Distributed applications resiliency is a cumulative resiliency of applications, infrastructure, and operational processes. Part 1 of this series explored application layer resiliency. In Part 2, we discuss how using Amazon Web Services (AWS) managed services, redundancy, high availability, and infrastructure failover patterns based on recovery time and point objectives (RTO and RPO, respectively) can help in building more resilient infrastructures.
Pattern 1: Recognize high impact/likelihood infrastructure failures
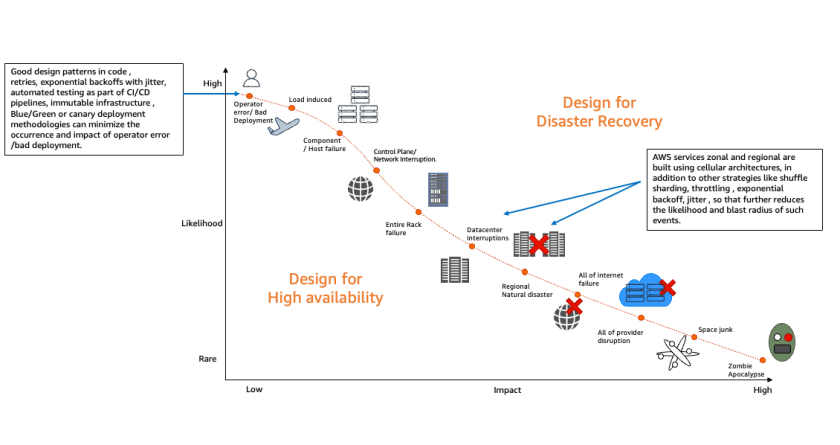
To ensure cloud infrastructure resilience, we need to understand the likelihood and impact of various infrastructure failures, so we can mitigate them. Figure 1 illustrates that most of the failures with high likelihood happen because of operator error or poor deployments.
Automated testing, automated deployments, and solid design patterns can mitigate these failures. There could be datacenter failures—like whole rack failures—but deploying applications using auto scaling and multi-availability zone (multi-AZ) deployment, plus resilient AWS cloud native services, can mitigate the impact.

Figure 1. Likelihood and impact of failure events
As demonstrated in the Figure 1, infrastructure resiliency is a combination of high availability (HA) and disaster recovery (DR). HA involves increasing the availability of the system by implementing redundancy among the application components and removing single points of failure.
Application layer decisions, like creating stateless applications, make it simpler to implement HA at the infrastructure layer by allowing it to scale using Auto Scaling groups and distributing the redundant applications across multiple AZs.
Pattern 2: Understanding and controlling infrastructure failures
Building a resilient infrastructure requires understanding which infrastructure failures are under control and which ones are not, as demonstrated in Figure 2.
These insights allow us to automate the detection of failures, control them, and employ pro-active patterns, such as static stability, to mitigate the need to scale up the infrastructure by over-provisioning it in advance.

Figure 2. Proactively designing systems in the event of failure
The infrastructure decisions under our control that can increase the infrastructure resiliency of our system, include:
- AWS services have control and data planes designed for minimum blast radius. Data planes typically have higher availability design goals than control planes and are usually less complex. When implementing recovery or mitigation responses to events that can affect resiliency, using control plane operations can lower the overall resiliency of your architectures. For example, Amazon Route 53 (Route 53) has a data plane designed for a 100% availability SLA. A good fail-over mechanism should rely on the data plane and not the control plane, as explained in Creating Disaster Recovery Mechanisms Using Amazon Route 53.
- Understanding networking design and routes implemented in a virtual private cloud (VPC) are critical when testing the flow of traffic in our application. Understanding the flow of traffic helps us design better applications and see how one component failure can affect overall ingress/egress traffic. To achieve better network resiliency, it’s important to implement a good subnet strategy and manage our IP addresses to avoid fail-over issues and asymmetric routing in hybrid architectures. Use IP address management tools for established subnet strategies and routing decisions.
- When designing VPCs and AZs, understanding the service limits, deploying independent routing tables and components in each zone increases availability. For example, highly available NAT gateways are preferred over NAT instances, as noted in the comparison provided in the Amazon VPC documentation.
Pattern 3: Considering different ways of increasing HA at the infrastructure layer
As already detailed, infrastructure resiliency = HA + DR.
Different ways by which system availability can be increased include:
- Building for redundancy: Redundancy is the duplication of application components to increase the overall availability of the distributed system. After following application layer best practices, we can build auto healing mechanisms at the infrastructure layer.
We can take advantage of auto scaling features and use Amazon CloudWatch metrics and alarms to set up auto scaling triggers and deploy redundant copies of our applications across multiple AZs. This protects workloads from AZ failures, as shown in Figure 3.

