Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Today, Amazon Redshift has become the most widely used cloud data warehouse.
With the significant growth of data for big data analytics over the years, some customers have asked how they should optimize Amazon Redshift workloads. In this post, we explore how to optimize workloads on Amazon Redshift clusters using Amazon Redshift RA3 nodes, data sharing, and pausing and resuming clusters. For more cost-optimization methods, refer to Getting the most out of your analytics stack with Amazon Redshift.
Key features of Amazon Redshift
First, let’s review some key features:
- RA3 nodes – Amazon Redshift RA3 nodes are backed by a new managed storage model that gives you the power to separately optimize your compute power and your storage. They bring a few very important features, one of which is data sharing. RA3 nodes also support the ability to pause and resume, which allows you to easily suspend on-demand billing while the cluster is not being used.
- Data sharing – Amazon Redshift data sharing offers you to extend the ease of use, performance, and cost benefits of Amazon Redshift in a single cluster to multi-cluster deployments while being able to share data. Data sharing enables instant, granular, and fast data access across Redshift clusters without the need to copy or move it. You can securely share live data with Amazon Redshift clusters in the same or different AWS accounts, and across regions. You can share data at many levels, including schemas, tables, views, and user-defined functions. You can also share the most up-to-date and consistent information as it’s updated in Amazon Redshift Serverless. It also provides fine-grained access controls that you can tailor for different users and businesses that all need access to the data. However, data sharing in Amazon Redshift has a few limitations.
Solution overview
In this use case, our customer is heavily using Amazon Redshift as their data warehouse for their analytics workloads, and they have been enjoying the possibility and convenience that Amazon Redshift brought to their business. They mainly use Amazon Redshift to store and process user behavioral data for BI purposes. The data has increased by hundreds of gigabytes daily in recent months, and employees from departments continuously run queries against the Amazon Redshift cluster on their BI platform during business hours.
The company runs four major analytics workloads on a single Amazon Redshift cluster, because some data is used by all workloads:
- Queries from the BI platform – Various queries run mainly during business hours.
- Hourly ETL – This extract, transform, and load (ETL) job runs in the first few minutes of each hour. It generally takes about 40 minutes.
- Daily ETL – This job runs twice a day during business hours, because the operation team needs to get daily reports before the end of the day. Each job normally takes between 1.5–3 hours. It’s the second-most resource-heavy workload.
- Weekly ETL – This job runs in the early morning every Sunday. It’s the most resource-heavy workload. The job normally takes 3–4 hours.
The analytics team has migrated to the RA3 family and increased the number of nodes of the Amazon Redshift cluster to 12 over the years to keep the average runtime of queries from their BI tool within an acceptable time due to the data size, especially when other workloads are running.
However, they have noticed that performance is reduced while running ETL tasks, and the duration of ETL tasks is long. Therefore, the analytics team wants to explore solutions to optimize their Amazon Redshift cluster.
Because CPU utilization spikes appear while the ETL tasks are running, the AWS team’s first thought was to separate workloads and relevant data into multiple Amazon Redshift clusters with different cluster sizes. By reducing the total number of nodes, we hoped to reduce the cost of Amazon Redshift.
After a series of conversations, the AWS team found that one of the reasons that the customer keeps all workloads on the 12-node Amazon Redshift cluster is to manage the performance of queries from their BI platform, especially while running ETL workloads, which have a big impact on the performance of all workloads on the Amazon Redshift cluster. The obstacle is that many tables in the data warehouse are required to be read and written by multiple workloads, and only the producer of a data share can update the shared data.
The challenge of dividing the Amazon Redshift cluster into multiple clusters is data consistency. Some tables need to be read by ETL workloads and written by BI workloads, and some tables are the opposite. Therefore, if we duplicate data into two Amazon Redshift clusters or only create a data share from the BI cluster to the reporting cluster, the customer will have to develop a data synchronization process to keep the data consistent between all Amazon Redshift clusters, and this process could be very complicated and unmaintainable.
After more analysis to gain an in-depth understanding of the customer’s workloads, the AWS team found that we could put tables into four groups, and proposed a multi-cluster, two-way data sharing solution. The purpose of the solution is to divide the workloads into separate Amazon Redshift clusters so that we can use Amazon Redshift to pause and resume clusters for periodic workloads to reduce the Amazon Redshift running costs, because clusters can still access a single copy of data that is required for workloads. The solution should meet the data consistency requirements without building a complicated data synchronization process.
