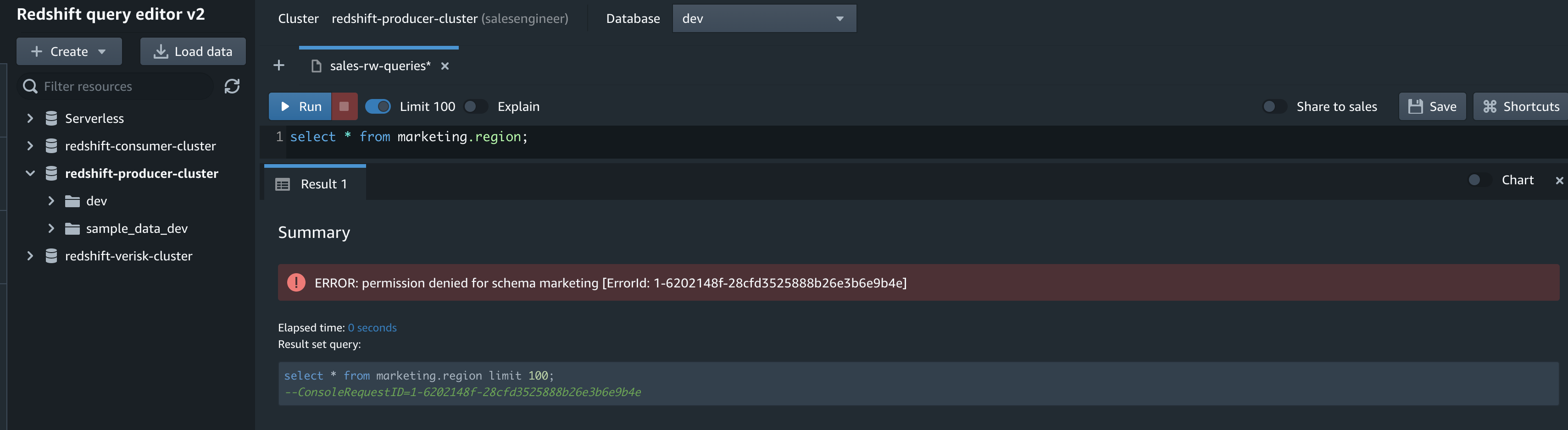
The salesengineer user then tries to update the region table in the sales schema but fails to do so.
update sales.region
set r_comment = 'Comment from Africa'
where r_regionkey = 0;
- Now, grant additional insert, update, and delete privileges to the read/write role:
grant update, insert, delete on all tables in schema sales to role sales_rw;The salesengineer user then retries to update the region table in the sales schema and is able to do so successfully.
update sales.region
set r_comment = 'Comment from Africa'
where r_regionkey = 0;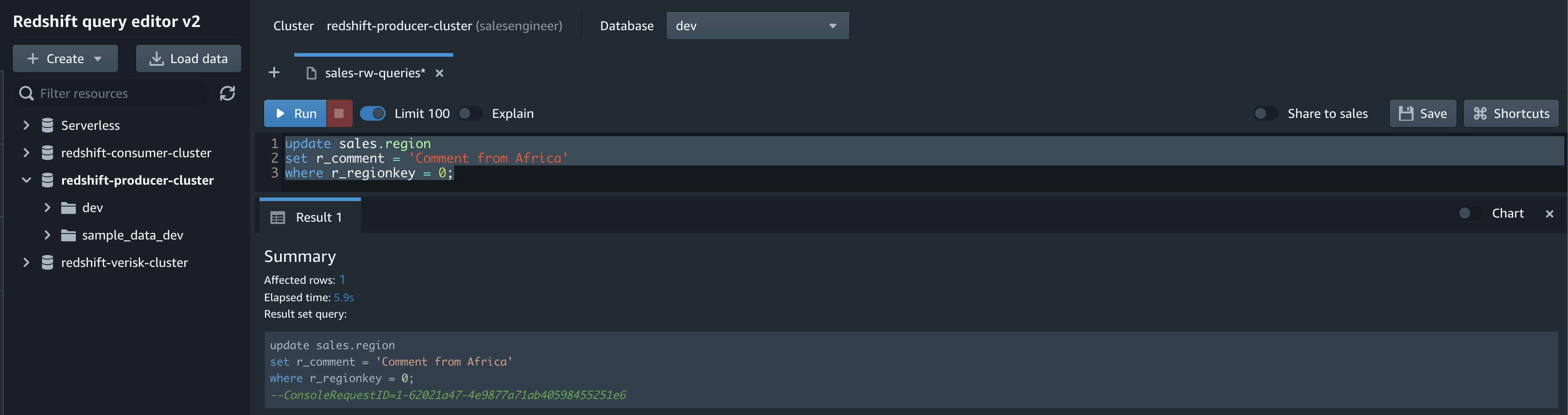
When they read the data, it shows that the comment was updated for Region key 0 (for AFRICA) in the region table in the sales schema.
