
With the shift to value-based care, tapping data to its fullest to improve patient satisfaction tops the priority of healthcare executives everywhere. To achieve this, reliance on key technology relevant to their sphere is a must. This is where data lakes can help. A data lake is an architecture that can assist providers in storing, sharing, and utilizing electronic health records and other patient data. Healthcare organizations are already utilizing data lakes to unite heterogeneous data from across hospital systems. The use of data lakes has aided in the effective transformation of the organizational culture, resulting in a data-driven approach to resolving issues. Healthcare clinical quality metric systems stream massive amounts of structured and semi-structured data into a data lake in real time from various sources. However, storing structured data in a data lake and applying schema-on-read leads to quality issues and adds complexity to the simple structured data process.
In this post, we demonstrate how to modernize your clinical quality data repositories with Amazon Redshift Data Vault.
How healthcare systems use data lakes
Data lakes are popular in healthcare systems because they allow the integration and exploratory analysis of diverse data. Data lakes comprise multiple data assets stored within a Hadoop ecosystem with minimal alterations to the original data format (or file). Because of this, the data lake lacks schema-on-write functionality. In data lakes, information is accessed using a methodology called schema-on-read. On the other hand, a data warehouse is a subject-oriented, time-variant, and centrally controlled database system designed for the management of mixed workloads and large queries. The schema of the data warehouse is predefined, the data written to it must conform to its schema (schema-on-write). It’s perfect for structured data storage.
Because the healthcare industry wants to preserve the data in raw format for compliance and regulatory requirements, data lakes are widely used in clinical quality tracking systems even though the incoming data are structured and semi-structured. For business and analytical use cases, the data in a data lake is further converted into a dimensional schema and loaded into a data warehouse. Data warehouses require several months of modeling, mapping, ETL (extract, transform, and load) planning and creation, and testing. The result is consistent, validated data for reporting and analytics.
The following diagram shows a typical clinical quality repository in a current healthcare system.
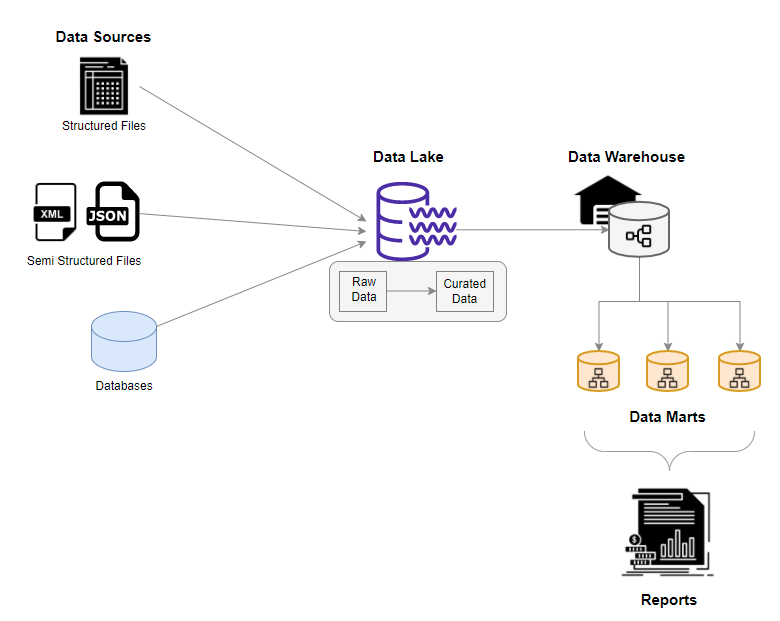
Data lakes offer information in its raw form, as well as a specialized means to obtaining data that applies the schema-on-read. In general, data lake users are experienced analysts familiar with data wrangling techniques that apply schema-on-read or understand data content from unstructured formats. Business users and data visualization builders struggle in the absence of powerful purpose-built search capabilities and data extraction algorithms. That isn’t to say data lakes are devoid of metadata or rules controlling their use, security, or administration. It’s the exact opposite. A successful data lake structures its data in such a way that it promotes better and more efficient access, and reuses data management methods or provides new tools that increase search and general knowledge of the data content.