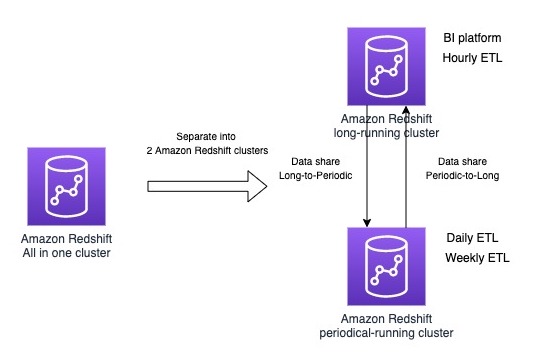
The following diagram illustrates the old architecture (left) compared to the new multi-cluster solution (right).

Dividing workloads and data
Due to the characteristics of the four major workloads, we categorized workloads into two categories: long-running workloads and periodic-running workloads.
The long-running workloads are for the BI platform and hourly ETL jobs. Because the hourly ETL workload requires about 40 minutes to run, the gain is small even if we migrate it to an isolated Amazon Redshift cluster and pause and resume it every hour. Therefore, we leave it with the BI platform.
The periodic-running workloads are the daily and weekly ETL jobs. The daily job generally takes about 1 hour and 40 minutes to 3 hours, and the weekly job generally takes 3–4 hours.
Data sharing plan
The next step is identifying all data (tables) access patterns of each category. We identified four types of tables:
- Type 1 – Tables are only read and written by long-running workloads
- Type 2 – Tables are read and written by long-running workloads, and are also read by periodic-running workloads
- Type 3 – Tables are read and written by periodic-running workloads, and are also read by long-running workloads
- Type 4 – Tables are only read and written by periodic-running workloads
Fortunately, there is no table that is required to be written by all workloads. Therefore, we can separate the Amazon Redshift cluster into two Amazon Redshift clusters: one for the long-running workloads, and the other for periodic-running workloads with 20 RA3 nodes.
We created a two-way data share between the long-running cluster and the periodic-running cluster. For type 2 tables, we created a data share on the long-running cluster as the producer and the periodic-running cluster as the consumer. For type 3 tables, we created a data share on the periodic-running cluster as the producer and the long-running cluster as the consumer.
The following diagram illustrates this data sharing configuration.

Build two-way data share across Amazon Redshift clusters
In this section, we walk through the steps to build a two-way data share across Amazon Redshift clusters. First, let’s take a snapshot of the original Amazon Redshift cluster, which became the long-running cluster later.

Now, let’s create a new Amazon Redshift cluster with 20 RA3 nodes for periodic-running workloads. Then we migrate the type 3 and type 4 tables to the periodic-running cluster. Make sure you choose the ra3 node type. (Amazon Redshift Serverless supports data sharing too, and it becomes generally available in July 2022, so it is also an option now.)

Create the long-to-periodic data share
The next step is to create the long-to-periodic data share. Complete the following steps:
- On the
periodic-runningcluster, get the namespace by running the following query:
SELECT current_namespace;Make sure record the namespace.
- On the
long-runningcluster, we run queries similar to the following:
CREATE DATASHARE ltop_share SET PUBLICACCESSIBLE TRUE;
ALTER DATASHARE ltop_share ADD SCHEMA public_long;
ALTER DATASHARE ltop_share ADD ALL TABLES IN SCHEMA public_long;
GRANT USAGE ON DATASHARE ltop_share TO NAMESPACE '[periodic-running-cluster-namespace]';- We can validate the long-to-periodic data share using the following command:
SHOW datashares;- After we validate the data share, we get the long-running cluster namespace with the following query:
SELECT current-namespace;Make sure record the namespace.
- On the
periodic-runningcluster, run the following command to load the data from the long-to-periodic data share with the long-running cluster namespace:
CREATE DATABASE ltop FROM DATASHARE ltop_share OF NAMESPACE '[long-running-cluster-namespace]';- Confirm that we have read access to tables in the long-to-periodic data share.
Create the periodic-to-long data share
The next step is to create the periodic-to-long data share. We use the namespaces of the long-running cluster and the periodic-running cluster that we collected in the previous step.
- On the
periodic-runningcluster, run queries similar to the following to create the periodic-to-long data share:
CREATE DATASHARE ptol_share SET PUBLICACCESSIBLE TRUE;
ALTER DATASHARE ptol_share ADD SCHEMA public_periodic;
ALTER DATASHARE ptol_share ADD ALL TABLES IN SCHEMA public_periodic;
GRANT USAGE ON DATASHARE ptol_share TO NAMESPACE '[long-running-cluster-namespace]';- Validate the data share using the following command:
SHOW datashares;- On the
long-runningcluster, run the following command to load the data from the periodic-to-long data using the periodic-running cluster namespace:
CREATE DATABASE ptol FROM DATASHARE ptol_share OF NAMESPACE '[periodic-running-cluster-namespace]';- Check that we have read access to the tables in the periodic-to-long data share.