select * from sales.region;
Now salesengineer wants to analyze the region table since it was updated. However, they can’t do so, because this user doesn’t have the necessary privileges and isn’t the owner of the region table in the sales schema.
analyze sales.region;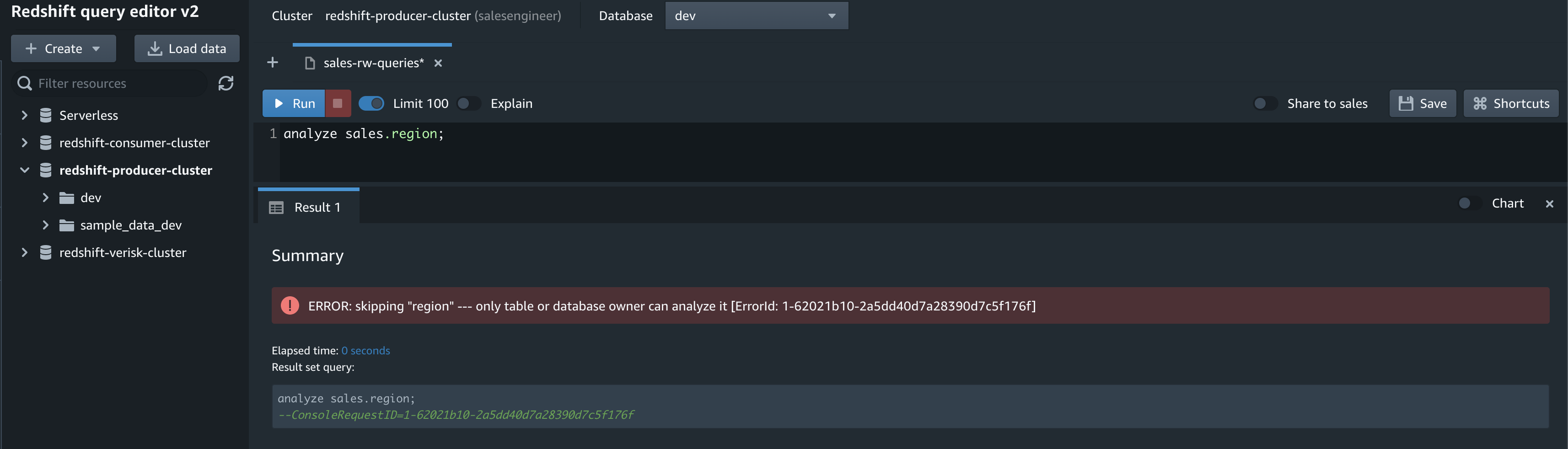
Finally, the salesengineer user wants to vacuum the region table since it was updated. However, they can’t do so because they don’t have the necessary privileges and aren’t the owner of the region table.
vacuum sales.region;
Example 3: Database administration task
Amazon Redshift automatically sorts data and runs VACUUM DELETE in the background.
Similarly, Amazon Redshift continuously monitors your database and automatically performs analyze operations in the background. In some situations, such as a major one-off data load, the database administrator may want to perform maintenance on objects in the sales and marketing schemas immediately. They access the database using dbadmin credentials to perform these tasks.