Challenges in the data lake
However, data modeling shouldn’t be disregarded while employing the schema-on-read approach to handle data. A lack of meaningful data structure might lead to data quality problems, integration issues, performance issues, and deviations from organizational goals. Storing structured data in a data lake and then applying schema-on-read generates problems with data quality and complicates a basic structured data operation. You can also keep these structured datasets in data warehouses by skipping the data lake, but this increases the complexity of scaling, data transformation, and loading (ETL). But data warehouse ETL jobs apply a large number of business rules and heavily transform the data from its raw form to make the data fit one or more business purposes.
Dimensional representation data warehouses are located close to business applications but away from the source. This brings new challenges, like reverse tracking the data to its source to identify potential data errors and keep the original source for regulatory validation. In clinical quality reporting and regulatory reporting, accuracy is key. To provide high accuracy and data quality, developers often reverse track the data to its original source. This is very complex and sometimes not possible in a data warehouse model because the data loses its raw form. Compared to data warehouses, data lakes perform poorly in terms of dataset identification, processing, and catalog management. It’s complex to securely share data in a data lake between accounts. Cloud data lakes show improvement in this area, but some human intervention is still needed to make sure the data catalogs and security match healthcare requirements and standards.
Design and build a Data Vault model in Amazon Redshift
Amazon Redshift is a relational database system based on the PostgreSQL standard. It’s designed to efficiently run online analytical processing (OLAP) queries on petabyte-scale data. It also offers other query-handling efficiencies such as parallel processing, columnar database design, column data compression, a query optimizer, and compiled query code. A cluster is at the heart of every Amazon Redshift deployment. Each cluster consists of a leader node and one or more compute nodes, all of which are linked by high-speed networks.
Amazon Redshift RA3 instances with managed storage allow you to choose the number of nodes based on your performance requirements. The RA3 instance type can scale your data warehouse storage capacity automatically without manual intervention, and without needing to add additional compute resources. The number of nodes you choose is determined by the quantity of your data and the query processing performance you want.
The following diagram illustrates the Amazon Redshift RA3 instance architecture.
The interface to your business intelligence application is provided by a leader node. It provides conventional PostgreSQL JDBC/ODBC query and response interfaces. It acts as a traffic cop, routing requests from client applications to the proper compute nodes and managing the results that are delivered. It also distributes ingested data to computing nodes so that your databases may be built.
Amazon Redshift features like streaming, RA3’s near-limitless storage, Amazon Redshift ML, the SUPER data type, automatic table optimization, materialized views, and Amazon Redshift Spectrum open up the possibility of modernizing healthcare clinical quality data repositories and standardizing the data model for fast access and high accuracy. These features make RA3 instances the perfect candidate for your clinical quality repository. Additionally, the data sharing capability in Amazon Redshift keeps a single source for truth across the organization and removes the need for data silos. It’s tightly coupled with other AWS services, which allows you to take advantage of the AWS Cloud ecosystem and get the most out of your data with less effort.
Standardizing data modeling has two benefits: it allows you to reuse technical and organizational procedures (for example, ETL and project management), and you can readily merge data from diverse contexts without much complication. Because storage is separated from the computing, the Amazon Redshift RA3 instance retains the classic data lake feature of storing huge amounts of data. On the data side, to keep the data close to its raw form, a Data Vault model is the ideal solution to this problem.
Data Vault is a methodology to speed up the development of data warehouse initiatives and keep the data close to its sources. The Data Vault 2.0 data modeling standards are popular because they stress the business keys by hashing the keys across entities. This eliminates the need for strong relationships between entities and their linkages within the delivery of business processes. Data Vault makes it easy to integrate with versatile data sources for completely different use cases than it’s originally designed for, due to the following features:
- Entities can stand alone and be built on patterns, each with a well-defined purpose.
- Because the data represents the source system and delivers business value, data silos are eliminated.
- You can load data in parallel with the least number of dependencies.
- Historized data is kept at the coarsest level of granularity possible.
- You can implement flexible business rules independently of data loading. This reduces the time taken to load the data by 25%.