Figure 3. Redundancy increases availability
- Auto scale your infrastructure: When there are AZ failures, infrastructure auto scaling maintains the desired number of redundant components, which helps maintain the base level application throughput. This way, HA system and manage costs are maintained. Auto scaling uses metrics to scale in and out, appropriately, as shown in Figure 4.

Figure 4. How auto scaling improves availability
- Implement resilient network connectivity patterns: While building highly resilient distributed systems, network access to AWS infrastructure also needs to be highly resilient. While deploying hybrid applications, the capacity needed for hybrid applications to communicate with their cloud native application counterparts is an important consideration in designing the network access using AWS Direct Connect or VPNs.
Testing failover and fallback scenarios helps validate that network paths operate as expected and routes fail over as expected to meet RTO objectives. As the number of connection points between the data center and AWS VPCs increases, a hub and spoke configuration provided by the Direct Connect gateway and transit gateways simplify network topology, testing, and fail over. For more information, visit the AWS Direct Connect Resiliency Recommendations.
- Whenever possible, use the AWS networking backbone to increase security, resiliency, and lower cost. AWS PrivateLink provides secure access to AWS services and exposes the application’s functionalities and APIs to other business units or partner accounts hosted on AWS.
- Security appliances need to be set up in HA configuration, so that even if one AZ is unavailable, security inspection can be taken over by the redundant appliances in the other AZs.
- Think ahead about DNS resolution: DNS is a critical infrastructure component; hybrid DNS resolution should be designed carefully with Route 53 HA inbound and outbound resolver endpoints instead of using self-managed proxies.
Implement a good strategy to share DNS resolver rules across AWS accounts and VPC’s with Resource Access Manager. Network failover tests are an important part of Disaster Recovery and Business Continuity Plans. To learn more, visit Original Postatterns/set-up-integrated-dns-resolution-for-hybrid-networks-in-amazon-route-53.html" target="_blank" rel="noopener">Set up integrated DNS resolution for hybrid networks in Amazon Route 53.
- Use managed services: The same concept of redundancy in application components affecting availability applies to AWS infrastructure components. AWS services, like AWS Lambda, Amazon Simple Queue Service, Elastic Load Balancing (ELB), and Amazon Simple Storage Service, use multiple AZs under the hood for resiliency.