The dbadmin database user can access the Amazon Redshift database using their credentials to perform analyze and vacuum of the region table in the sales schema.
analyze sales.region;
Vacuum sales.region;
Now the dbadmin database user accesses the Amazon Redshift database to perform analyze and vacuum of the region table in the marketing schema.
analyze marketing.region;
vacuum marketing.region;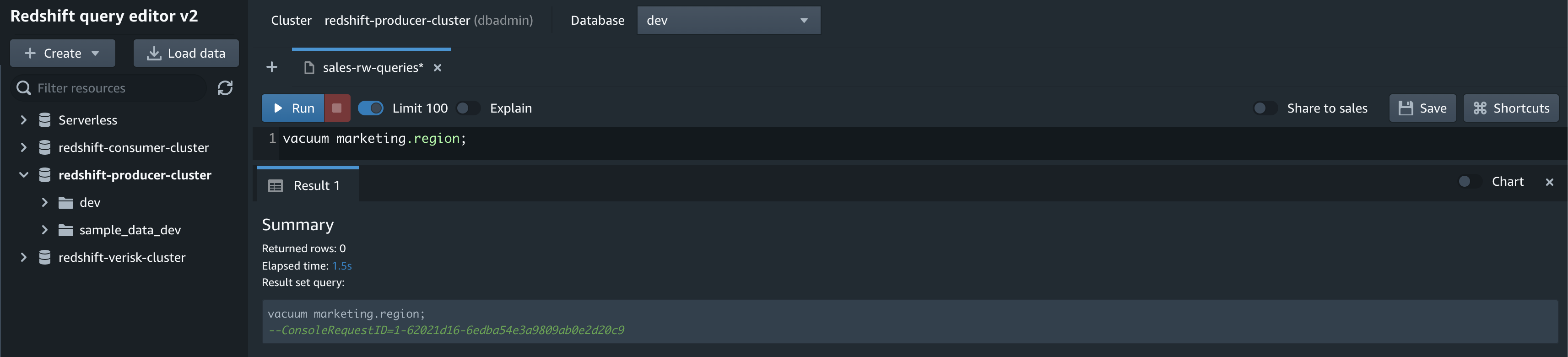
As part of developing the ETL process, the salesengineer user needs to truncate the region table in the sales schema. However, they can’t perform a truncate because they don’t have the necessary privileges, and aren’t the owner of the region table in the sales schema.
truncate sales.region;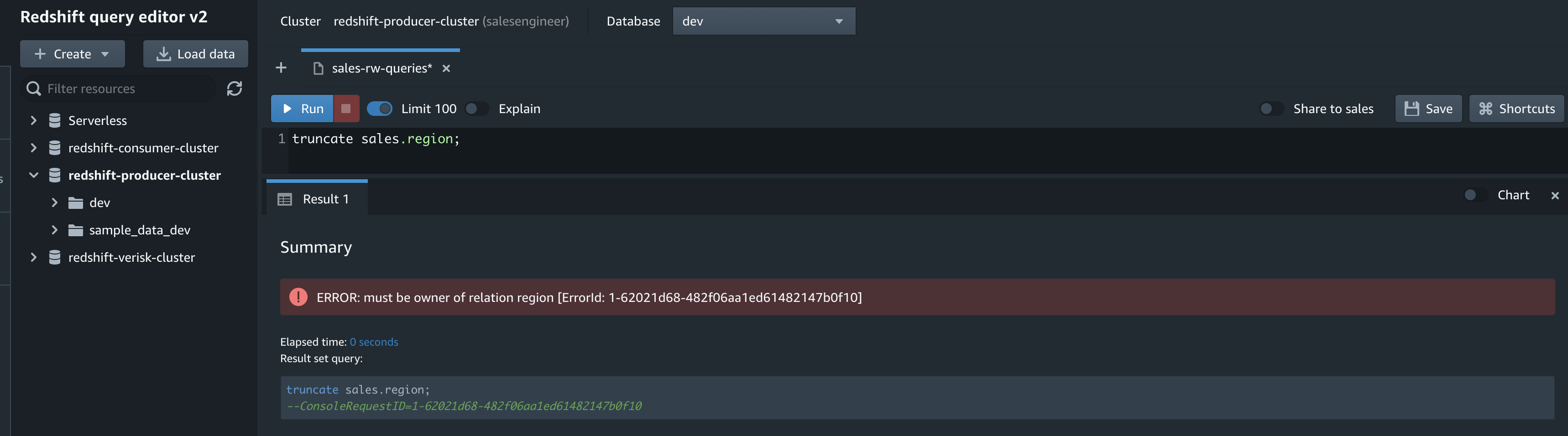
The dbadmin database user can access the Amazon Redshift database to provide truncate table privileges to the sales_rw role.
grant truncate table to role sales_rw;Now the salesengineer can perform a truncate on the region table in the sales schema successfully.