- You can add new data sources without affecting the current model.
The following diagram illustrates the Amazon Redshift RA3 instance architecture.

The interface to your business intelligence application is provided by a leader node. It provides conventional PostgreSQL JDBC/ODBC query and response interfaces. It acts as a traffic cop, routing requests from client applications to the proper compute nodes and managing the results that are delivered. It also distributes ingested data to computing nodes so that your databases may be built.
Amazon Redshift features like streaming, RA3’s near-limitless storage, Amazon Redshift ML, the SUPER data type, automatic table optimization, materialized views, and Amazon Redshift Spectrum open up the possibility of modernizing healthcare clinical quality data repositories and standardizing the data model for fast access and high accuracy. These features make RA3 instances the perfect candidate for your clinical quality repository. Additionally, the data sharing capability in Amazon Redshift keeps a single source for truth across the organization and removes the need for data silos. It’s tightly coupled with other AWS services, which allows you to take advantage of the AWS Cloud ecosystem and get the most out of your data with less effort.
Standardizing data modeling has two benefits: it allows you to reuse technical and organizational procedures (for example, ETL and project management), and you can readily merge data from diverse contexts without much complication. Because storage is separated from the computing, the Amazon Redshift RA3 instance retains the classic data lake feature of storing huge amounts of data. On the data side, to keep the data close to its raw form, a Data Vault model is the ideal solution to this problem.
Data Vault is a methodology to speed up the development of data warehouse initiatives and keep the data close to its sources. The Data Vault 2.0 data modeling standards are popular because they stress the business keys by hashing the keys across entities. This eliminates the need for strong relationships between entities and their linkages within the delivery of business processes. Data Vault makes it easy to integrate with versatile data sources for completely different use cases than it’s originally designed for, due to the following features:
- Entities can stand alone and be built on patterns, each with a well-defined purpose.
- Because the data represents the source system and delivers business value, data silos are eliminated.
- You can load data in parallel with the least number of dependencies.
- Historized data is kept at the coarsest level of granularity possible.
- You can implement flexible business rules independently of data loading. This reduces the time taken to load the data by 25%.
- You can add new data sources without affecting the current model.
The following diagram shows a simple clinical quality data repository with the Data Vault model with Amazon Redshift.

The following shows a simple clinical quality business Data Vault model using Amazon Redshift materialized views.

The Data Vault architecture is divided into four stages:
- Staging – A copy of the most recent modifications to data from the source systems is created. This layer doesn’t save history, and you can perform numerous alterations to the staged data while populating, such as data type changes or scaling, character set conversion, and the inclusion of metadata columns to enable subsequent processing.
- Raw vault – This stores a history of all data from numerous source systems. Except for putting the data into source system independent targets, no filters or business transformations happen here.
- Business vault – This is an optional offering that is frequently developed. It includes business computations and denormalizations with the goal of enhancing the speed and ease of access inside the consumption layer, known as the information mart layer.
- Data mart layer – This is where data is most typically accessible by users, such as reporting dashboards or extracts. You can build multiple marts from a single Data Vault integration layer, and the most frequent data modeling choice for these marts is Star/Kimball schemas.
The Amazon Redshift RA3 instance capabilities we discussed enable the development of highly performant and cost-effective Data Vault solutions. The staging and raw layers, for example, are populated in micro-batches by one Amazon Redshift cluster 24 hours a day. You can build the business Data Vault layer once a day and pause it to save costs when completed, and any number of consumer Amazon Redshift clusters can access the results.
The following diagram shows the complete architecture of the clinical quality Data Vault.