Additionally, ELB uses health checks to make sure that requests will route to another component if the underlying traffic application component fails. This improves the distributed system’s availability, as it is the cumulative availability of all different layers in our system. Figure 5 details advantages of some AWS managed services.
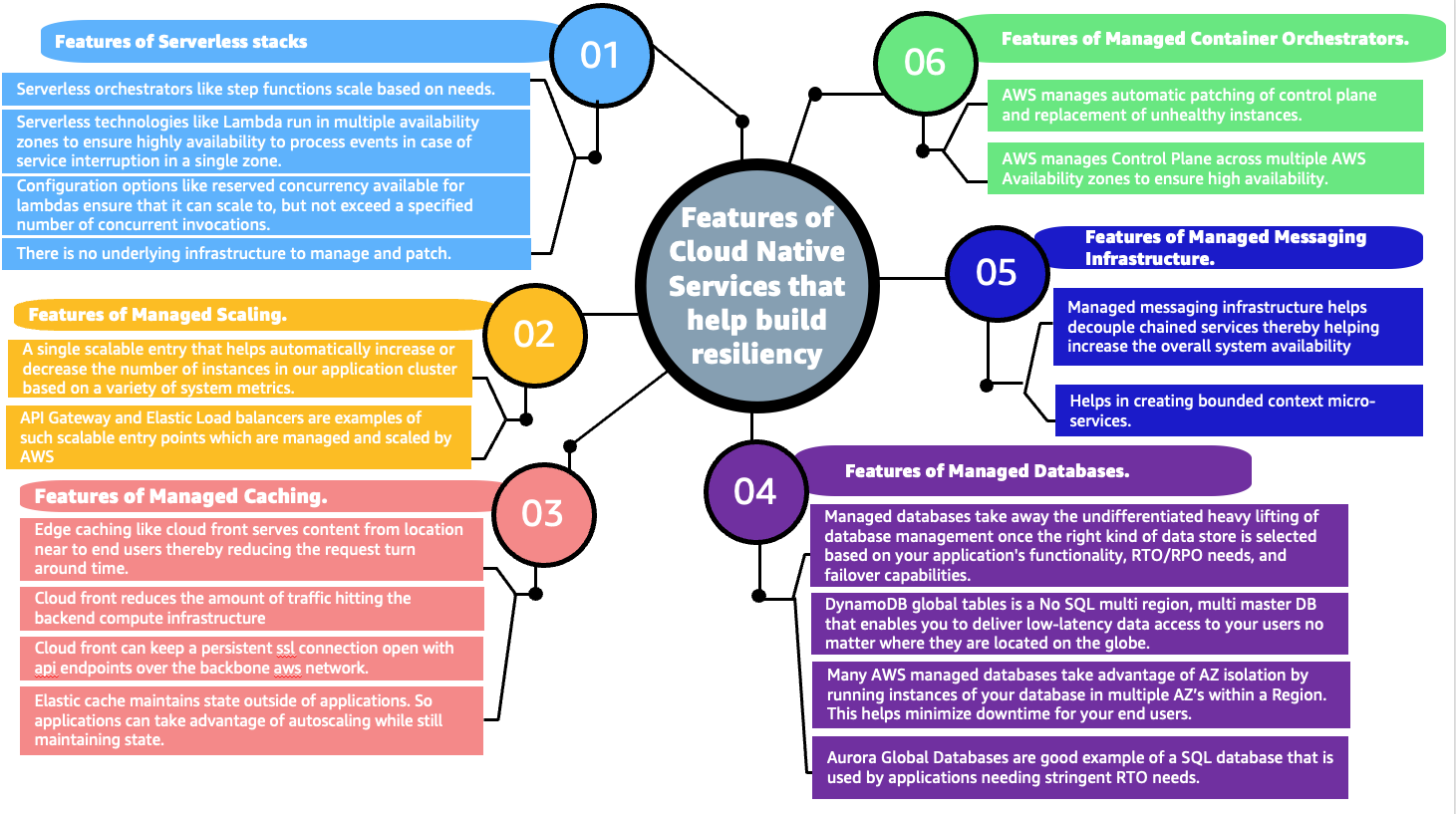
Figure 5. AWS managed services help in building resilient infrastructures (click the image to enlarge)
Pattern 4: Use RTO and RPO requirements to determine the correct failover strategy for your application
Capture RTO and RPO requirements early on to determine solid failover strategies (Figure 6). Disaster recovery strategies within AWS range from low cost and complexity (like backup and restore), to more complex strategies when lower values of RTO and RPO are required.
In pilot light and warm standby, only the primary region receives traffic. Pilot light only critical infrastructure components run in the backup region. Automation is used to check failures in the primary region using health checks and other metrics.
When health checks fail, use a combination of auto scaling groups, automation, and Infrastructure as Code (IaC) for quick deployment of other infrastructure components.
Note: This strategy depends on control plane availability in the secondary region for deploying the resources; keep this point in mind if you don’t have compute pre-provisioned in the secondary region. Carefully consider the business requirements and a distributed system’s application-level characteristics before deciding on a failover strategy. To understand all the factors and complexities involved in each of these disaster recovery strategies refer to disaster recovery options in the cloud.

Figure 6. Relationship between RTO, RPO, cost, data loss, and length of service interruption
Conclusion
In Part 2 of this series, we discovered that infrastructure resiliency is a combination of HA and DR. It is important to consider likelihood and impact of different failure events on availability requirements. Building in application layer resiliency patterns (Part 1 of this series), along with early discovery of the RTO/RPO requirements, as well as operational and process resiliency of an organization helps in choosing the right managed services and putting in place the appropriate failover strategies for distributed systems.
It’s important to differentiate between normal and abnormal load threshold for applications in order to put automation, alerts, and alarms in place. This allows us to auto scale our infrastructure for normal expected load, plus implement corrective action and automation to root out issues in case of abnormal load. Use IaC for quick failover and test failover processes.
Stay tuned for Part 3, in which we discuss operational resiliency!
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.