First, they read the data:
select * from sales.region;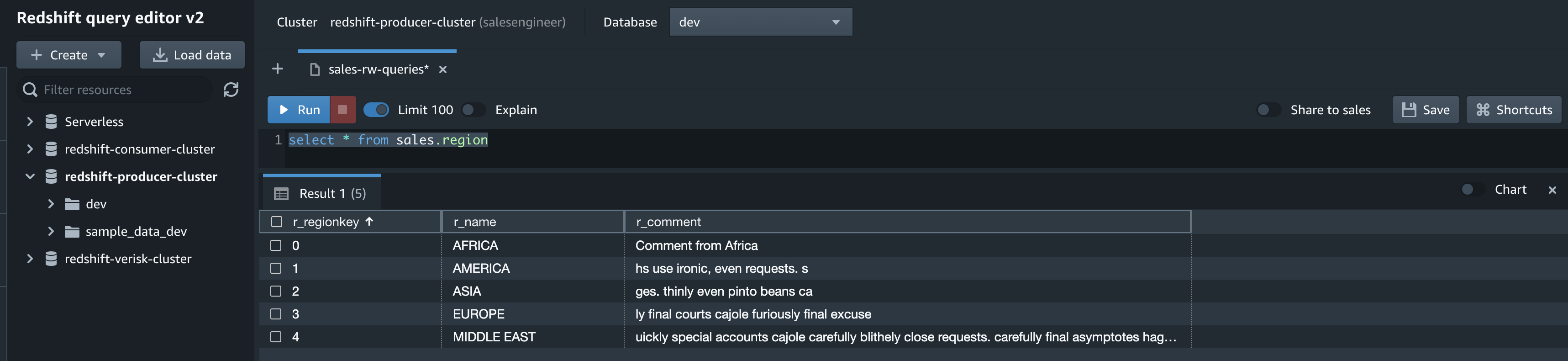
Then they perform the truncate:
truncate sales.region;
They read the data again to see the changes:
select * from sales.region;
For the marketing schema, you must perform similar operations for the marketing analyst and marketing engineer. We include the following scripts for your reference. The dbadmin user can use the following SQL commands to create the marketing roles and database users, assign privileges to those roles, and attach the users to the roles.
create role marketing_ro;
create role marketing_rw;
grant usage on schema marketing to role marketing_ro, role marketing_rw;
grant select on all tables in schema marketing to role marketing_ro;
grant role marketing_ro to role marketing_rw;
grant insert, update, delete on all tables in schema marketing to role marketing_rw;
create user marketinganalyst password 'Test12345';
create user marketingengineer password 'Test12345';
grant role marketing_ro to marketinganalyst;
grant role marketing_rw to marketingengineer;System functions for RBAC in Amazon Redshift
Amazon Redshift has introduced two new functions to provide system information about particular user membership and role membership in additional groups or roles: role_is_member_of and user_is_member_of. These functions are available to superusers as well as regular users. Superusers can check all role memberships, whereas regular users can only check membership for roles that they have been granted access to.