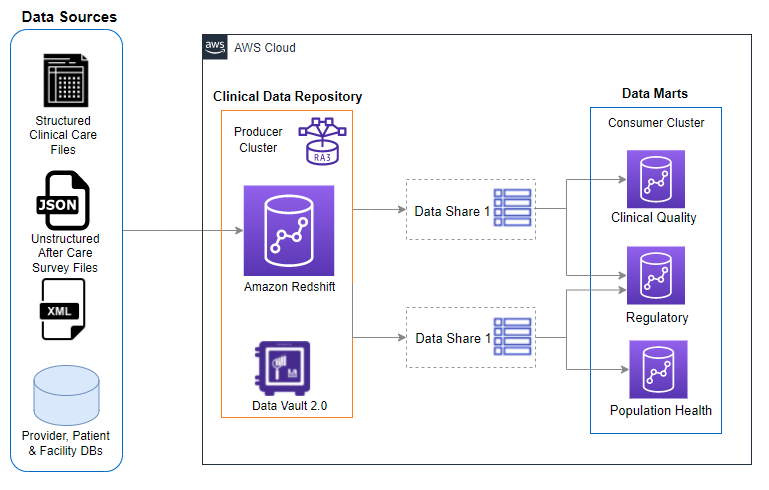
The architecture has the following components:
- Batched raw data is loaded into the staging database raw schema.
- The data quality validated structured data is delivered immediately to the staging database curated schema.
- Data from devices, EHR systems, and vendor medical systems are also sent directly into the Amazon Redshift staging database.
- The Data Vault 2.0 approach is used in the Amazon Redshift producer cluster to standardize data structure and assure data integrity.
- Materialized views make a business Data Vault.
- The Amazon Redshift SUPER data type allows you to store and query semi-structured data.
- Amazon Redshift data share capabilities securely exchange the Data Vault tables and views between departments.
- Support for streaming ingestion in Amazon Redshift eliminates the need to stage data in Amazon S3 before ingesting it into Amazon Redshift.
- Amazon Redshift allows you to offload the historical data to Amazon S3. Healthcare clinical quality tracking systems usually offload data older than 6–7 years old for archival.
- Amazon S3 and Amazon Redshift are HIPAA eligible.
Advantages of the Amazon Redshift clinical data repository
A clinical data repository in Amazon Redshift has the following benefits:
- Data Vault enables the preservation of data as raw in its native form.
- Amazon Redshift RA3 provides limitless storage, a real-time data feed, structured and semi-structured data, and more.
- The new streaming functionality and analytics capacity in Amazon Redshift provide near-real-time analysis without the need for extra services.
- Data quality is assured while maintaining data close to the business and source. You can reduce storage costs while maintaining data fidelity.
- It’s compatible with business applications and allows for easy adoption when merging or expanding a variety of businesses without complexity.
- The decoupled storage and compute option in Amazon Redshift allows for cost savings and offers ML capabilities within Amazon Redshift for quicker prediction, forecasting, and anomaly detection.
Conclusion
Data Vault is a one-of-a-kind database platform that promotes openness. It’s quick to adopt, infinitely configurable, and ready to overcome the most demanding data difficulties in current clinical quality metric tracking systems. Combined with the advantages of Amazon Redshift RA3 instances, Data Vault can outperform and deliver more value for cost and time.
To get started,
- Create Amazon Redshift RA3 instance for the primary “Clinical Data Repository” and the data marts.
- Build a Data vault schema for the raw vault an create materialized views for the business vault.
- Enable Amazon Redshift data share to share data between producer cluster and consumer cluster.
- Load the structed and unstructured data in to the producer cluster data vault for the business use.
About the Authors
Sarathi Balakrishnan is the Global Partner Solutions Architect, specializing in Data, Analytics and AI/ML at AWS. He works closely with AWS partner globally to build solutions and platforms on AWS to accelerate customers’ business outcomes with state-of-the-art cloud technologies and achieve more in their cloud explorations. He helps with solution architecture, technical guidance, and best practices to build cloud-native solutions. He joined AWS with over 20 years of large enterprise experience in agriculture, insurance, health care and life science, marketing and advertisement industries to develop and implement data and AI strategies.
Kasi Muthu is a Senior Partner Solutions Architect based in Houston, TX. He is a trusted advisor in Data, Analytics, AI/ML space. He also helps customers migrate their workloads to AWS with focus on scalability, resiliency, performance and sustainability. Outside of work, he enjoys spending time with his family and spending quite a bit of his free time on YouTube.
Enjoyed this article? Sign up for our newsletter to receive regular insights and stay connected.