At this stage, we have separated workloads into two Amazon Redshift clusters and built a two-way data share across two Amazon Redshift clusters.
The next step is updating the code of different workloads to use the correct endpoints of two Amazon Redshift clusters and perform consolidated tests.
Pause and resume the periodic-running Amazon Redshift cluster
Let’s update the crontab scripts, which run periodic-running workloads. We make two updates.
- When the scripts start, call the Amazon Redshift check and resume cluster APIs to resume the periodic-running Amazon Redshift cluster when the cluster is paused:
aws redshift resume-cluster --cluster-identifier [periodic-running-cluster-id] - After the workloads are finished, call the Amazon Redshift pause cluster API with the cluster ID to pause the cluster:
aws redshift pause-cluster --cluster-identifier [periodic-running-cluster-id]
Results
After we migrated the workloads to the new architecture, the company’s analytics team ran some tests to verify the results.
According to tests, the performance of all workloads improved:
- The BI workload is about 100% faster during the ETL workload running periods
- The hourly ETL workload is about 50% faster
- The daily workload duration reduced to approximately 40 minutes, from a maximum of 3 hours
- The weekly workload duration reduced to approximately 1.5 hours, from a maximum of 4 hours
All functionalities work properly, and cost of the new architecture only increased approximately 13%, while over 10% of new data had been added during the testing period.
Learnings and limitations
After we separated the workloads into different Amazon Redshift clusters, we discovered a few things:
- The performance of the BI workloads was 100% faster because there was no resource competition with daily and weekly ETL workloads anymore
- The duration of ETL workloads on the periodic-running cluster was reduced significantly because there were more nodes and no resource competition from the BI and hourly ETL workloads
- Even when over 10% new data was added, the overall cost of the Amazon Redshift clusters only increased by 13%, due to using the cluster pause and resume function of the Amazon Redshift RA3 family
As a result, we saw a 70% price-performance improvement of the Amazon Redshift cluster.
However, there are some limitations of the solution:
- To use the Amazon Redshift pause and resume function, the code for calling the Amazon Redshift pause and resume APIs must be added to all scheduled scripts that run ETL workloads on the periodic-running cluster
- Amazon Redshift clusters require several minutes to finish pausing and resuming, although you’re not charged during these processes
- The size of Amazon Redshift clusters can’t automatically scale in and out depending on workloads
Next steps
After improving performance significantly, we can explore the possibility of reducing the number of nodes of the long-running cluster to reduce Amazon Redshift costs.
Another possible optimization is using Amazon Redshift Spectrum to reduce the cost of Amazon Redshift on cluster storage. With Redshift Spectrum, multiple Amazon Redshift clusters can concurrently query and retrieve the same structured and semistructured dataset in Amazon Simple Storage Service (Amazon S3) without the need to make copies of the data for each cluster or having to load the data into Amazon Redshift tables.
Amazon Redshift Serverless was announced for preview in AWS re:Invent 2021 and became generally available in July 2022. Redshift Serverless automatically provisions and intelligently scales your data warehouse capacity to deliver best-in-class performance for all your analytics. You only pay for the compute used for the duration of the workloads on a per-second basis. You can benefit from this simplicity without making any changes to your existing analytics and BI applications. You can also share data for read purposes across different Amazon Redshift Serverless instances within or across AWS accounts.
Therefore, we can explore the possibility of removing the need to script for pausing and resuming the periodic-running cluster by using Redshift Serverless to make the management easier. We can also explore the possibility of improving the granularity of workloads.
Conclusion
In this post, we discussed how to optimize workloads on Amazon Redshift clusters using RA3 nodes, data sharing, and pausing and resuming clusters. We also explored a use case implementing a multi-cluster two-way data share solution to improve workload performance with a minimum code change. If you have any questions or feedback, please leave them in the comments section.
About the authors
Jingbin Ma is a Sr. Solutions Architect at Amazon Web Services. He helps customers build well-architected applications using AWS services. He has many years of experience working in the internet industry, and his last role was CTO of a New Zealand IT company before joining AWS. He is passionate about serverless and infrastructure as code.
Chao Pan is a Data Analytics Solutions Architect at Amazon Web Services. He’s responsible for the consultation and design of customers’ big data solution architectures. He has extensive experience in open-source big data. Outside of work, he enjoys hiking.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.