role_is_member_of(role_name, granted_role_name)
The role_is_member_of function returns true if the role is a member of another role. Superusers can check all roles memberships; regular users can only check roles to which they have access. You receive an error if the provided roles don’t exist or the current user doesn’t have access to them. The following two role memberships are checked using the salesengineer user credentials:
select role_is_member_of('sales_rw', 'sales_ro');
select role_is_member_of('sales_ro', 'sales_rw');
user_is_member_of( user_name, role_or_group_name)
The user_is_member_of function returns true if the user is a member of the specified role or group. Superusers can check all user memberships; regular users can only check their own membership. You receive an error if the provided identities don’t exist or the current user doesn’t have access to them. The following user membership is checked using the salesengineer user credentials, and fails because salesengineer doesn’t have access to salesanalyst:
select user_is_member_of('salesanalyst', 'sales_ro');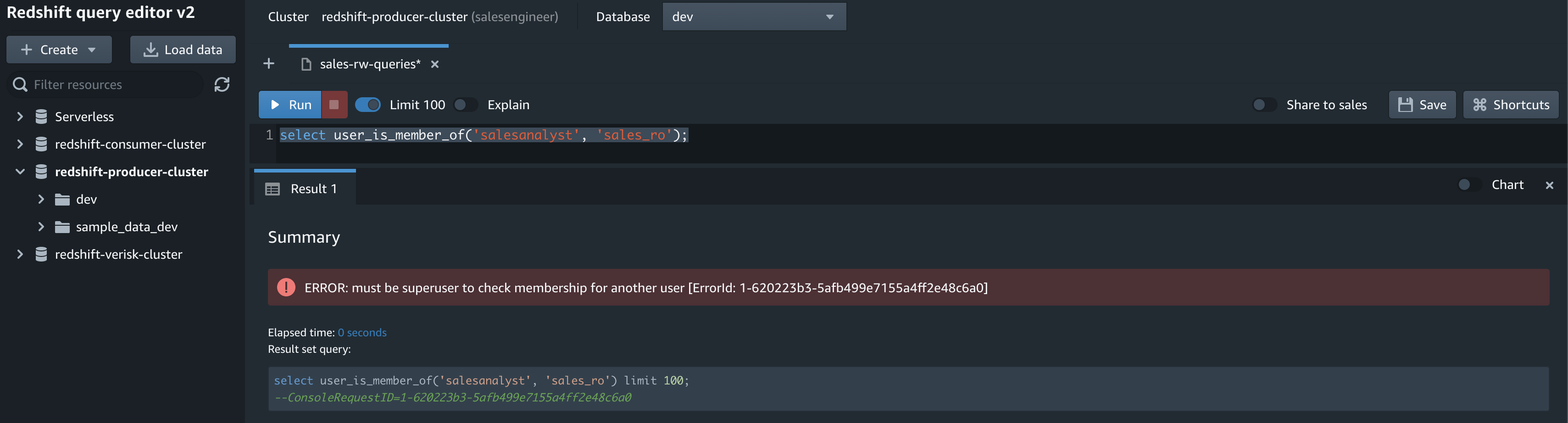
When the same user membership is checked using the superuser credential, it returns a result:
select user_is_member_of('salesanalyst', 'sales_ro');
When salesengineer checks their own user membership, it returns the correct results:
select user_is_member_of('salesengineer', 'sales_ro');
select user_is_member_of('salesengineer', 'marketing_ro');
select user_is_member_of('marketinganalyst', 'sales_ro');
System views for RBAC in Amazon Redshift
Amazon Redshift has added several new views to be able to view the roles, the assignment of roles to users, the role hierarchy, and the privileges for database objects via roles. These views are available to superusers as well as regular users. Superusers can check all role details, whereas regular users can only check details for roles that they have been granted access to.
For example, you can query svv_user_grants to view the list of users that are explicitly granted roles in the cluster, or query svv_role_grants to view a list of roles that are explicitly granted roles in the cluster. For the full list of system views, refer to SVV views.
Conclusion
In this post, we demonstrated how you can use role-based access control to further fortify your security posture by granularizing privileged access across users without needing to centralize superuser privileges in your Amazon Redshift cluster. Try out using database roles for your future Amazon Redshift implementations, and feel free to leave a comment about your experience.
In the future posts, we will show how these roles also integrate tightly with workload management. You can use them when defining WLM queues, and also while implementing single sign-on via identity federation with Microsoft Active Directory or a standards-based identity provider, such as Okta Universal Directory or Azure AD and other SAML-based applications.
About the Authors
Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift.
Dipankar Kushari is a Sr. Specialist Solutions Architect, Analytics with AWS.
Harshida Patel is a Specialist Sr. Solutions Architect, Analytics with AWS.
Debu Panda is a Senior Manager, Product Management with AWS. He is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world. Debu has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences such as re:Invent, Oracle Open World, and Java One. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt).
Huiyuan Wang is a software development engineer of Amazon Redshift. She has been working on MPP databases for over 6 years and has focused on query processing, optimization and metadata security.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.